Kafka入门(二)ELK遇上Kafka:日志分析最佳实践
本文将会介绍如何在ELK框架中加入Kafka,使得日志采集系统更加健壮。
笔者在前年底的文章ELK学习笔记(三)Beats家族中,介绍了ELK框架中的Beats家族,但当时的框架中并未加入任何消息队列的组件。
在本文中,笔者将会在ELK框架中加入Kafka,使得日志采集系统更加健壮,流程图如下:

Kafka启动
在文章Kafka入门(一)Kafak介绍、安装与简单使用中,笔者介绍了Kafka的简单操作,包括安装、基础命令以及在Python中如何使用。
在本文中,笔者将沿用上文的方式,即在本地系统中直接启动软件,启动的方式不在此赘述,有困惑的文章可以参考文章文章Kafka入门(一)Kafak介绍、安装与简单使用 。
在本地启动Kafka后,新建topic,用于日志采集,其中topic的名称为flask-log,生产者一方为Beats家族,它负责对本地日志进行采集;消费者一方为Logstash,它负责对日志进行加工处理,然后写入ElasticSearch中。
新建topic命令如下:
1 | |
ELK配置
对于ELK框架,笔者仍采用Docker Compose方式启动,其中docker-compose.yml文件如下:
1 | |
其中,filebeat组件中的配置文件filebeat.yml文件如下:
1 | |
注意,在上述配置中,输入(inputs)的fields中设置Kafka的topic为flask-log,输出(output.kafka)的host并不是localhost,而是本地局域网的IP。
在Logstash组件中,配置文件logstash.conf如下:
1 | |
在上述配置文件中,规定了输入来源为Kafka,并对日志数据制定了一系列的加工处理逻辑,具体不在此赘述,可参考文章ELK入门教程(一)。
日志采集
至此,ELK框架中已经集成了Kafka这个消息队列组件。
接下来,我们使用Flask来产生Web服务日志,并使用上述工具来采集这些日志。
使用Flask部署的Web服务的Python代码如下:
1 | |
启动后,我们使用如下Shell命令来模拟HTTP请求,内容如下:
1 | |
最后,让我们来看下在Kafka和ElasticSearch中都发生了什么变化。
flask.log文件中共有335条日志记录。

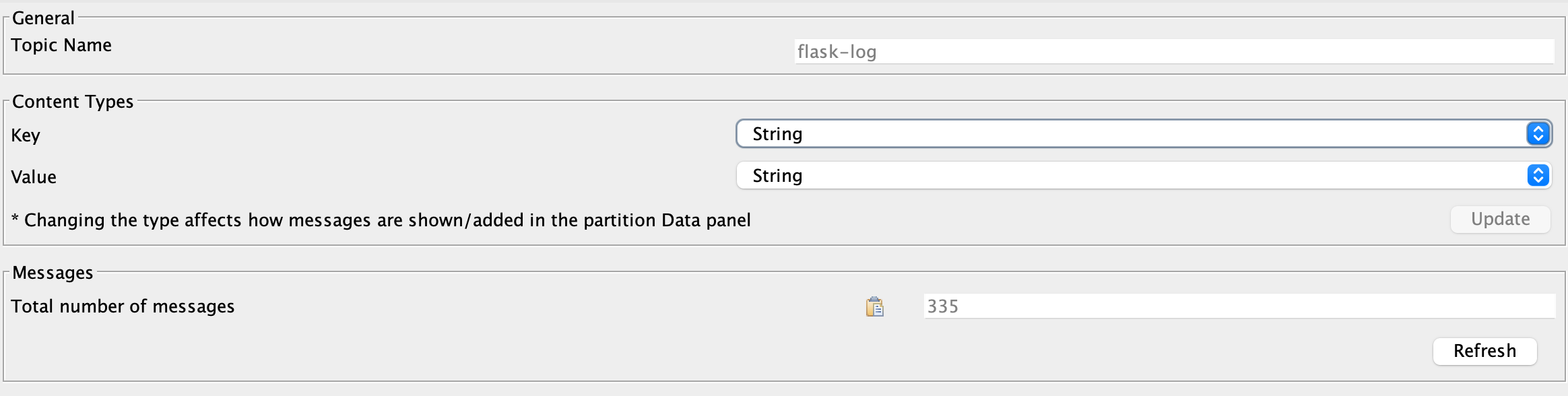
Kafka中的flask-log这个topic中共有335条消息。
在ElasticSearch中查看flask_log这个索引,共有165个文档,对应最后一条日志的文档如下:
1 | |
总结
本文主要介绍了如何在ELK框架中集成Kafka,并使用Flask Web日志来作为演示例子来介绍日志的完整处理链路。
后续笔者将会更加深入地介绍Kafka及其相关用途,欢迎关注~