本文将介绍三种常用的向量数据库:faiss,
Milvus和Qdrant,并给出一个具体的使用例子。
向量数据库(Vector Database)是一种专门用于存储、管理、查询、检索向量的数据库,主要应用于人工智能、机器学习、数据挖掘等领域。
在向量数据库中,数据以向量的形式进行存储和处理,需要将原始的非向量型数据转化为向量表示(比如文本使用Embedding技术获得其表征向量)。
这种数据库能够高效地进行相似性搜索,快速找到最相似的向量,适用于人脸识别、图像搜索、推荐系统等需要相似性匹配的应用。
去年大模型的大火也带动了向量数据库的迅速发展,使得向量数据库成为热门方向之一,成为AI领域不可或缺的一项重要工具。
本文将介绍常见的三种向量数据库,并结合具体的样例文本给出它们在文本相似性搜索方面的应用。这三个向量数据库分别为:
获取文本Embedding向量
我们使用的样例文本来源于百度百科的“中国载人登月工程”词条,将其本文切分为句子,过滤其中的纯数字的句子,保存为dengyue.txt文件。
对于上述文本,使用OpenAI的embedding模型text-embedding-ada-002来获取句子的表征向量(向量维度为1536,L2范数为1,即单位向量),并保存为numpy模块的npz文件,用于离线存储,避免每次使用时都需要加载。
示例的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import osimport reimport jsonfrom typing import List from dotenv import load_dotenvimport requestsimport numpy as npfrom sentencex import segmentdef get_embedding (texts: List [str ] ):"https://api.openai.com/v1/embeddings" "model" : "text-embedding-ada-002" ,"input" : texts,"encoding_format" : "float" 'Content-Type' : 'application/json' ,'Authorization' : f'Bearer {os.getenv("OPENAI_API_KEY" )} ' "POST" , url, headers=headers, data=payload)"embedding" ] for _ in response.json()['data' ]]return embeddingdef read_file ():with open ("dengyue.txt" , "r" , encoding="utf-8" ) as f:for _ in f.readlines() if _.strip()]for line in content:list (segment(language="zh" , text=line))for sent in sents: if sent and not re.match (r'\[\d+\]' , sent):return file_sentencesif __name__ == '__main__' :'text_embedding.npz' , sentences_embeddings)with open ('text.json' , 'w' ) as f:for i, sentence in enumerate (sentences)}, indent=4 , ensure_ascii=False ))
运行上述文件,则会得到句子的表征向量文件text_embedding.npz,使用np.load()方法即可加载这些向量。
faiss
faiss 全称为Facebook AI Similarity
Search,是Facebook开源的一个用于高效相似性搜索和密集向量聚类的库,使用C++编写,提供python接口,对10亿量级的索引可以做到毫秒级检索的性能。它包含的算法可以搜索任意大小的向量集,甚至可能无法容纳在
RAM 中的向量集。它还包含用于评估和参数调整的支持代码。
faiss模块同时支持CPU和GPU.
faiss支持的索引(Index)类型如下图:
文本相似性搜索 :获取与查询文本(query)相似度最接近的k个语料文本:
获取query的表征向量(同一个Embedding模型)
借助faiss查询出与该query向量相似度最接近的k个向量
获取这k个向量对应的文本
示例Python代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import jsonimport numpy as npfrom faiss import IndexFlatIPfrom get_text_embedding import get_embeddingwith open ('text.json' , 'r' ) as f:list (json.loads(f.read()).values())1536 )"text_embedding.npz" )['arr_0' ]"阿波罗登月计划" "神舟五号 杨利伟" 3 )print (f"query: {query} " )print ("recall result: " )for i, sent_index in enumerate (doc_indices.tolist()[0 ]):print (f"rank: {i} , similarity: {distances.tolist()[0 ][i]} , text: {sentences[sent_index]} " )
输入query为阿波罗登月计划 ,最接近的3个语料文本为:
query: 阿波罗登月计划
recall result:
rank: 0, similarity: 0.855633020401001, text: 二十世纪六、七十年代,美国人凭借“阿波罗”计划率先登上月球。
rank: 1, similarity: 0.8497034907341003, text: 初步方案是:采用两枚运载火箭分别将月面着陆器和载人飞船送至环月轨道在轨交会对接,航天员从飞船进入月面着陆器。
rank: 2, similarity: 0.8401131629943848, text: 欧阳自远表示,对于载人登月工程国家还没有公布一个明确的时间表,但已经在做积极的论证和准备。输入query为神舟五号
杨利伟 ,最接近的3个语料文本为:
query: 神舟五号 杨利伟
recall result:
rank: 0, similarity: 0.8733900785446167, text: 叶培建表示,中国载人航天计划共有“三步走”,第一步是从“神舟一号”走到“神舟七号”,前4个载人飞船是无人的,“神五”时杨利伟上天,实现中国人第一次进入太空的梦想,虽然比“太空旅行第一人”尤里·阿列克谢耶维奇·加加林晚了几十年,但两个不是一个数量级。
rank: 1, similarity: 0.8618367910385132, text: 加加林只飞了一个小时,是伞降;杨利伟飞了一天,是软着陆,返回舱已达到“容3个人7天往返”标准。
rank: 2, similarity: 0.8449346423149109, text: 加加林落地偏差达400公里;杨利伟落地时,落在中国内蒙古,当时设计“100乘以90公里着陆”都算准确着陆,但最终落地偏差只有10公里,后来“神六”、“神七”落地误差只有1公里,3条飞船实现了第一阶段的全部任务。输入query为北京航天城 ,最接近的3个语料文本为:
query: 北京航天城
recall result:
rank: 0, similarity: 0.8499420881271362, text: 在北京航天城当天举行的“李锦记航天奖学金”颁发仪式上,戚发轫介绍,根据中国的规划,2014年左右在深空探测领域,将把十几吨的航天器送到地球轨道,2020年前将建成自己的空间站。
rank: 1, similarity: 0.8408806920051575, text: 5月29日上午,神舟十六号载人飞行任务新闻发布会在酒泉卫星发射中心举行。
rank: 2, similarity: 0.8388772010803223, text: 戚发轫还介绍,中国将建成全球的自主北斗导航系统,中国的人、车、船、飞机在世界任何地方都可靠自己的卫星来导航定位。Milvus
Milvus是在2019年创建的,其唯一目标是存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量。
作为一个专门设计用于处理输入向量查询的数据库,它能够处理万亿级别的向量索引。与现有的关系型数据库主要处理遵循预定义模式的结构化数据不同,Milvus从底层设计用于处理从非结构化数据转换而来的嵌入向量。
我们使用Docker启动Milvus服务,并进行文本相似性搜索。示例Python代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import jsonimport timeimport numpy as npfrom pymilvus import MilvusClient, FieldSchema, CollectionSchema, DataType, Collectionfrom get_text_embedding import get_embeddingwith open ('text.json' , 'r' ) as f:list (json.loads(f.read()).values())"text_embedding.npz" )['arr_0' ]"dengyue" "http://localhost:19530" , db_name="default" )print ("exist collections: " , collections)if collection_name not in collections:"id" , dtype=DataType.INT64, is_primary=True , auto_id=False ),"text" , dtype=DataType.VARCHAR, max_length=1000 ),"embedding" , dtype=DataType.FLOAT_VECTOR, dim=1536 )"text search demo" )"embedding" ,"IVF_FLAT" ,"IP" ,"nlist" : 128 }3 )print ("load state: " , res)"id" : i + 1 ,"text" : sentences[i],"embedding" : sentences_embeddings[i].tolist()}for i in range (len (sentences))"阿波罗登月计划" print (query_embedding[0 ])3 ,"metric_type" : "IP" , "params" : {}},'text' ]4 , ensure_ascii=False )print (result)
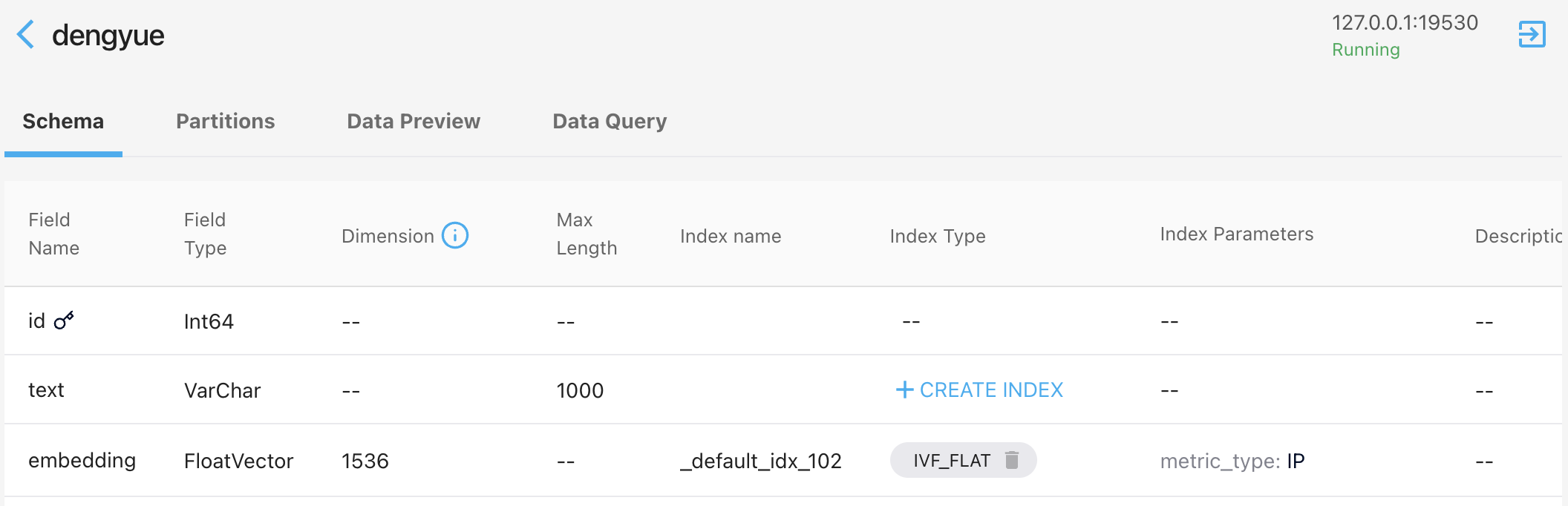
其中创建的Milvus
collection为dengyue,其schema如下(可视化工具采用Attu):
collection schema
运行上述程序,得到的文本相似度搜索结果同上述faiss。
Qdrant
Qdrant是一个用 Rust
编写的开源矢量数据库和矢量相似性搜索引擎,旨在利用先进的高性能矢量相似性搜索技术为下一代人工智能应用赋能。它的主要功能包括多语言支持(可实现各种数据类型的通用性)和适用于各种应用的过滤器。
Qdrant对近似近邻搜索的HNSW算法进行了定制修改,通过保持精确的结果,确保了最先进的搜索能力,从而实现了速度和精确度的双赢。此外,它还支持与向量相关的额外有效载荷,允许根据有效载荷值过滤结果。Qdrant
支持丰富的数据类型和查询条件,包括字符串匹配、数值范围和地理位置,为数据管理提供了多功能性。
Qdrant服务的启动方式如下:
本地模式,不需要服务器(离线db文件或内存)
本地服务器部署
Qdrant云
以本地模式(离线db文件)启动Qdrant服务,进行文本相似度搜索。示例Python代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import jsonimport osimport numpy as npfrom qdrant_client import QdrantClientfrom qdrant_client.http.models import Distance, VectorParamsfrom qdrant_client.http.models import PointStructfrom get_text_embedding import get_embedding"qdrant_db" "dengyue" if not os.path.exists(f"./{db_dir} /collection/{collect_name} " ):with open ('text.json' , 'r' ) as f:list (json.loads(f.read()).values())'text_embedding.npz' )1536 , distance=Distance.COSINE),True ,id =i + 1 ,'arr_0' ][i].tolist(),"text" : sentences}) for i,in enumerate (sentences)])print (operation_info)"北京航天城" 0 ]3 for search_item in search_result:print (search_item)
启动上述程序,会在本地同级目录下生成qdrant_db/collection/dengyue/storage.sqlite文件,表明该服务使用sqlite作为后端数据库。
运行上述程序,得到的文本相似度搜索结果同上述faiss。
Qdrant还支持本地Docker启动,启动命令为:
1 docker run -itd -p 6333:6333 -p 6334:6334 -v $(pwd )/qdrant_storage:/qdrant/storage:z qdrant/qdrant
此时,连接Qdrant的Python代码改为:
1 client = QdrantClient("localhost" , port=6333 )
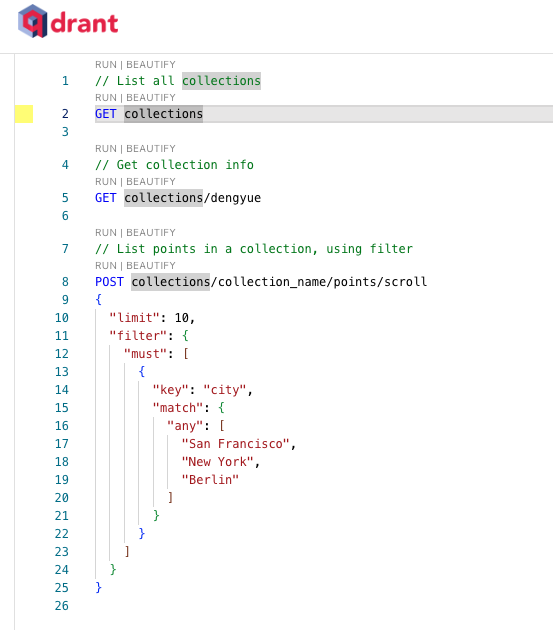
与此同时,该服务还提供了WebUI,支持在浏览器端进行操作,并提供了RESTful风格的Console界面。
Qdrant界面,查看collections
运行命令GET collections,结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "result" : { "collections" : [ { "name" : "test_collection" } , { "name" : "dengyue" } ] } , "status" : "ok" , "time" : 0.000011666 }
RESTful风格的Console界面
总结
本文简单介绍了三种常见的向量数据库:faiss, Milvus,
Qdrant,每种向量数据库都有其利弊。同时,结合一个具体的应用案例:文本相似性搜索,来分别展示这三种向量数据库的使用方法。
本文是笔者系统学习向量数据库的第一篇文章,后续将持续更新,欢迎大家关注~
欢迎关注我的公众号NLP奇幻之旅 ,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅 ”,笔者正在努力构建自己的技术社区。