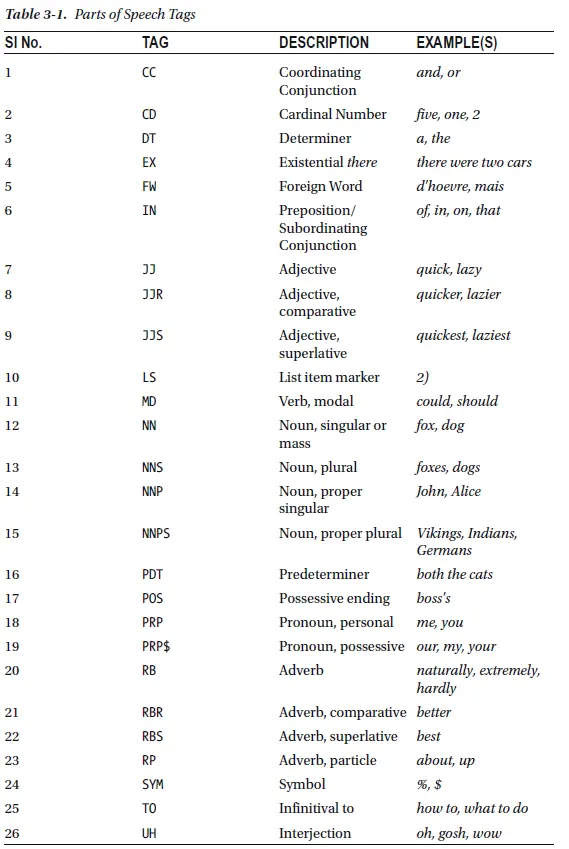
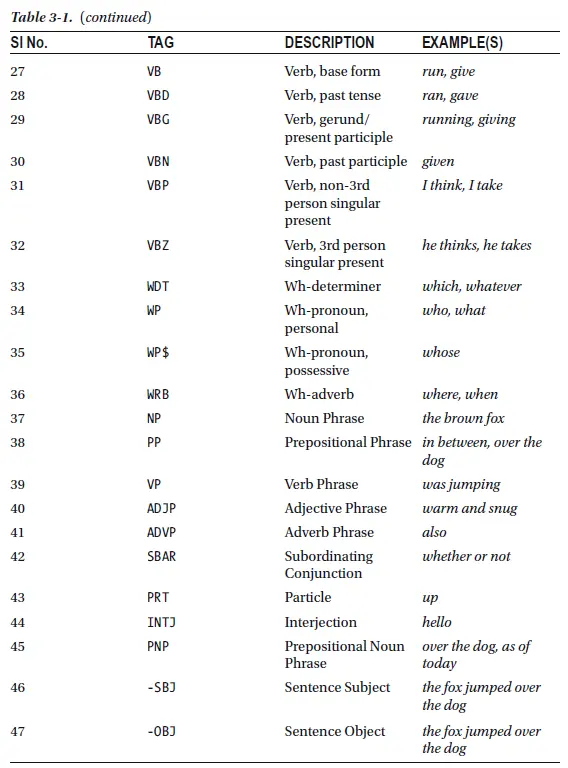
那么,如何获取单词的词性呢?在NLP中,使用Parts of
speech(POS)技术实现。在nltk中,可以使用nltk.pos_tag()获取单词在句子中的词性,如以下Python代码:
1 2 3 4 5
sentence = 'The brown fox is quick and he is jumping over the lazy dog' import nltk tokens = nltk.word_tokenize(sentence) tagged_sent = nltk.pos_tag(tokens) print(tagged_sent)
sentence = 'football is a family of team sports that involve, to varying degrees, kicking a ball to score a goal.' tokens = word_tokenize(sentence) # 分词 tagged_sent = pos_tag(tokens) # 获取单词词性
wnl = WordNetLemmatizer() lemmas_sent = [] for tag in tagged_sent: wordnet_pos = get_wordnet_pos(tag[1]) or wordnet.NOUN lemmas_sent.append(wnl.lemmatize(tag[0], pos=wordnet_pos)) # 词形还原