本文将会介绍FastAPI中的高级使用技巧,包括中间件、后台任务、请求前/后、生命周期等。
本文将会介绍FastAPI中的高级使用技巧,如下:
中间件(middleware)
后台任务(BackgroundTask)
请求前/后(before or after request)
生命周期(lifespan)
这些技巧将会使我们更加充分地利用FastAPI的性能,同时提升服务的稳定性,使项目更健壮、优雅,代码结构更加清晰。
中间件(middleware)
在FastAPI中,中间件是用于在处理请求和生成响应之间执行代码的组件。中间件可以用于各种任务,例如日志记录、请求和响应的修改、身份验证、跨域资源共享
(CORS) 等。
中间件介绍
"中间件"是一个函数,它在每个请求被特定的路径操作处理之前,以及在每个响应返回之前工作。
它接收你的应用程序的每一个请求.
然后它可以对这个请求做一些事情或者执行任何需要的代码.
然后它将请求传递给应用程序的其他部分
(通过某种路径操作).
然后它获取应用程序生产的响应 (通过某种路径操作).
它可以对该响应做些什么或者执行任何需要的代码.
然后它返回这个响应.
创建中间件
要创建中间件你可以在函数的顶部使用装饰器 @app.middleware ("http").
中间件参数接收如下参数:
request一个函数call_next, 它将接收 request 作为参数.
这个函数将request传递给相应的 路径操作.
然后它将返回由相应的路径操作生成的response.
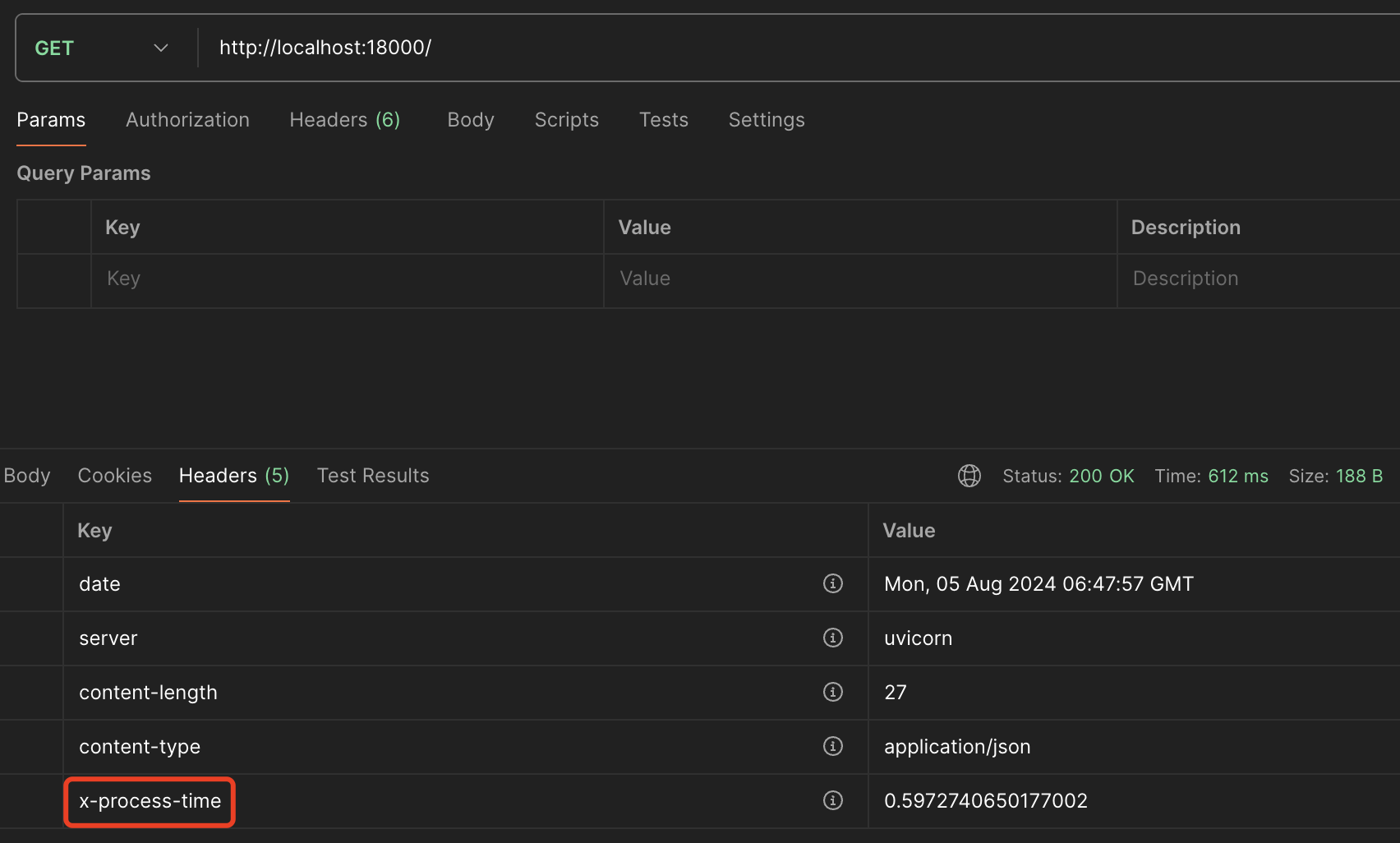
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import timeimport randomfrom fastapi import FastAPI, Request@app.middleware("http" async def add_process_time_header (request: Request, call_next ):await call_next(request)"X-Process-Time" ] = str (process_time)return response@app.get("/" async def read_root ():return {"message" : "Hello, World!" }if __name__ == "__main__" :import uvicorn"0.0.0.0" , port=18000 )
注: 用'X-' 前缀添加专有自定义请求头。
响应体的头部中新增x-process-time参数
其它实现方法
也可以用下面的Python代码实现中间件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import timeimport randomfrom fastapi import FastAPI, Requestfrom starlette.middleware.base import BaseHTTPMiddlewareclass TimingMiddleware (BaseHTTPMiddleware ):async def dispatch (self, request: Request, call_next ):await call_next(request)"X-Process-Time" ] = str (process_time)print (f"Request processed in {process_time} seconds" )return response@app.get("/" async def read_root ():return {"message" : "Hello, World!" }if __name__ == "__main__" :import uvicorn"0.0.0.0" , port=18000 )
后台任务(BackgroundTask)
你可以定义在返回响应后运行的后台任务。这对需要在请求之后执行的操作很有用,但客户端不必在接收响应之前等待操作完成。下面是一些例子:
执行操作后发送的电子邮件通知:
由于连接到电子邮件服务器并发送电子邮件往往很“慢”(几秒钟),您可以立即返回响应并在后台发送电子邮件通知。
处理数据:
例如,假设您收到的文件必须经过一个缓慢的过程,您可以返回一个"Accepted"(HTTP
202)响应并在后台处理它。
示例Python实现函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from fastapi import BackgroundTasks, FastAPIdef write_notification (email: str , message="" ):with open ("log.txt" , mode="w" ) as email_file:f"notification for {email} : {message} " @app.post("/send-notification/{email}" async def send_notification (email: str , background_tasks: BackgroundTasks ):"some notification" )return {"message" : "Notification sent in the background" }if __name__ == "__main__" :import uvicorn"0.0.0.0" , port=18000 )
注:
如果您需要执行繁重的后台计算,并且不一定需要由同一进程运行(例如,您不需要共享内存、变量等),那么使用其他更大的工具(如
Celery)可能更好。
请求前/后(before or after
request)
在 FastAPI 中,虽然没有直接的 before_request 钩子(如 Flask 中的
before_request),但你可以使用中间件(middleware)来实现类似的功能。中间件允许你在每个请求处理之前和之后执行代码。
以下是一个简单的示例,演示如何在 FastAPI 中使用中间件来实现类似
before_request 的功能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from fastapi import FastAPI, Requestfrom starlette.middleware.base import BaseHTTPMiddlewareclass TraceIDMiddleware (BaseHTTPMiddleware ):async def dispatch (self, request: Request, call_next ):'trace_id' )if trace_id:print (f"Received trace_id: {trace_id} " )else :print ("No trace_id found in headers" )await call_next(request)return response@app.get("/items/" async def read_items ():return {"message" : "Hello, World!" }if __name__ == "__main__" :import uvicorn"0.0.0.0" , port=18000 )
请求1:
1 curl http://localhost:18000/items/
在IDE中的输出结果为:
1 2 No trace_id found in headers127 .0 .0 .1 :51063 - "GET /items/ HTTP/1.1" 200 OK
请求2:
1 curl http://localhost:18000/items/ --header 'trace_id: 123'
在IDE中的输出结果为:
1 2 Received trace_id: 123 127 .0 .0 .1 :51108 - "GET /items/ HTTP/1.1" 200 OK
生命周期(lifespan)
您可以定义在应用程序 启动
之前应该执行的逻辑(代码)。这意味着此代码将
执行一次 ,在应用程序 开始接收请求
之前。
同样,您也可以定义在应用程序 关闭
时应该执行的逻辑(代码)。在这种情况下,此代码将
执行一次 ,在可能处理了 许多请求
之后。
因为此代码是在应用程序 开始
接收请求之前执行的,并且在它 完成
处理请求之后立即执行,所以它涵盖了整个应用程序
生命周期 。
这对于设置您需要在整个应用程序中使用的 资源
非常有用,这些资源在请求之间是 共享
的,或者您需要在之后 清理
它们。例如,数据库连接池,或加载共享的机器学习模型。
示例Python实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from contextlib import asynccontextmanagerfrom fastapi import FastAPIdef fake_answer_to_everything_ml_model (x: float ):return x * 42 @asynccontextmanager async def lifespan (app: FastAPI ):"answer_to_everything" ] = fake_answer_to_everything_ml_modelyield @app.get("/predict" async def predict (x: float ):"answer_to_everything" ](x)return {"result" : result}if __name__ == "__main__" :import uvicorn"0.0.0.0" , port=18000 )
请求1:
1 curl http://localhost:18000/predict\?x\=2
输出: