Kafka入门(一)Kafak介绍、安装与简单使用
本文详细介绍了 Kafka 的基本概念、使用场景以及从安装到使用的完整流程,包括命令行模式、Offset Explorer 可视化工具和 Python 脚本操作,适合初学者快速上手。
Kafka简介
Kafka 是一个由 LinkedIn
开发的开源分布式流处理平台,现已成为 Apache
的顶级项目。它主要用于处理实时数据流,具备高吞吐量、低延迟和强大的扩展性。
重要概念
- Broker: Kafka 的基本单元,负责存储和传递消息。一个 Kafka 集群由多个 Broker 组成。
- Topic: 消息的分类,每条消息都属于一个特定的 Topic。用户可以通过 Topic 来组织和管理消息。
- Producer: 消息的生产者,负责将消息发送到指定的 Topic。
- Consumer: 消息的消费者,从 Kafka 中读取消息的客户端。
- Consumer Group: 一组消费者,能够共同消费同一 Topic 的消息。每条消息只能被同一 Consumer Group 中的一个 Consumer 消费,但可以被多个不同的 Consumer Group 消费。
- Partition: 每个 Topic 可以分为多个 Partition,Partition 内部消息有序存储,并且可以分布在不同的 Broker 上,以实现负载均衡和高可用性。

使用场景
Kafka 的应用场景非常广泛,包括但不限于:
- 日志收集: 用于集中收集和处理来自不同服务的日志信息。
- 消息系统: 解耦生产者和消费者,支持异步通信。
- 用户活动追踪: 记录用户在网站或应用上的行为,以便进行实时分析。
- 运营指标监控: 收集和分析系统性能指标,实现实时监控。
- 流处理: 通过 Kafka 构建实时数据管道,与大数据处理框架(如 Spark 和 Flink)结合使用。

Kafka安装
软件安装顺序:
- Java
- ZooKeeper
- Kafka
- Offset Explorer
注意: 笔者使用的电脑为Mac, 安装上述软件比较方便。如需在Windows上安装,则安装流程会稍微复杂些,但过程类似。
Java安装
Java的安装已是老生常谈,本文不再介绍。笔者电脑上已安装Java。
1 | |
ZooKeeper安装
下载ZooKeeper(网站为: https://zookeeper.apache.org/releases.html) ,解析文件后,进入bin目录,使用如下脚本启动ZooKeeper。笔者使用的ZooKeeper版本为3.9.3。
1 | |
Kafka安装
下载Kafka(网站为: https://kafka.apache.org/downloads) ,解析文件后,进入bin目录,使用如下脚本启动Kafka。笔者使用的Kafka版本为3.9.0。
1 | |
Offset Explorer安装
Offset Explorer(原名Kafka Tool)是Kafka集群的管理可视化工具。
从网站(https://www.kafkatool.com/download.html )中下载对应系统的Offset Explorer并完成安装。
接下来,我们使用Offset Explorer来连接本地启动的Kafka服务。
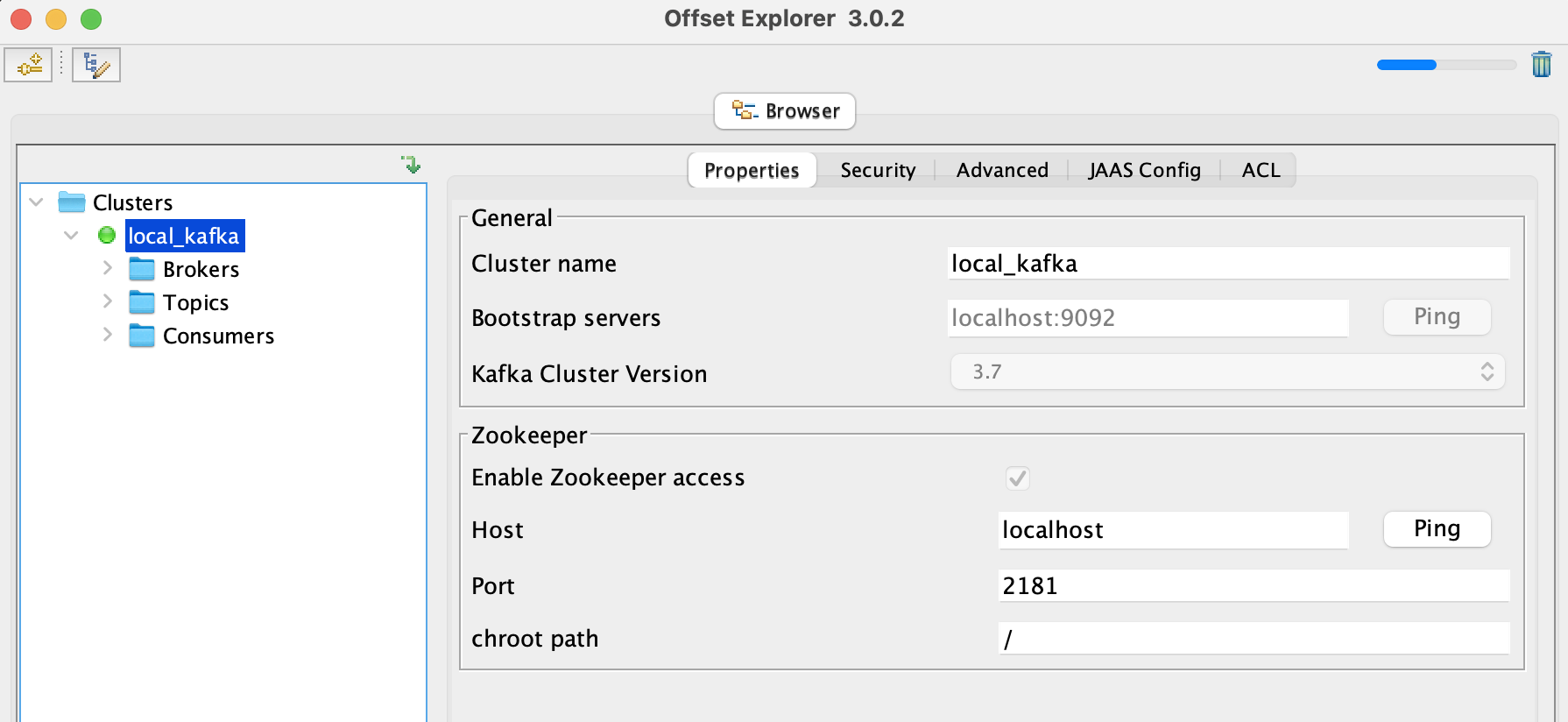
点击Connect,就会显示对应的Kafka服务信息,这表明Kafka服务已正常启动。
Kafka简单使用
命令行模式
Kafka 中的 topic 是数据的逻辑分组和存储单位,用于组织和管理消息流。通过分区机制,topic 提供了高吞吐量和扩展性,是 Kafka 实现分布式消息系统的核心概念。
- 查看所有 Topic
1 | |
由于我们并未创建任何 topic ,因此 Kafka
中只有一个内置的特殊topic,__consumer_offsets,它是 Kafka
中消费者偏移量存储的核心机制,它的存在使得 Kafka
能够高效实现消费者组的进度管理和负载均衡。
- 创建 Topic
我们创建两个示例 Topic, 它们是school和lab, 它们的副本和分区数量均为1.
1 | |
- 删除 Topic
我们删除lab这个topic,命令如下:
1 | |
查看所有 topic 时,只剩下__consumer_offsets和school这两个topic,这表明lab这个topic已被成功删除了。
- 描述 Topic
如需查看指定 topic 的元数据信息,包括分区、leader、副本等,命令如下:
1 | |
- 创建生产者(Producer)
Kafka 有一个命令行服务端,它将从文件或标准输入中获取输入,并将其作为消息发送到 Kafka 集群。默认情况下,每行将作为单独的消息发送:(这里的生产者和下面的消费者所使用的topic为school,两者必须使用同一个topic.)
1 | |
- 创建消费者(Consumer)
Kafka中的消费者创建命令如下:
1 | |
我们在生产者这边输入消息:Hello Kafka! 和 Hello Java! 和 Hello ZooKeeper!,生产者和消费者端的输入、输出如下:
- 生产者端的输入
1 | |
- 消费者端的输出
1 | |
Offset Explorer模式
我们在Offset Explorer中查看Topic以及该Topic中的消息内容。

可以看到,我们创建的school这个topic,消息数量为3。将Content Type类型设置为String,就能以人类可读的形式看到消息内容,如下所示:

Python模式
查看所有Topic及每个Topic的详细消息,Python命令如下:
1 | |
输出结果如下:
所有 Topic: ['school', '__consumer_offsets']
Topic 详情: {'error_code': 0, 'topic': 'school', 'is_internal': False, 'partitions': [{'error_code': 0, 'partition': 0, 'leader': 0, 'replicas': [0], 'isr': [0], 'offline_replicas': []}]}创建消费者,Python命令如下:
1 | |
创建生产者,Python命令如下:
1 | |
先运行消费者的Python脚本,再运行生产者的Python脚本。
此时消费者的运行结果输出为:
1 | |
此时在Offset Explorer中,可以看到school这个topic所产生的消息,如下:

总结
本文通过介绍 Kafka 的核心概念,包括 Broker、Topic、Partition、Producer 和 Consumer 等,帮助读者了解其分布式流处理系统的基本架构。在使用场景中,结合实际应用详细说明了 Kafka 在日志收集、消息系统、用户行为追踪、运营指标监控和流处理等方面的优势。
通过实践部分的详细讲解,从 Kafka 的安装与配置开始,逐步深入到命令行操作,Offset Explorer 可视化管理工具的使用,以及通过 Python 编程实现生产者与消费者的消息收发,全面覆盖了 Kafka 的常见使用方式。
通过这些内容,读者不仅可以理解 Kafka 的技术特点和核心功能,还能掌握如何快速搭建和管理一个 Kafka 集群,以及如何在不同场景中灵活应用 Kafka 处理实时数据流。本文为初学者和有经验的开发者提供了清晰的学习路径和实践指南,为进一步深度学习和项目应用奠定了坚实基础。
参考文章
- Kafka 入门(一)--安装配置和 kafka-python 调用: https://www.cnblogs.com/TM0831/p/13355383.html
- Docker 部署 Kafka 单/多节点:https://oldme.net/article/27
- Kafka Tool(Kafka 可视化工具)安装及使用教程:https://blog.csdn.net/qq_43961619/article/details/109381849