ELK简介
什么是ELK?
ELK是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称(后来出现的filebeat属于beats家族中的一员,可以用来替代logstash的数据收集功能,比较轻量级),也被称为Elastic Stack。
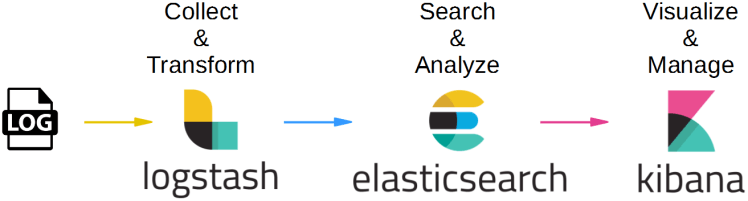 ELK架构简图
ELK架构简图
Filebeat
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或
Logstash进行索引。Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
Logstash
Logstash是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。Logstash能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用Grok从非结构化数据中派生出结构,从IP地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
ElasticSearch
Elasticsearch是Elastic
Stack核心的分布式搜索和分析引擎,是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。Elasticsearch为所有类型的数据提供近乎实时的搜索和分析。无论您是结构化文本还是非结构化文本,数字数据或地理空间数据,Elasticsearch都能以支持快速搜索的方式有效地对其进行存储和索引。
Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。并且可以为
Logstash 和 ElasticSearch 提供的日志分析友好的 Web
界面,可以汇总、分析和搜索重要数据日志。还可以让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。
Logstash入门
使用Docker-Compose启动Logstash服务,其中docker-compose.yml文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| version: "3.1"
services:
logstash:
container_name: logstash-7.17.0
image: docker.elastic.co/logstash/logstash:7.17.0
volumes:
- ./logstash/data:/usr/share/logstash/data
- ./logstash/pipeline:/usr/share/logstash/pipeline
networks:
- elk_net
networks:
elk_net:
driver: bridge
|
示例配置1(标准输入、输出)
每隔10秒输出字符串:Hello from Logstash!
1
2
3
4
5
6
7
8
9
10
11
| input {
heartbeat {
interval => 10
message => 'Hello from Logstash!'
}
}
output {
stdout {
codec => rubydebug
}
}
|
示例配置2(读取文件)
读取文件内容(文件的最后一行将不会读取),示例文件为test.log
1
2
3
4
| hello world!
From Shanghai To Beijing
this is a log for test in logstash!
|
配置文件如下:
1
2
3
4
5
6
7
8
9
10
11
| input {
file {
path => "/usr/share/logstash/data/test.log"
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug
}
}
|
读取结果如下(顺序已打乱):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| logstash-7.17.0 | {
logstash-7.17.0 | "message" => "hello world!",
logstash-7.17.0 | "@timestamp" => 2023-12-23T08:43:22.836Z,
logstash-7.17.0 | "host" => "333e14d2874a",
logstash-7.17.0 | "path" => "/usr/share/logstash/data/test.log",
logstash-7.17.0 | "@version" => "1"
logstash-7.17.0 | }
logstash-7.17.0 | {
logstash-7.17.0 | "message" => "this is a log for test in logstash!",
logstash-7.17.0 | "@timestamp" => 2023-12-23T08:43:22.843Z,
logstash-7.17.0 | "host" => "333e14d2874a",
logstash-7.17.0 | "path" => "/usr/share/logstash/data/test.log",
logstash-7.17.0 | "@version" => "1"
logstash-7.17.0 | }
logstash-7.17.0 | {
logstash-7.17.0 | "message" => "From Shanghai To Beijing",
logstash-7.17.0 | "@timestamp" => 2023-12-23T08:43:22.842Z,
logstash-7.17.0 | "host" => "333e14d2874a",
logstash-7.17.0 | "path" => "/usr/share/logstash/data/test.log",
logstash-7.17.0 | "@version" => "1"
logstash-7.17.0 | }
|
示例配置3(Grok插件)
Grok为正则表达式,Logstash(v4.4.3)已内置120种表达式,参考网址为:https://github.com/logstash-plugins/logstash-patterns-core/tree/main/patterns.
读取Nginx日志文件,并使用Grok进行过滤。Nginx文件示例如下:
1
2
| 112.195.209.90 - - [20/Feb/2018:12:12:14 +0800] "GET / HTTP/1.1" 200 190 "-" "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36" "-"
|
配置文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| input {
file {
path => "/usr/share/logstash/data/test.log"
start_position => "beginning"
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
}
output {
stdout {
codec => rubydebug
}
}
|
解析结果为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| logstash-7.17.0 | {
logstash-7.17.0 | "@version" => "1",
logstash-7.17.0 | "message" => "112.195.209.90 - - [20/Feb/2018:12:12:14 +0800] \"GET / HTTP/1.1\" 200 190 \"-\" \"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36\" \"-\"",
logstash-7.17.0 | "timestamp" => "20/Feb/2018:12:12:14 +0800",
logstash-7.17.0 | "referrer" => "\"-\"",
logstash-7.17.0 | "agent" => "\"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36\"",
logstash-7.17.0 | "host" => "fa3dbceea206",
logstash-7.17.0 | "request" => "/",
logstash-7.17.0 | "clientip" => "112.195.209.90",
logstash-7.17.0 | "path" => "/usr/share/logstash/data/test.log",
logstash-7.17.0 | "verb" => "GET",
logstash-7.17.0 | "auth" => "-",
logstash-7.17.0 | "response" => "200",
logstash-7.17.0 | "ident" => "-",
logstash-7.17.0 | "bytes" => "190",
logstash-7.17.0 | "httpversion" => "1.1",
logstash-7.17.0 | "@timestamp" => 2023-12-23T09:33:50.220Z
logstash-7.17.0 | }
|
Kibana在Dev Tools中内置了Grok Debugger(调试器):
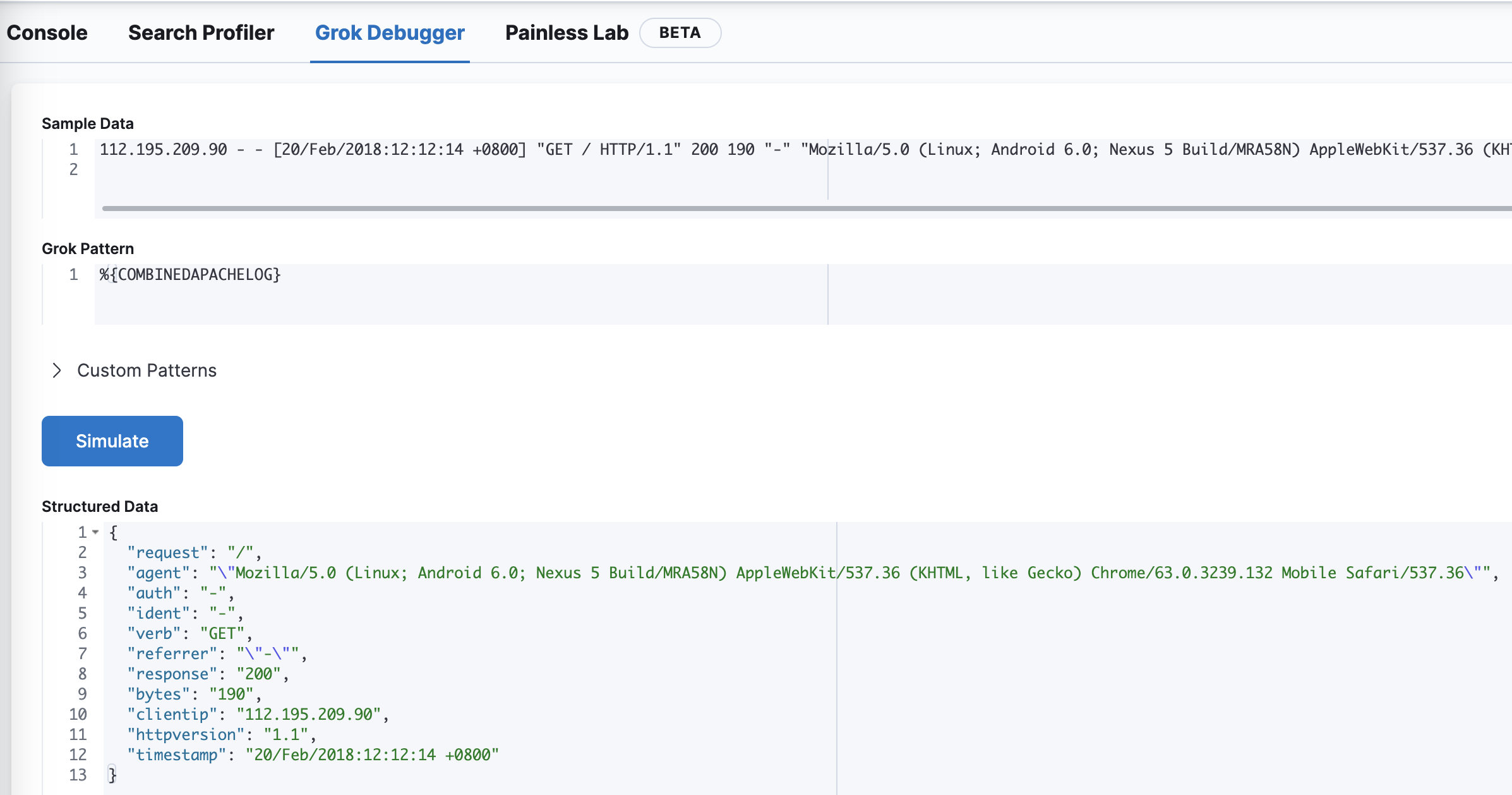 Kibana中的Grok调试器
Kibana中的Grok调试器
示例解析配置4(多行读取插件
multiline)
对 multiline 插件来说,有三个设置比较重要:negate、pattern 和
what。
- pattern: 类型是string,要匹配的正则表达式
- negate: 类型是boolean,默认false,否定正则表达式
- what: 必须设置,可以为 previous 或 next,
如果正则表达式匹配了,那么该事件是属于下一个或是前一个事件
multiline插件可以多行读取。示例文件内容如下(注意最后一行为空行):
1
2
3
4
5
6
| [Aug/08/08 14:54:03] hello world
[Aug/08/09 14:54:04] hello logstash
hello best practice
hello raochenlin
[Aug/08/10 14:54:05] the end
|
配置文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| input {
file {
path => "/usr/share/logstash/data/test.log"
start_position => "beginning"
codec => multiline {
pattern => "^\["
negate => true
what => "previous"
}
}
}
output {
stdout {
codec => rubydebug
}
}
|
解析结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| {
"message" => "[Aug/08/08 14:54:03] hello world",
"@timestamp" => 2023-12-23T10:41:20.884Z,
"path" => "/usr/share/logstash/data/test.log",
"host" => "b62820accf76",
"@version" => "1"
}
{
"message" => "[Aug/08/09 14:54:04] hello logstash\n hello best practice\n hello raochenlin",
"path" => "/usr/share/logstash/data/test.log",
"tags" => [
[0] "multiline"
],
"@timestamp" => 2023-12-23T10:44:24.846Z,
"host" => "b62820accf76",
"@version" => "1"
}
|
由于参数what设置为previous,因此只解析出两条数据。当what设置为next时,可解析出三条数据,但解析结果有变化,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| {
"message" => "[Aug/08/08 14:54:03] hello world",
"path" => "/usr/share/logstash/data/test.log",
"@timestamp" => 2023-12-23T10:49:23.395Z,
"host" => "492dfb254e78",
"@version" => "1"
}
{
"message" => " hello best practice\n hello raochenlin\n[Aug/08/10 14:54:05] the end",
"@timestamp" => 2023-12-23T10:49:23.415Z,
"path" => "/usr/share/logstash/data/test.log",
"host" => "492dfb254e78",
"@version" => "1",
"tags" => [
[0] "multiline"
]
}
{
"message" => "[Aug/08/09 14:54:04] hello logstash",
"path" => "/usr/share/logstash/data/test.log",
"@timestamp" => 2023-12-23T10:49:23.414Z,
"host" => "492dfb254e78",
"@version" => "1"
}
|
ELK搭建简单示例
结合Logstash,
ElasticSearch与Kibana,将data文件夹中的以log结尾的文件,逐行导入至ElasticSearch中。
logstash.conf配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| input {
file {
path => "/usr/share/logstash/data/*.log"
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "test_log"
action => "index"
}
}
|
docker-compose.yml文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| version: "3.1"
services:
logstash:
container_name: logstash-7.17.0
image: docker.elastic.co/logstash/logstash:7.17.0
volumes:
- ./logstash/config/logstash.yml:/usr/share/logstash/logstash.yml
- ./logstash/data:/usr/share/logstash/data
- ./logstash/pipeline:/usr/share/logstash/pipeline
networks:
- elk_net
depends_on:
- elasticsearch
elasticsearch:
container_name: elasticsearch-7.17.0
image: elasticsearch:7.17.0
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- "http.host=0.0.0.0"
- "node.name=elastic01"
- "cluster.name=cluster_elasticsearch"
- "discovery.type=single-node"
ports:
- "9200:9200"
- "9300:9300"
volumes:
- ./es/plugins:/usr/share/elasticsearch/plugins
- ./es/data:/usr/share/elasticsearch/data
networks:
- elk_net
kibana:
container_name: kibana-7.17.0
image: kibana:7.17.0
ports:
- "5601:5601"
networks:
- elk_net
depends_on:
- elasticsearch
networks:
elk_net:
driver: bridge
|
ELK日志系统实战
我们来设计这样一个日志系统,其中Logstash可将Flask运行过程中的日志进行收集,并导入至ElasticSearch中,再使用Kibana进行数据分析。
Flask服务
使用Flask构建简单的web服务,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
import time
import random
from flask import Flask, Response
import logging
logging.basicConfig(filename='../logstash/data/flask.log',
level=logging.DEBUG,
format='%(asctime)s-%(filename)s-%(funcName)s-%(levelname)s-%(message)s')
logger = logging.getLogger()
app = Flask("elk_test")
@app.route('/')
def index():
t1 = time.time()
logger.info(f"api_endpoint: /, status: 200, cost_time: {(time.time() - t1) * 1000}")
return "Hello index", 200
@app.route("/io_task")
def io_task():
t1 = time.time()
time.sleep(2)
logger.info(f"api_endpoint: /io_task, status: 200, cost_time: {(time.time() - t1) * 1000}")
return "IO bound task finish!", 200
@app.route("/cpu_task")
def cpu_task():
t1 = time.time()
for i in range(10000):
n = i*i*i
logger.info(f"api_endpoint: /cpu_task, status: 200, cost_time: {(time.time() - t1) * 1000}")
return "CPU bound task finish!", 200
@app.route("/random_sleep")
def random_sleep():
t1 = time.time()
time.sleep(random.randint(0, 5))
logger.info(f"api_endpoint: /random_sleep, status: 200, cost_time: {(time.time() - t1) * 1000}")
return "random sleep", 200
@app.route("/random_status")
def random_status():
t1 = time.time()
status_code = random.choice([200] * 6 + [300, 400, 400, 500])
logger.info(f"api_endpoint: /random_status, status: {status_code}, cost_time: {(time.time() - t1) * 1000}")
return Response("random status", status=status_code)
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
使用下面的shell脚本进行HTTP请求模拟:
1
2
3
4
5
6
7
8
9
10
| TIMES=5
for i in $(eval echo "{1..$TIMES}")
do
siege -c 1 -r 10 http://localhost:5000/
siege -c 1 -r 5 http://localhost:5000/io_task
siege -c 1 -r 5 http://localhost:5000/cpu_task
siege -c 1 -r 3 http://localhost:5000/random_sleep
siege -c 1 -r 10 http://localhost:5000/random_status
sleep 5
done
|
日志记录在flask.log文件中。
ELK搭建
对上述日志,搭建ELK,docker-compose.yml同上述ELK搭建简单示例,logstash.conf改动如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| input {
file {
path => "/usr/share/logstash/data/flask.log"
start_position => "beginning"
}
}
filter {
if "cost_time" in [message] {
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:request_finish_time}-%{WORD:script}.py-%{WORD:module}-%{LOGLEVEL:loglevel}-api_endpoint: %{DATA:api_endpoint}, status: %{NUMBER:status:int}, cost_time: %{NUMBER:cost_time:float}"
}
}
mutate {
gsub => [ "request_finish_time", " ", "T" ]
gsub => [ "request_finish_time", ",", "." ]
}
date {
match => [ "request_finish_time", "ISO8601" ]
}
}
else {
drop { }
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "flask_log"
action => "index"
}
}
|
只对有cost_time所在的行进行解析,其它行丢弃,导入至ElasticSearch中的flask_log这个索引中。
数据分析
对上述的五个API Endpoint进行请求占比分析,饼图如下:
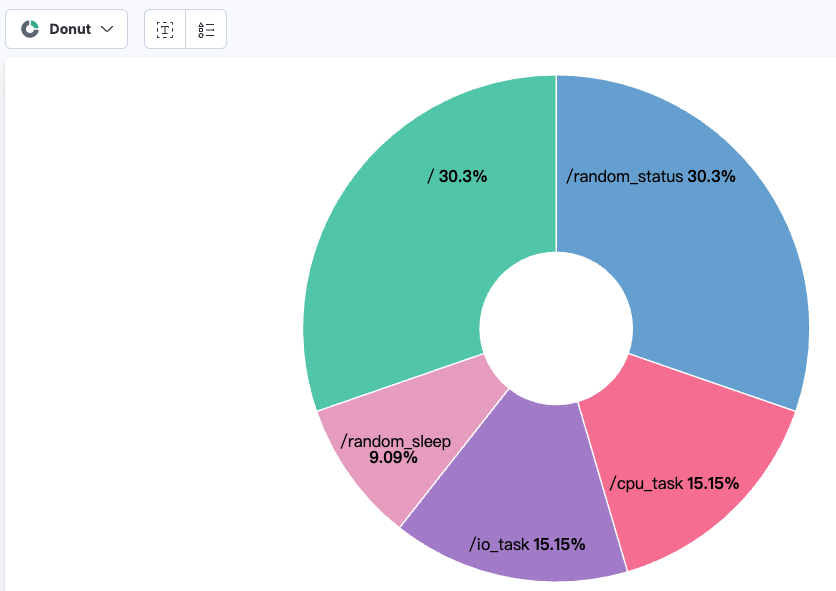 每个API的请求占比
每个API的请求占比
同时,对cost_time进行数据分析,其平均值,90, 95, 99分位数如下表:
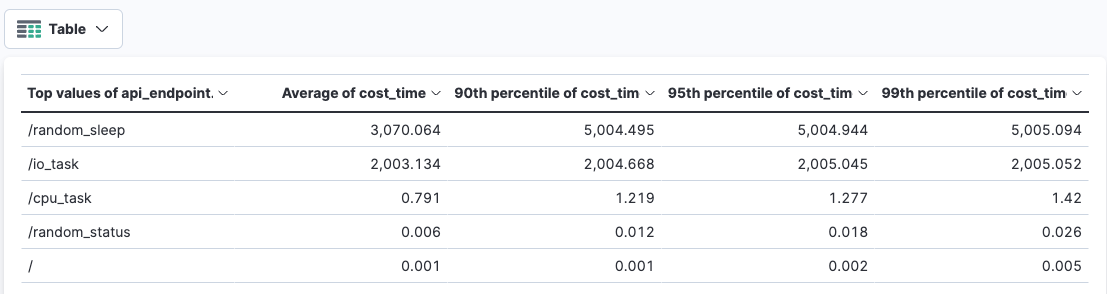 每个API的cost_time分析
每个API的cost_time分析
上述的日志记录方式还有待改进,比如记录程序报错信息,使用json字段解析而不是Grok表达式会更容易些。
注意:使用ChatGPT去做Grok正则表达式是真的好用啊,大模型的问答基本可用,只需略加修改即可,比如上述的Grok正则表达式用ChatGPT做的。
总结
ELK的用途广泛,比较常见的场景是日志系统,但也可以用来实现数据同步等功能。
本文主要介绍了Logstash工具和它的使用方式,以及ELK的搭建简单示例和实战。后面有机会将会介绍ELK的数据同步及Beats家族。
感谢大家的阅读~
欢迎关注我的公众号
NLP奇幻之旅,原创技术文章第一时间推送。

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
