迈向智能决策:蒙特卡洛树搜索(MCTS)的探索之路
本文将会介绍蒙特卡洛树搜索(MCTS)的基础概念、算法原理以及如何使用MCTS实现TicTacToe小游戏。
初始MCTS
蒙特卡洛树搜索(Monte Carlo Tree Search,简称
MCTS)是一种用于决策过程中的搜索算法,它通过随机采样来估计某一决策的潜在结果。MCTS
最初应用于游戏领域,但现在也被广泛应用于其他需要决策搜索的场景,如机器人规划、人工智能和控制系统等。
MCTS 的优势:
- 无需完整的游戏模型:MCTS 不需要了解完整的游戏状态空间,适用于那些状态空间巨大且难以完全探索的问题。
- 平衡探索与利用:通过 UCB 等策略,MCTS 可以在探索新的决策路径和利用当前已知的信息之间取得平衡。
- 渐进式优化:随着模拟次数的增加,MCTS 的决策结果会逐渐趋向最优。
MCTS 的使用场景如下:
- 游戏领域:MCTS
在棋类游戏(如围棋、国际象棋等)中表现优异。例如,Google DeepMind 的
AlphaGo就使用了蒙特卡洛树搜索来进行决策,尤其是在围棋这种状态空间极其庞大的游戏中,MCTS 扮演了至关重要的角色。 - 强化学习:在强化学习中,MCTS 可以用来寻找策略函数的最优解,通过在复杂环境中进行多次模拟,帮助代理智能体学习如何在未知环境中做出更好的决策。
- 路径规划:在机器人路径规划和自动驾驶领域,MCTS 可以用于寻找最优路径,通过不断模拟不同的路径选择,来实现最合适的路径规划。
- 决策支持系统:在许多复杂的决策支持系统中,MCTS 可用于多目标优化,通过模拟各种决策结果,帮助用户找到最合适的解决方案。
- 优化问题:MCTS 也可以用于各种组合优化问题,尤其是当问题的解空间庞大时,可以通过逐步模拟和调整来找到最优解。
MCTS原理
MCTS 的基本思想是利用蒙特卡洛方法和树结构的结合,在游戏或其他决策过程中,通过反复的模拟和计算,来找到最优的决策。
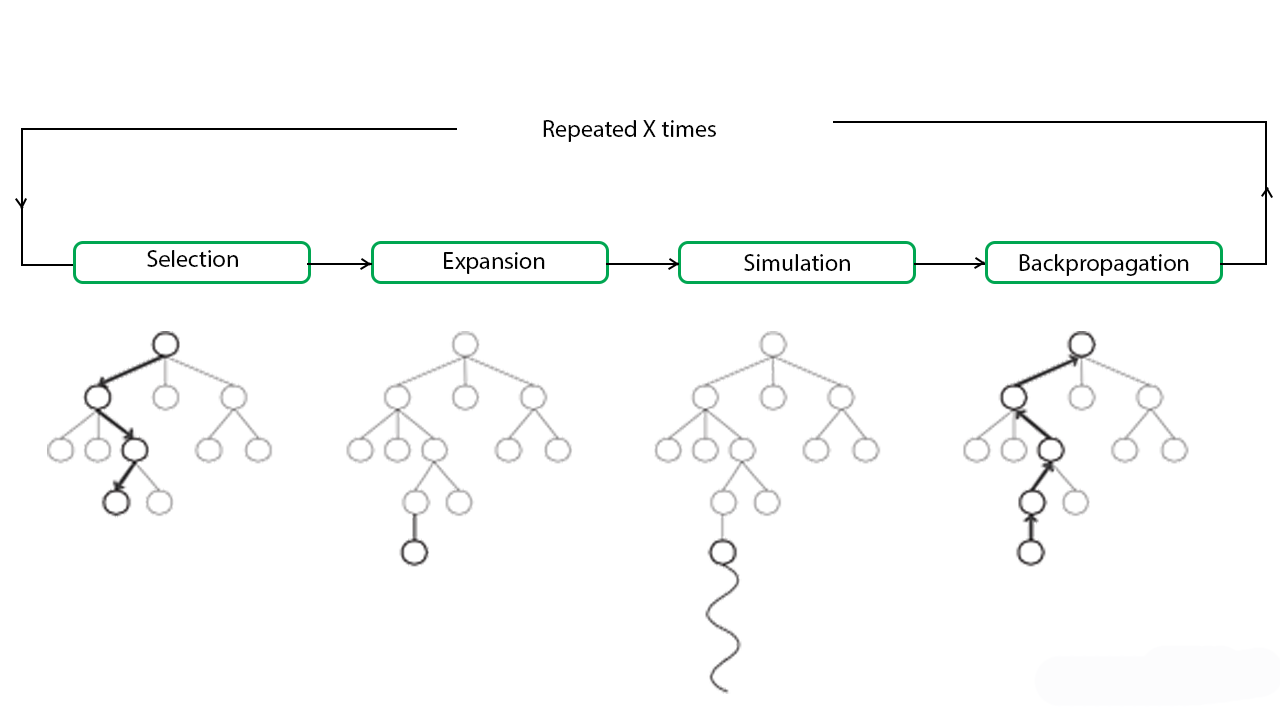
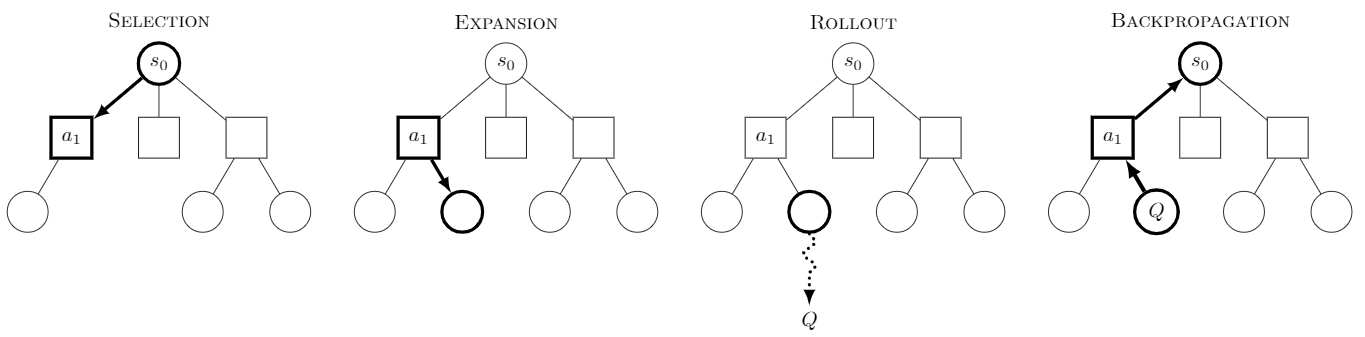
MCTS 算法通常由以下四个步骤组成:
选择(Selection)
从当前树的根节点出发,沿着子节点逐层选择一个节点,直到到达一个未完全展开的节点或达到最大模拟深度为止。 在这个过程中,选择最有可能导致最佳结果的节点,通常使用的是 UCB(上置信区间)策略。
扩展(Expansion)
如果到达的节点不是终局节点(即没有子节点),则展开这个节点,生成一个或多个子节点。
模拟(Simulation)
从扩展后的节点开始,进行一系列随机模拟,直到达到游戏的终局。模拟过程中的策略通常是随机的,可以是纯粹的随机选择。
回溯(Backpropagation)
模拟结束后,将模拟结果(如胜负)回溯到树的每个节点。每个节点更新自己的统计数据,记录该节点的胜率或平均奖励。
这个过程会不断重复,逐步扩展树并优化决策结果。最终,选择拥有最高胜率的子节点作为当前的决策。
使用MCTS实现TicTacToe游戏
Tic-Tac-Toe(井字游戏)是一款由两名玩家在 3x3 网格上交替标记 “X” 或 “O” 的简单游戏,目标是先在任意一行、列或对角线上形成连续的三个符号。玩家轮流选择空格并放置符号,若某玩家形成三连线,则获胜;若所有格子填满且无三连线,则游戏为平局。
游戏示意图如下:

下面,我们将会使用Python实现TicTacToe游戏,博弈的双方为AI和玩家,玩家先走,AI采用MCTS思考策略,然后选择下棋的位置。
首先我们先实现MCTS类,Python代码(mcts.py)如下:
1 | |
再使用MCTS算法实现TicTacToe游戏,如下:
1 | |
运行该脚本,样例输出结果如下:
1 | |
注意:如果是玩家先走,AI采用MCTS算法后走,则最多是平局,如果玩家不小心走错,那么AI还会取胜!这背后体现了MCTS算法的强大!这是多么有意思的现象啊!
TicTacToe游戏可视化版本
下面,我们来实现TicTacToe游戏的可视化版本,Python代码如下:
1 | |
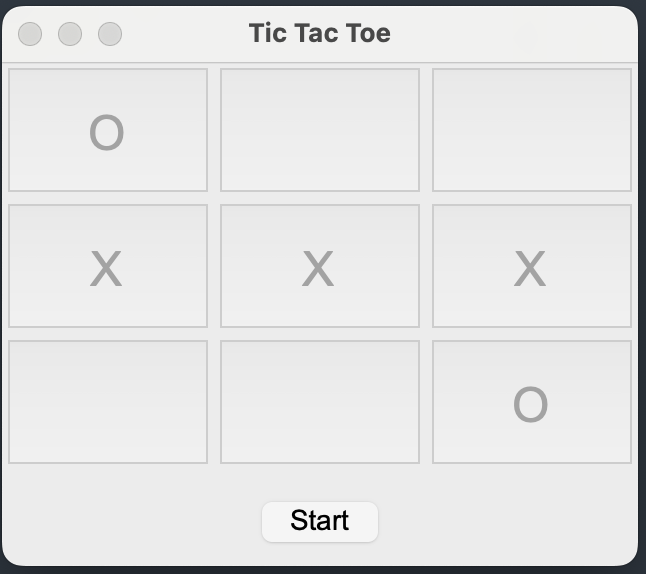
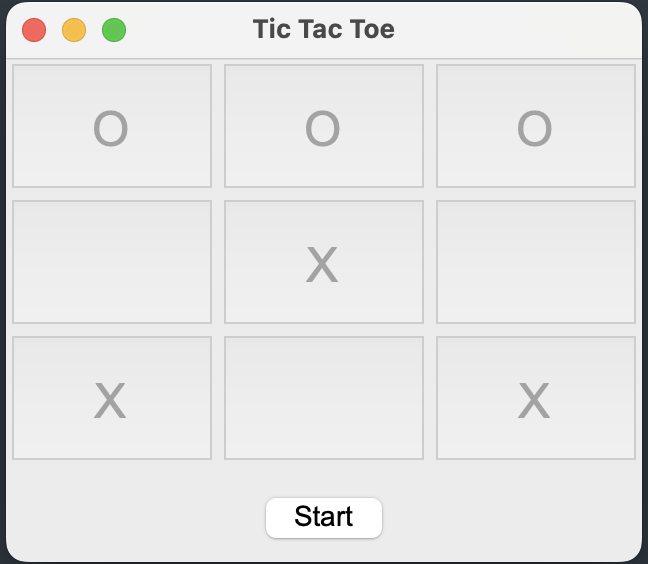
在上述代码的computer_move函数中,AI(符号为O)如果采用random_move(随机下棋)的算法,那么玩家(X)是有可能取胜的,如下图:
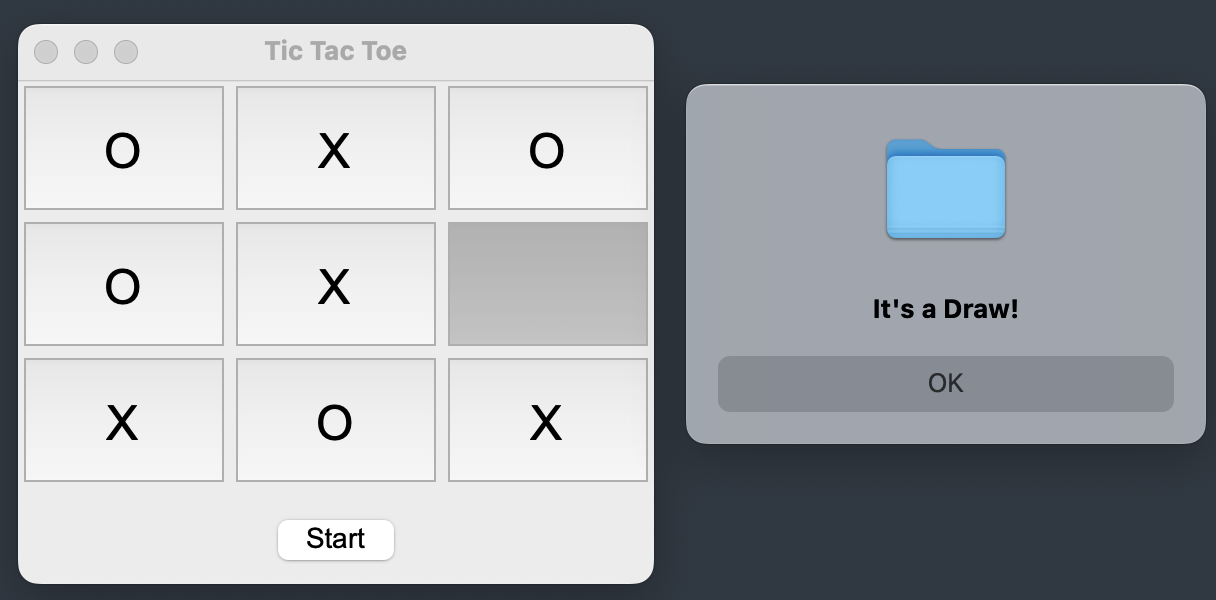
AI如果采用MCTS算法,那么玩家(X)最多是平局,甚至一不小心还会输掉比赛!
总结
本文作为MCTS入门的第一篇文章,主要介绍了MCTS算法的基本概念和原理,以及如何使用MCTS算法实现TicTacToe游戏,展示了MCTS在博弈小游戏中的强大之处。
本文中的代码已开源至Github,网址为:https://github.com/percent4/mcts_learning。
后续笔者将会进入强化学习(Reinforcement learning, RL)领域,去探索强化学习(RL)在大模型(LLM)中的使用,同时也会继续关注MCTS算法。欢迎关注~
参考文献
- Monte Carlo tree search: https://en.wikipedia.org/wiki/Monte_Carlo_tree_search
- Monte Carlo Tree Search: https://www.stephendiehl.com/posts/mtcs/