在文章Keras入门(一)搭建深度神经网络(DNN)解决多分类问题 中,笔者介绍了如何搭建DNN模型来解决IRIS数据集的多分类问题。
本文将在此基础上介绍如何在Keras中实现K折交叉验证。
什么是K折交叉验证?
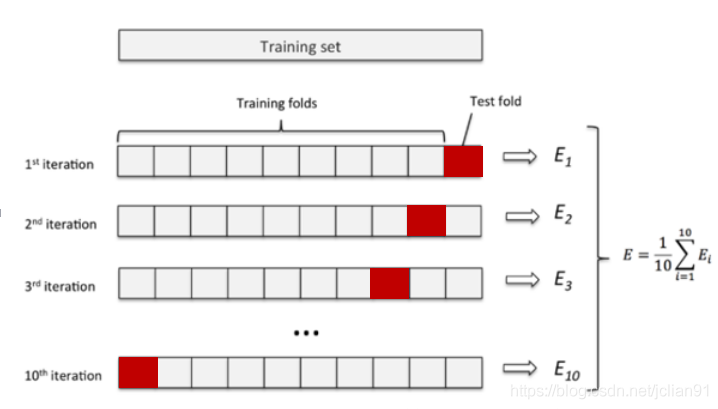
K折交叉验证是机器学习中的一个专业术语,它指的是将原始数据随机分成K份,每次选择K-1份作为训练集,剩余的1份作为测试集。交叉验证重复K次,取K次准确率的平均值作为最终模型的评价指标。一般取K=10,即10折交叉验证,如下图所示:
10折交叉验证
用交叉验证的目的是为了得到可靠稳定的模型。K折交叉验证能够有效提高模型的学习能力,类似于增加了训练样本数量,使得学习的模型更加稳健,鲁棒性更强。选择合适的K值能够有效避免过拟合。
Keras实现K折交叉验证
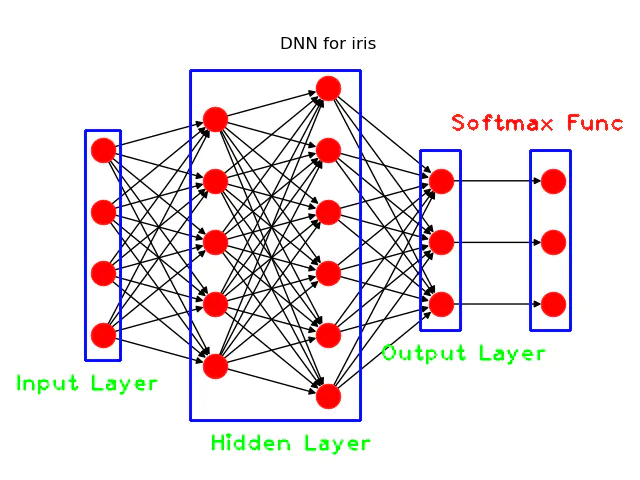
我们仍采用文章Keras入门(一)搭建深度神经网络(DNN)解决多分类问题 中的模型,如下:
DNN模型结构图
同时,我们对IRIS数据集采用10折交叉验证,完整的实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import keras as Kimport pandas as pdfrom sklearn.model_selection import KFolddef load_data (sv_file_path ):'class' list (iris.columns)dict (zip (Class, range (len (Class))))'target' ] = iris[target_var].apply(lambda x: Class_dict[x])return features, 'target' , irisdef create_model ():1 )5 , input_dim=4 , kernel_initializer=init, activation='relu' ))6 , kernel_initializer=init, activation='relu' ))3 , kernel_initializer=init, activation='softmax' ))compile (loss='sparse_categorical_crossentropy' , optimizer=simple_adam, metrics=['accuracy' ])return modeldef main ():print ("Loading Iris data into memory" )10 "./iris_data.csv" )0 0 for train_index, test_index in KFold(n_split).split(x):print ("test index: " , test_index)print ("create model and train model" )1 , epochs=80 , verbose=0 )print ('Model evaluation: ' , model.evaluate(x_test, y_test))1 ]0 ]print ("K fold average accuracy: {}" .format (avg_accuracy / n_split))print ("K fold average accuracy: {}" .format (avg_loss / n_split))
模型的输出结果如下: |Iteration|loss|accuracy| |---|---|---|
|1|0.00056|1.0| |2|0.00021|1.0| |3|0.00022|1.0| |4|0.00608|1.0|
|5|0.21925|0.8667| |6|0.52390|0.8667| |7|0.00998|1.0| |8|0.04431|1.0|
|9|0.14590|1.0| |10|0.21286|0.8667| |avg|0.11633|0.9600|
10折交叉验证的平均loss为0.11633,平均准确率为96.00%。
总结
本文代码已存放至Github,网址为:https://github.com/percent4/Keras-K-fold-test
。
感谢大家的阅读~
2020.1.24于上海浦东
欢迎关注我的公众号
NLP奇幻之旅 ,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅 ”,笔者正在努力构建自己的技术社区。