from token_counter.token_count import TokenCounter
""" import tiktoken
from typing importList, Union
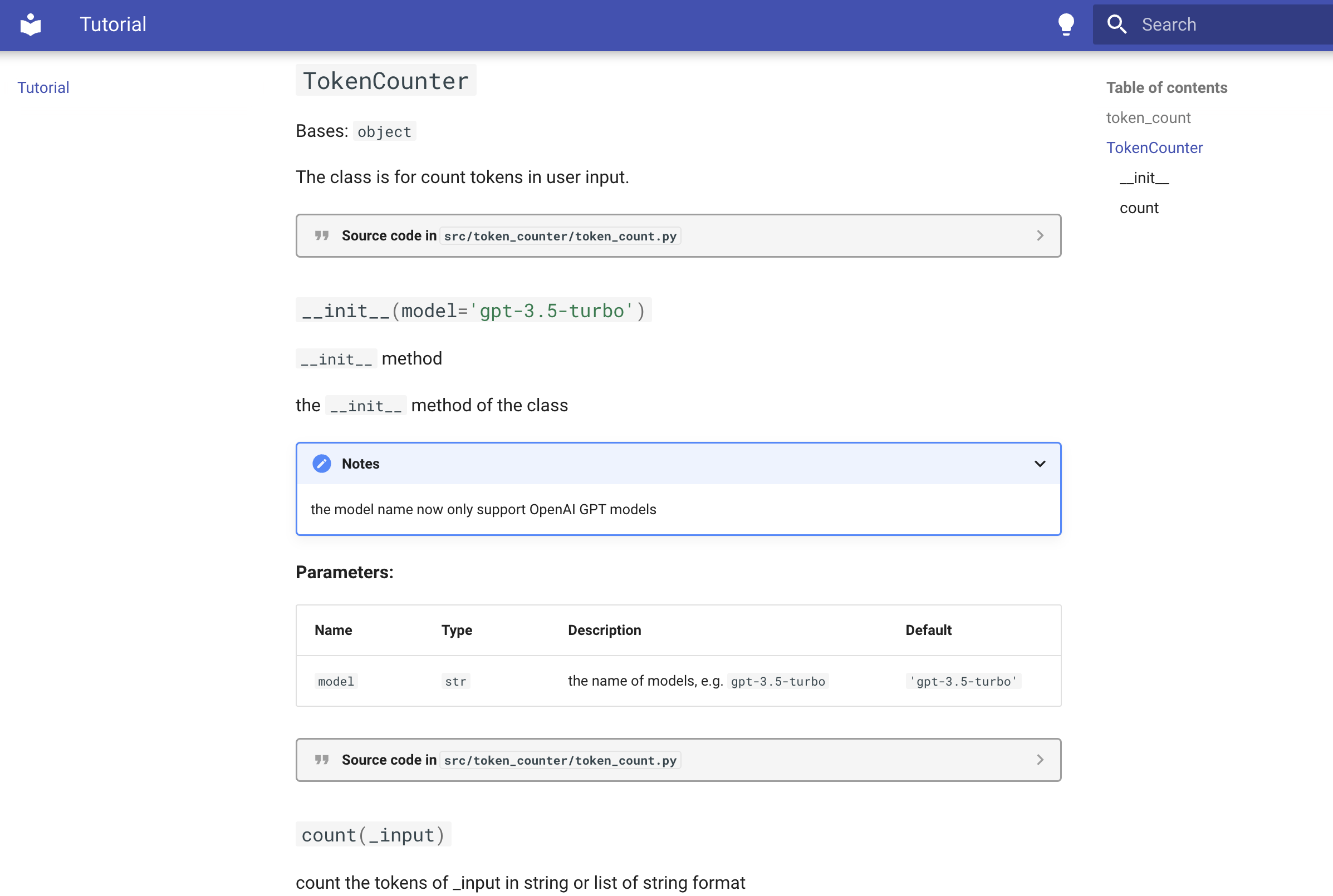
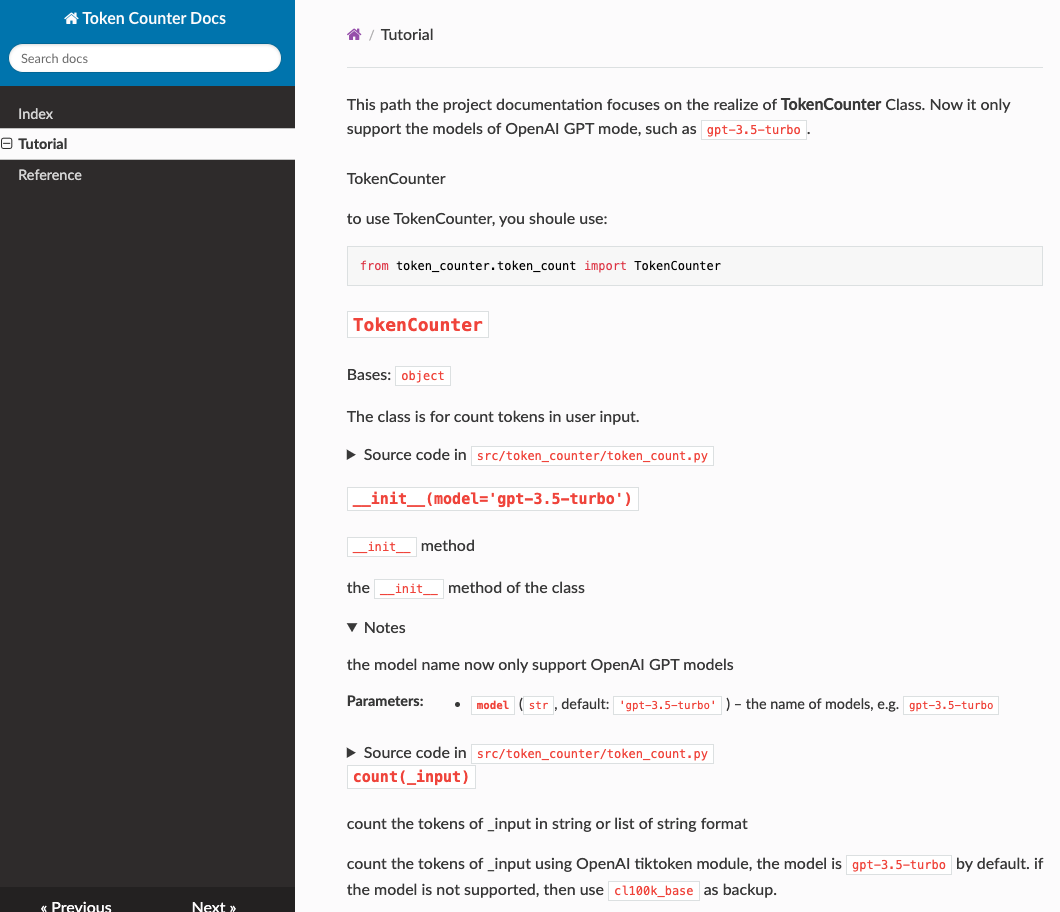
classTokenCounter(object): """The class is for count tokens in user input. """ def__init__(self, model: str = "gpt-3.5-turbo"): """`__init__` method
the `__init__` method of the class
Notes: the model name now only support OpenAI GPT models
Args: model: the name of models, e.g. `gpt-3.5-turbo` """ self.model = model
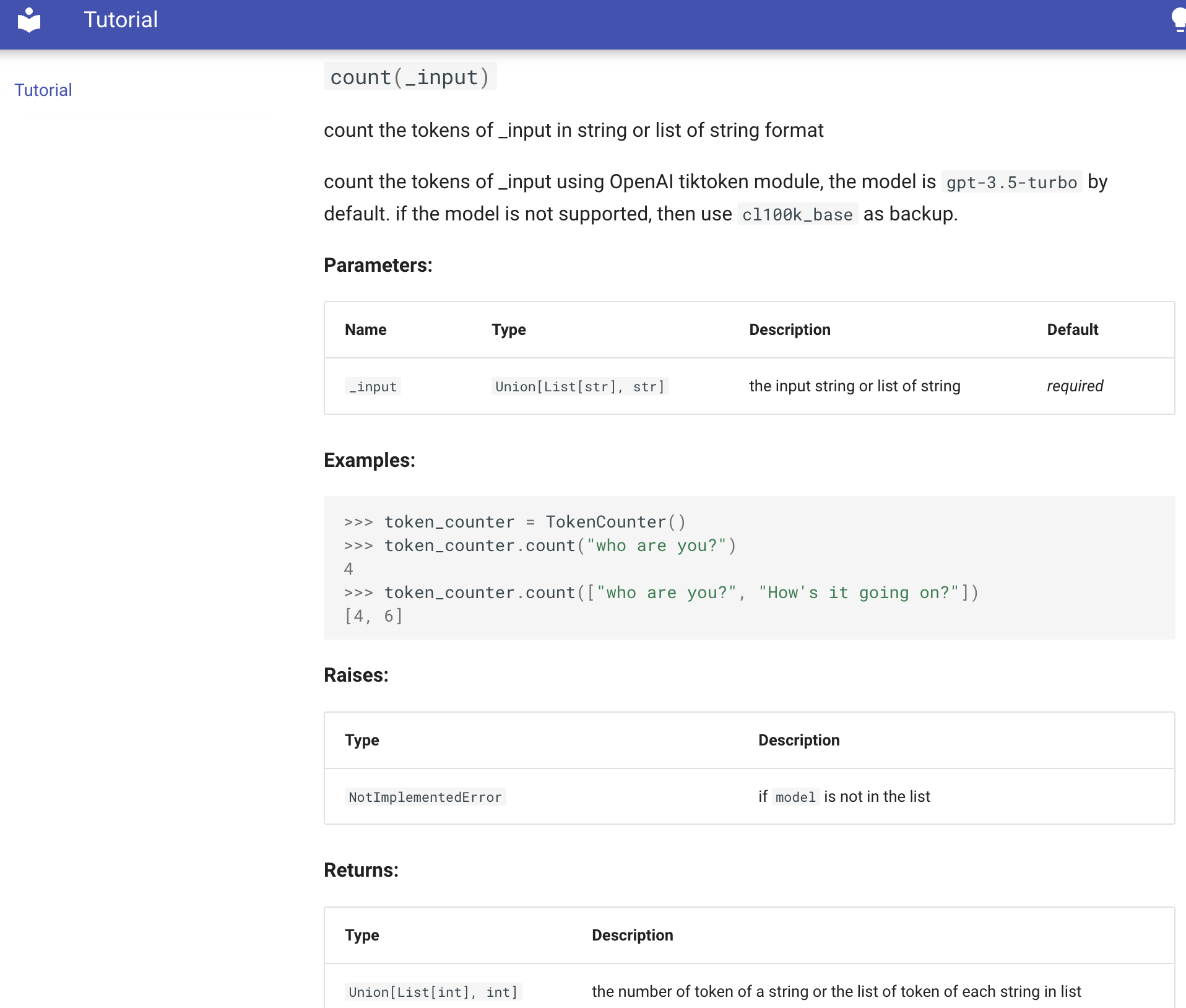
defcount(self, _input: Union[List[str], str]) -> Union[List[int], int]: """count the tokens of _input in string or list of string format
count the tokens of _input using OpenAI tiktoken module, the model is `gpt-3.5-turbo` by default. if the model is not supported, then use `cl100k_base` as backup.
Args: _input: the input string or list of string
Examples: >>> token_counter = TokenCounter() >>> token_counter.count("who are you?") 4 >>> token_counter.count(["who are you?", "How's it going on?"]) [4, 6]
Raises: NotImplementedError: if `model` is not in the list
Returns: the number of token of a string or the list of token of each string in list """ try: encoding = tiktoken.encoding_for_model(self.model) except KeyError: print("Warning: model not found. Using cl100k_base encoding.") encoding = tiktoken.get_encoding("cl100k_base")
ifisinstance(_input, list): token_count_list = [] for text in _input: token_count_list.append(len(encoding.encode(text))) return token_count_list elifisinstance(_input, str): returnlen(encoding.encode(_input)) else: raise NotImplementedError(f"not support data type for {type(_input)}, please use str or List[str].")
Trying: token_counter = TokenCounter() Expecting nothing ok Trying: token_counter.count("who are you?") Expecting: 4 ok Trying: token_counter.count(["who are you?", "How's it going on?"]) Expecting: [4, 6] ok 3 items had no tests: token_count token_count.TokenCounter token_count.TokenCounter.__init__ 1 items passed all tests: 3 tests in token_count.TokenCounter.count 3 tests in 4 items. 3 passed and 0 failed. Test passed.
项目文档生成
切换正题。我们运行命令mkdocs new .后,就会在当前目录下生成docs文件夹和mkdocs.yml配置文件。
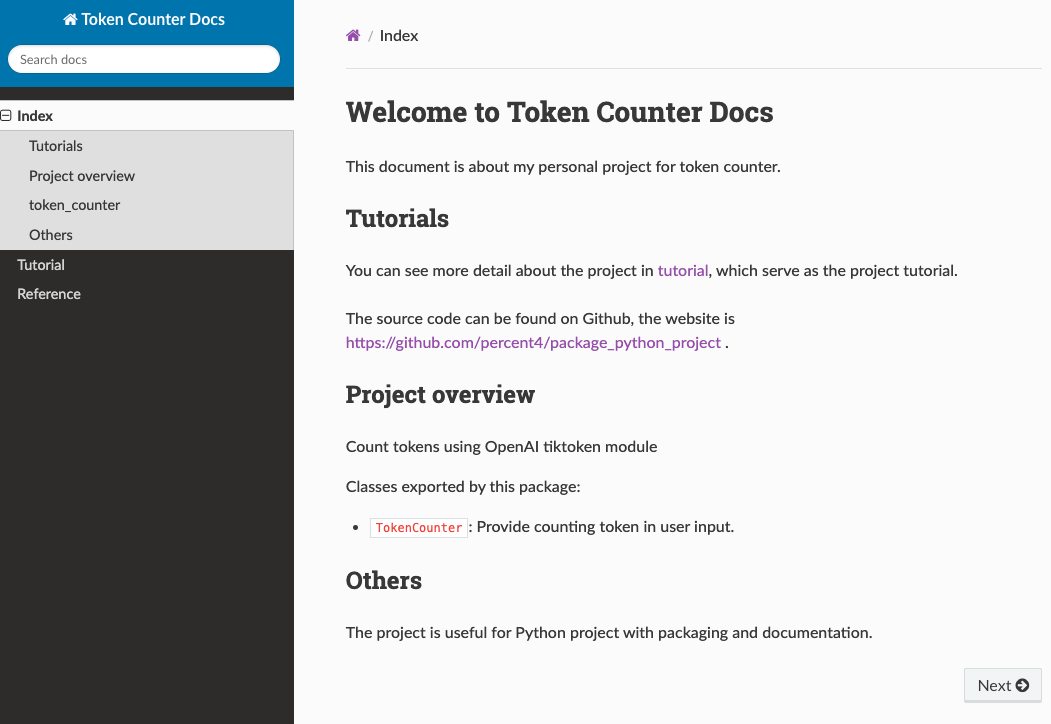
This document is about my personal project for token counter.
## Tutorials
You can see more detail about the project in [tutorial](tutorials.md), which serve as the project tutorial.
The source code can be found on Github, the website is [https://github.com/percent4/package_python_project](https://github.com/percent4/package_python_project) .
## Project overview
::: src.token_counter
## Others
The project is useful for Python project with packaging and documentation.
This path the project documentation focuses on the realize of **TokenCounter** Class. Now it only support the models of OpenAI GPT mode, such as `gpt-3.5-turbo`.