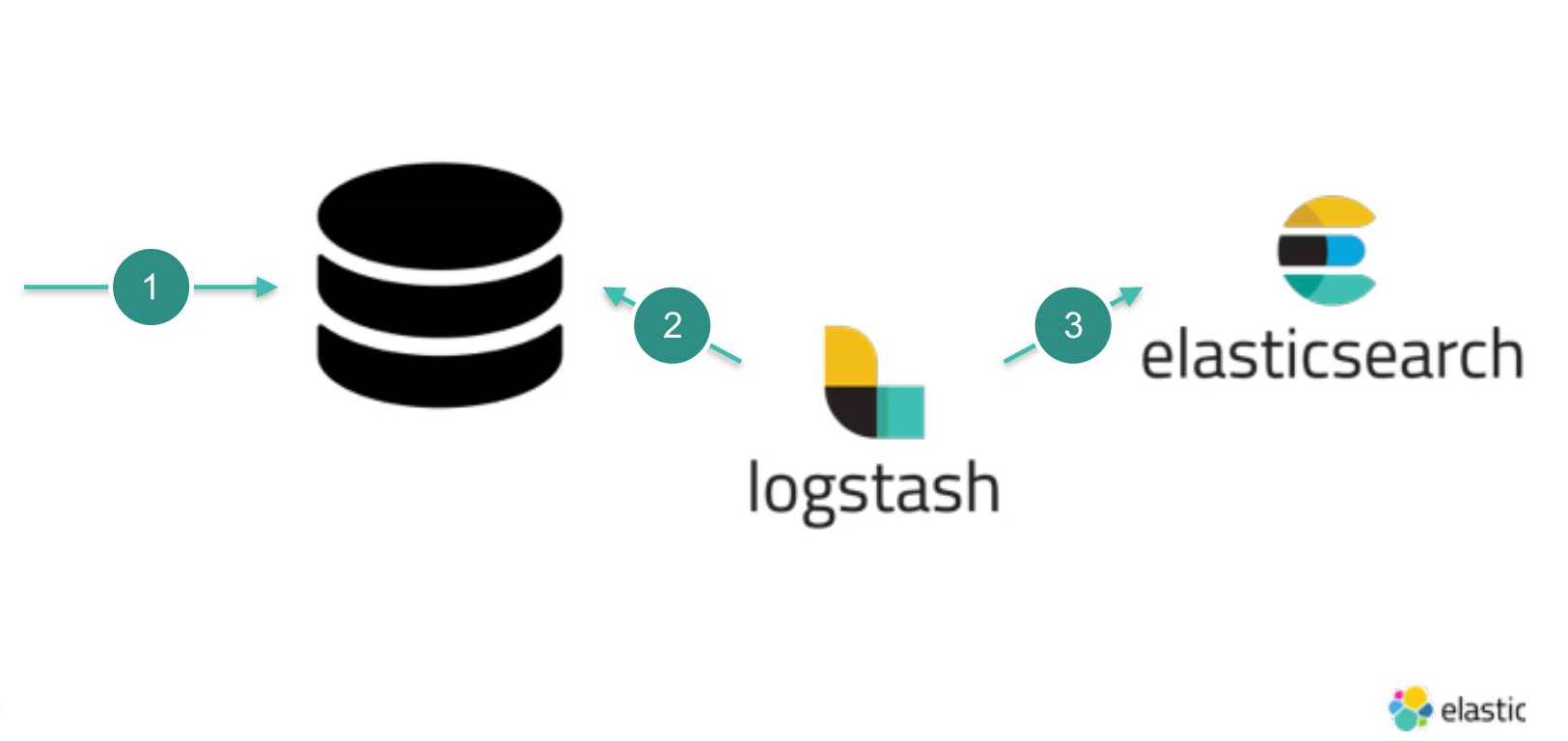
本文主要介绍如何使用ELK工具,将MySQL中的数据同步至ElasticSearch.
本文主要分为以下三个部分:
环境准备:包括启动MySQL与ELK,在MySQL与ES中分别创建对应的表格,开发Python脚本用于往MySQL中创建表格、批量插入数据
全量数据同步:将MySQL表中数据全量同步至ES
增量数据同步:将MySQL表中数据增量同步至ES
ELK实现数据同步
环境准备
使用docker-compose启动mysql, docker-compose.yml如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 version: '3' services: mysql8.0: image: mysql:8.0 container_name: mysql8.0 restart: always environment: TZ: Asia/Shanghai MYSQL_ROOT_PASSWORD: root MYSQL_DATABASE: orm_test ports: - 3306 :3306 volumes: - ./mysql/data/:/var/lib/mysql/ - ./mysql/conf/:/etc/mysql/conf.d/ - ./mysql/init/:/docker-entrypoint-initdb.d/ command: --default-authentication-plugin=mysql_native_password --character-set-server=utf8mb4 --collation-server=utf8mb4_general_ci --explicit_defaults_for_timestamp=true
使用Python中的sqlalchemy + pymysql往MySQL中创建users表格,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from sqlalchemy.dialects.mysql import INTEGER, VARCHAR, DATETIMEfrom sqlalchemy import Columnfrom sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_baseclass Users (Base ):'users' id = Column(INTEGER, primary_key=True )256 ), nullable=False )256 ), nullable=False )def __init__ (self, id , name, age, place, insert_time ):id = id def init_db ():"mysql+pymysql://root:root@localhost:3306/orm_test" ,True print ('Create table successfully!' )if __name__ == '__main__' :
users表结构如下:
1 2 3 4 5 6 7 8 9 +-------------+--------------+------+-----+---------+----------------+ Field | Type | Null | Key | Default | Extra | id | int | NO | PRI | NULL | auto_increment | name | varchar(256) | NO | | NULL | | age | int | YES | | NULL | | place | varchar(256) | NO | | NULL | | insert_time | datetime | YES | | NULL | |
插入5条数据,脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import timefrom sqlalchemy import create_enginefrom sqlalchemy.orm import sessionmakerfrom mysql_create_table import Usersfrom datetime import datetime as dtdef get_time ():5 )return dt.now().strftime("%Y-%m-%d %H:%M:%S" )def insert_data ():"mysql+pymysql://root:root@localhost:3306/orm_test" )id =1 , name='Jack' , age=25 , place='USA' , insert_time=get_time())5 )id =2 , name='Green' , age=26 , place='UK' , insert_time=get_time()),id =3 , name='Alex' , age=31 , place='GER' , insert_time=get_time()),id =4 , name='Chen' , age=52 , place='CHN' , insert_time=get_time()),id =5 , name='Zhang' , age=42 , place='CHN' , insert_time=get_time())print ('insert into db successfully!' )if __name__ == '__main__' :
在需要同步的ES中创建对应的index为mysql_users, 其mapping如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 { "mysql_users" : { "mappings" : { "properties" : { "age" : { "type" : "integer" } , "date_format(insert_time, '%y-%m-%d %h:%i:%s')" : { "type" : "text" , "fields" : { "keyword" : { "type" : "keyword" , "ignore_above" : 256 } } } , "insert_time" : { "type" : "date" , "format" : "yyyy-MM-dd HH:mm:ss" } , "name" : { "type" : "text" } , "place" : { "type" : "text" } , "user_id" : { "type" : "integer" } } } } }
下载Java链接Mysq的第三方Jar包mysql-connector-java-8.0.16.jar.
全量数据同步
将Mysql中users表的数据全量同步至ES中的mysql_users这个index中.
docker-compose.yml文件如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 version: '3' services: mysql8.0: image: mysql:8.0 container_name: mysql8.0 restart: always environment: TZ: Asia/Shanghai MYSQL_ROOT_PASSWORD: root MYSQL_DATABASE: orm_test ports: - 3306 :3306 volumes: - ./mysql/data/:/var/lib/mysql/ - ./mysql/conf/:/etc/mysql/conf.d/ - ./mysql/init/:/docker-entrypoint-initdb.d/ command: --default-authentication-plugin=mysql_native_password --character-set-server=utf8mb4 --collation-server=utf8mb4_general_ci --explicit_defaults_for_timestamp=true networks: - mysql_elk_net logstash: container_name: logstash-7.17.0 image: docker.elastic.co/logstash/logstash:7.17.0 volumes: - ./logstash/config/logstash.yml:/usr/share/logstash/logstash.yml - ./logstash/data:/usr/share/logstash/data - ./logstash/pipeline:/usr/share/logstash/pipeline networks: - mysql_elk_net depends_on: - elasticsearch elasticsearch: container_name: elasticsearch-7.17.0 image: elasticsearch:7.17.0 environment: - "ES_JAVA_OPTS=-Xms1024m -Xmx1024m" - "http.host=0.0.0.0" - "node.name=elastic01" - "cluster.name=cluster_elasticsearch" - "discovery.type=single-node" ports: - "9200:9200" - "9300:9300" volumes: - ./es/plugins:/usr/share/elasticsearch/plugins - ./es/data:/usr/share/elasticsearch/data networks: - mysql_elk_net depends_on: - mysql8.0 kibana: container_name: kibana-7.17.0 image: kibana:7.17.0 ports: - "5601:5601" networks: - mysql_elk_net depends_on: - elasticsearch networks: mysql_elk_net: driver: bridge
logstash.conf配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 input {jdbc {jdbc_driver_library => "/usr/share/logstash/data/mysql-connector-java-8.0.16.jar" jdbc_driver_class => "com.mysql.cj.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://mysql8.0:3306/orm_test?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC" jdbc_user => "root" jdbc_password => "root" statement => "SELECT id as user_id, name, age, place, date_format(insert_time, '%Y-%m-%d %H:%i:%S') as insert_time from users" filter {mutate {remove_field => ["@timestamp" ]mutate {remove_field => ["@version" ]output {stdout {codec => rubydebug elasticsearch {hosts => ["http://elasticsearch:9200" ]index => "mysql_users" document_id => "%{user_id} " action => "index"
对ES中的mysql_users进行查询,如下图:
ES中已同步MySQL表中的全量数据
增量数据同步
docker-compose.yml文件同上述全量数据同步。在增量数据同步时,对logstash.conf修改如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 input {jdbc {jdbc_driver_library => "/usr/share/logstash/data/mysql-connector-java-8.0.16.jar" jdbc_driver_class => "com.mysql.cj.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://mysql8.0:3306/orm_test?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC" jdbc_user => "root" jdbc_password => "root" statement => "SELECT id as user_id,name,age,place,date_format(insert_time, '%Y-%m-%d %H:%i:%S') as insert_time from users where insert_time > :sql_last_value" record_last_run => true use_column_value => true tracking_column_type => "timestamp" tracking_column => "insert_time" last_run_metadata_path => "./user" schedule => "* * * * *" filter {mutate {remove_field => ["@timestamp" ]mutate {remove_field => ["@version" ]output {stdout {codec => rubydebug elasticsearch {hosts => ["http://elasticsearch:9200" ]index => "mysql_users" document_id => "%{user_id} " action => "index"
跟全量抽取的配置相比,上述配置input部分的jdbc插件配置有所改变。
statement的SQL语句,末尾加上了where条件,表示只查询insert_time字段大于最后一次抽取标记的数据。
record_last_run设置为true,表示要保存抽取标记,抽取标记的保存路径在last_run_metadata_path中指定。
tracking_column_type设置为timestamp表示抽取标记字段是时间类型的,如果选择自增长数字主键作为抽取标记,则tracking_column_type应当设置为numeric。
配置tracking_column用于指定抽取标记的列名称,use_column_value设置为true表示使用数据的内容作为抽取标记,否则使用最后一次查询的时间作为抽取标记。
最后schedule用于配置定时抽取的cron表达式 ,"* * * *
*"表示每分钟抽取一次。
执行时,由于第一次没有抽取标记,该脚本会抽取MySQL表users的全部数据到索引mysql_users,抽取完后,会在脚本的当前目录下生成一个user文件,打开它可以看到当前的数据抽取标记,该内容应当为字段insert_time的最新值。
ES中已同步MySQL表中的增量数据
总结
本文主要介绍了如何使用ELK来实现数据同步,将MySQL中的表数据同步至ElasticSearch中,可分为全量数据同步与增量数据同步。实际上,ELK不仅仅能提供MySQL同步至ES,还能做到各种数据库、文件系统等之间的同步,功能十分强大。
感谢大家的阅读~
欢迎关注我的公众号
NLP奇幻之旅 ,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅 ”,笔者正在努力构建自己的技术社区。