本文将以命名实体识别(NER)任务为例子,来介绍如何在ElasticSearch中进行自然语言处理(NLP)。
ElasticSearch是一个流行的开源搜索和分析引擎,广泛用于日志和事件数据的存储、检索和分析,它的功能十分强大。近年来又引入了机器学习(Machine Learning)功能,允许用户它进行模型分析预测,包括自然语言处理(NLP)等。
本文将会以NLP中的命名实体识别(NER)任务为例,来展示如何在ElasticSearch中进行文本智能处理。
本文使用的NER模型为shibing624/bert4ner-base-chinese,其HuggingFace网址为:https://huggingface.co/shibing624/bert4ner-base-chinese。该模型可以识别中文文本中的时间、地点、人物、组织机构这四类实体,base模型为BERT.
本文主要使用Eland工具将NER模型部署在ElasticSearch中,并在ElasticSearch中进行文本处理。
准备工作
我们先使用Docker Compose来搭建一个简单的ElasticSearch和Kibana环境,使用的版本均为8.13.0,其中配置文件docker-compose.yml如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| version: "3.1"
services:
elasticsearch:
container_name: elasticsearch-8.13.0
image: elasticsearch:8.13.0
environment:
- "ES_JAVA_OPTS=-Xms4096m -Xmx4096m"
- "http.host=0.0.0.0"
- "node.name=elastic01"
- "cluster.name=cluster_elasticsearch"
- "discovery.type=single-node"
- "xpack.security.enabled=false"
ports:
- "9200:9200"
- "9300:9300"
volumes:
- ./data:/usr/share/elasticsearch/data
networks:
- elastic_net
kibana:
container_name: kibana-8.13.0
image: kibana:8.13.0
ports:
- "50076:5601"
environment:
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
depends_on:
- elasticsearch
networks:
- elastic_net
networks:
elastic_net:
driver: bridge
|
注意: 在Kibana界面的Stack Management中,需要开启Machine Learning,此时一般要license授权,但可试用一个月。如果不开启Machine Learning,则无法使用NLP模型。
模型部署
我们使用Elastic官方开源的Eland工具来部署uggingFace开源模型。
Eland是一个全新的 Python Elasticsearch 客户端和工具包,它提供了类似于 pandas 的 API,用于分析、ETL 和机器学习。

我们将使用如下的Docker命令来方便地将shibing624/bert4ner-base-chinese这个NER模型加载至ElasticSearch中:
1
2
3
4
5
6
| docker run -itd --rm docker.elastic.co/eland/eland \
eland_import_hub_model --url http://host:port \
--hub-model-id shibing624/bert4ner-base-chinese \
--task-type ner \
--start \
--clear-previous
|
其中url为ES服务在本地服务器上的网址。
运行上述服务后,Eland使用PyTorch进行模型加载、推理,版本为2.1.2, ElasticSeach版本为8.13.0,请特别留意这两个模块的版本。
注意:在部署模型时,因为模型加载需要大量内存,因此需要留意ES中的内存分配。该模型的内存占用约为1.1G。另外,在笔者的Mac电脑上,模型推理将会报错,因此建议最好使用Linux服务器。
此时,在Kibana -> Machine Learning -> Model Management中,可找到我们已经部署的模型,将这个模型开启Synchronized,不久后就能看到模型显示绿色的Deployed。
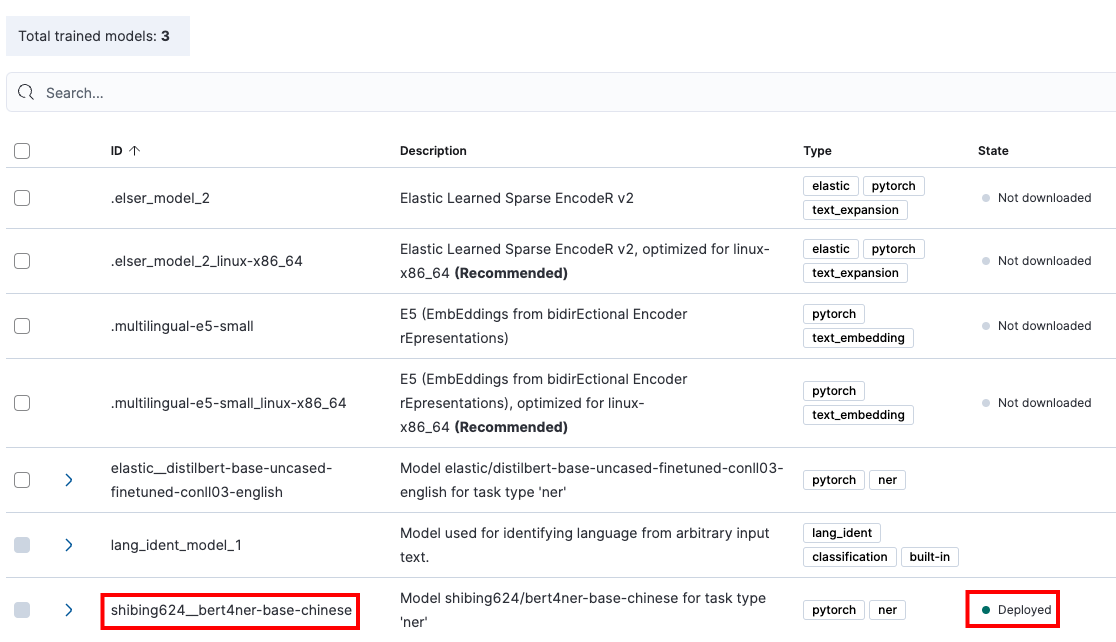
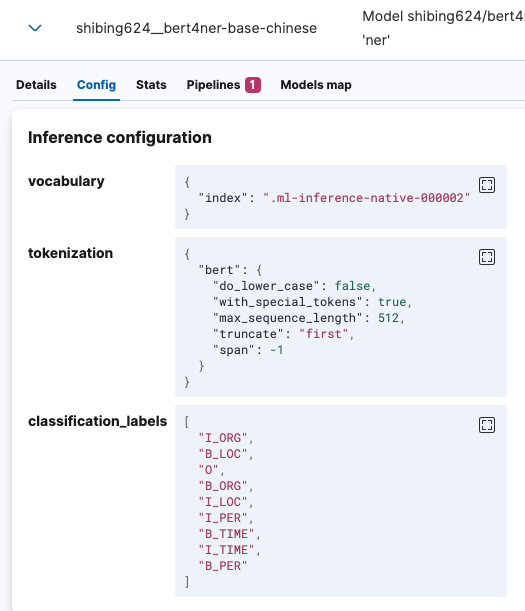
查看部署模型的详细信息,比如模型的Config,如下:
简单使用
在Trained Models页面,点击部署模型的Actions按钮,可以进行模型推理测试(Test model)。

在Dev Tools(开发者工具)页面,可以使用REST命令进行交互。
1
| GET _ml/trained_models/shibing624__bert4ner-base-chinese/_stats
|
其中shibing624__bert4ner-base-chinese为模型id(model id)。
1
2
3
4
5
6
7
8
| POST _ml/trained_models/shibing624__bert4ner-base-chinese/_infer
{
"docs": [
{
"text_field": "在台北的台湾大学地质系特聘教授吴逸民表示,这次地震让北台湾民众这么有感的主因是台北盆地地形所产生的加乘效果。"
}
]
}
|
预测结果为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| {
"inference_results": [
{
"predicted_value": "在[台北](LOC&台北)的[台湾大学地质系](ORG&台湾大学地质系)特聘教授[吴逸民](PER&吴逸民)表示,这次地震让[北台湾](LOC&北台湾)民众这么有感的主因是[台北盆地](LOC&台北盆地)地形所产生的加乘效果。",
"entities": [
{
"entity": "台北",
"class_name": "LOC",
"class_probability": 0.9979633671820971,
"start_pos": 1,
"end_pos": 3
},
{
"entity": "台湾大学地质系",
"class_name": "ORG",
"class_probability": 0.9907676215640316,
"start_pos": 4,
"end_pos": 11
},
{
"entity": "吴逸民",
"class_name": "PER",
"class_probability": 0.9998507299738062,
"start_pos": 15,
"end_pos": 18
},
{
"entity": "北台湾",
"class_name": "LOC",
"class_probability": 0.9056884399922297,
"start_pos": 26,
"end_pos": 29
},
{
"entity": "台北盆地",
"class_name": "LOC",
"class_probability": 0.8290892675823885,
"start_pos": 39,
"end_pos": 43
}
]
}
]
}
|
输入字段为text_field。predicted_value字段是注释文本格式的输入字符串,class_name是预测类别,而 class_probability则表示模型预测的置信水平。start_pos和end_pos 分别为已识别实体的开头字符和结尾字符在原文中的位置。
更多模型相关的API可参考: https://www.elastic.co/guide/en/elasticsearch/reference/current/ml-df-trained-models-apis.html .
文本处理
Ingest Pipeline介绍
我们使用Ingest Pipeline来进行数据预处理。
Ingest Pipeline 允许文档在被索引之前对数据进行预处理,将数据加工处理成我们需要的格式。例如,可以使用Ingest Pipeline添加或者删除字段,转换类型,解析内容等等。Pipeline 由一组处理器Processor 构成,每个处理器依次运行,对传入的文档进行特定的更改。Ingest Pipeline 和 Logstash 中的 filter 作用相似,并且更加轻量和易于调试。
我们构建的Pipeline(名称为chinese_ner)命令如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| PUT _ingest/pipeline/chinese_ner
{
"description": "Chinese NER pipeline",
"processors": [
{
"inference": {
"model_id": "shibing624__bert4ner-base-chinese",
"target_field": "ml.ner",
"field_map": {
"paragraph": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"if": "return ctx['ml']['ner'].containsKey('entities')",
"source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
|
在Stack Management -> Ingest Pipelines中可查看该pipeline的信息,如下图:

为简单验证该pipeline是否得到了想要的效果,可在Dev Tools页面对其进行测试:
1
2
3
4
5
6
7
8
9
10
11
| POST _ingest/pipeline/chinese_ner/_simulate
{
"docs": [
{
"_source": {
"paragraph": "王安石的另一位好友叫吴充。",
"line": 16
}
}
]
}
|
输出结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| {
"docs": [
{
"doc": {
"_index": "_index",
"_version": "-3",
"_id": "_id",
"_source": {
"paragraph": "王安石的另一位好友叫吴充。",
"line": 16,
"ml": {
"ner": {
"model_id": "shibing624__bert4ner-base-chinese",
"entities": [
{
"end_pos": 3,
"class_name": "PER",
"class_probability": 0.999796460282346,
"start_pos": 0,
"entity": "王安石"
},
{
"end_pos": 12,
"class_name": "PER",
"class_probability": 0.9997412197983617,
"start_pos": 10,
"entity": "吴充"
}
],
"predicted_value": "[王安石](PER&王安石)的另一位好友叫[吴充](PER&吴充)。"
}
},
"tags": {
"PER": [
"王安石",
"吴充"
]
}
},
"_ingest": {
"timestamp": "2024-04-04T12:36:23.397525241Z"
}
}
}
]
}
|
提取文本实体,展示词云图
让我们在之前的基础上,进行简单实战:展示崔铭写的《王安石传》第五章第六节内容中的实体词云图。
我们利用Kibana的文件上传功能,上传wanganshi.json,共75条数据(每行为json字符串,包含line和paragraph字段),创建的index为ner_demo,mapping为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| {
"ner_demo": {
"mappings": {
"_meta": {
"created_by": "file-data-visualizer"
},
"properties": {
"line": {
"type": "long"
},
"paragraph": {
"type": "text"
}
}
}
}
}
|
使用上述创建的Ingest Pipeline对paragraph字段进行数据预处理,提取实体,并更新数据。
1
| POST ner_demo/_update_by_query?pipeline=chinese_ner
|
数据预处理完毕后,使用Kibana的Visualize Library页面创建实体词云图,效果如下:


总结
本文主要介绍了如何使用Eland工具在ElasticSearch部署命名实体识别模型,并结合具体的文本例子详细给出了文本智能处理的方法。
事实上,对于我们在ElasticSearch部署的模型,还可以进行调整部署,增强其推理性能。
本文给出的代码已经开源至Github,网址为: https://github.com/percent4/ES_Learning .
参考网址
- 如何部署自然语言处理 (NLP):命名实体识别 (NER) 示例: https://www.elastic.co/cn/blog/how-to-deploy-nlp-named-entity-recognition-ner-example
- Elasticsearch 8 : Named Entity Recognition (NER) using Inference Ingest Pipeline: https://medium.com/@psajan106/elasticsearch-8-named-entity-recognition-ner-using-inference-ingest-pipeline-8e7bd566c5e8
- 【ES三周年】使用 Ingest Pipeline 在 Elasticsearch 中对数据进行预处理: https://cloud.tencent.com/developer/article/2217871
- shibing624/bert4ner-base-chinese: https://huggingface.co/shibing624/bert4ner-base-chinese
- Eland Python Client: https://www.elastic.co/guide/en/elasticsearch/client/eland/current/index.html
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
