played on Monday ( home team in CAPS ) : VBD IN NNP ( NN NN IN NNP ) : O O O O O O O O O O American League NNP NNP B-MISC I-MISC Cleveland 2 DETROIT 1 NNP CD NNP CD B-ORG O B-ORG O BALTIMORE 12 Oakland 11 ( 10 innings ) VB CD NNP CD ( CD NN ) B-ORG O B-ORG O O O O O TORONTO 5 Minnesota 3 TO CD NNP CD B-ORG O B-ORG O ......
# load data from corpus to from pandas DataFrame defload_data(): withopen(CORPUS_PATH, 'r') as f: text_data = [text.strip() for text in f.readlines()] text_data = [text_data[k].split('\t') for k inrange(0, len(text_data))] index = range(0, len(text_data), 3)
# Transforming data to matrix format for neural network input_data = list() for i inrange(1, len(index) - 1): rows = text_data[index[i-1]:index[i]] sentence_no = np.array([i]*len(rows[0]), dtype=str) rows.append(sentence_no) rows = np.array(rows).T input_data.append(rows)
input_data = pd.DataFrame(np.concatenate([item for item in input_data]),\ columns=['word', 'pos', 'tag', 'sent_no'])
word pos tag sent_no 0 played VBD O 1 1on IN O 1 2 Monday NNP O 1 3 ( ( O 1 4 home NN O 1 5 team NN O 1 6 in IN O 1 7 CAPS NNP O 1 8 ) ) O 1 9 : : O 1 10 American NNP B-MISC 2 11 League NNP I-MISC 2 12 Cleveland NNP B-ORG 3 132 CD O 3 14 DETROIT NNP B-ORG 3 151 CD O 3 16 BALTIMORE VB B-ORG 4 1712 CD O 4 18 Oakland NNP B-ORG 4 1911 CD O 4 20 ( ( O 4 2110 CD O 4 22 innings NN O 4 23 ) ) O 4 24 TORONTO TO B-ORG 5 255 CD O 5 26 Minnesota NNP B-ORG 5 273 CD O 5 28 Milwaukee NNP B-ORG 6 293 CD O 6
import pickle import numpy as np from collections import Counter from itertools import accumulate from operator import itemgetter import matplotlib.pyplot as plt import matplotlib as mpl from utils import BASE_DIR, CONSTANTS, load_data
# 字典列表 word_dictionary = {word: i+1for i, word inenumerate(vocabulary)} inverse_word_dictionary = {i+1: word for i, word inenumerate(vocabulary)} label_dictionary = {label: i+1for i, label inenumerate(labels)} output_dictionary = {i+1: labels for i, labels inenumerate(labels)}
# 处理输入数据 aggregate_function = lambdainput: [(word, pos, label) for word, pos, label in zip(input['word'].values.tolist(), input['pos'].values.tolist(), input['tag'].values.tolist())]
grouped_input_data = input_data.groupby('sent_no').apply(aggregate_function) sentences = [sentence for sentence in grouped_input_data]
x = [[word_dictionary[word[0]] for word in sent] for sent in sentences] x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0) y = [[label_dictionary[word[2]] for word in sent] for sent in sentences] y = pad_sequences(maxlen=input_shape, sequences=y, padding='post', value=0) y = [np_utils.to_categorical(label, num_classes=label_size + 1) for label in y]
return x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionary
# 在测试集上的效果 N = test_x.shape[0] # 测试的条数 avg_accuracy = 0# 预测的平均准确率 for start, end inzip(range(0, N, 1), range(1, N+1, 1)): sentence = [inverse_word_dictionary[i] for i in test_x[start] if i != 0] y_predict = lstm_model.predict(test_x[start:end]) input_sequences, output_sequences = [], [] for i inrange(0, len(y_predict[0])): output_sequences.append(np.argmax(y_predict[0][i])) input_sequences.append(np.argmax(test_y[start][i]))
eval = lstm_model.evaluate(test_x[start:end], test_y[start:end]) print('Test Accuracy: loss = %0.6f accuracy = %0.2f%%' % (eval[0], eval[1] * 100)) avg_accuracy += eval[1] output_sequences = ' '.join([output_dictionary[key] for key in output_sequences if key != 0]).split() input_sequences = ' '.join([output_dictionary[key] for key in input_sequences if key != 0]).split() output_input_comparison = pd.DataFrame([sentence, output_sequences, input_sequences]).T print(output_input_comparison.dropna()) print('#' * 80)
avg_accuracy /= N print("测试样本的平均预测准确率:%.2f%%." % (avg_accuracy * 100))
......(前面的输出已忽略) Test Accuracy: loss = 0.000986 accuracy = 100.00% 012 0 Cardiff B-ORG B-ORG 11 O O 2 Brighton B-ORG B-ORG 30 O O ################################################################################
1/1 [==============================] - 0s 10ms/step Test Accuracy: loss = 0.000274 accuracy = 100.00% 012 0 Carlisle B-ORG B-ORG 10 O O 2 Hull B-ORG B-ORG 30 O O ################################################################################
1/1 [==============================] - 0s 9ms/step Test Accuracy: loss = 0.000479 accuracy = 100.00% 012 0 Chester B-ORG B-ORG 11 O O 2 Cambridge B-ORG B-ORG 31 O O ################################################################################
1/1 [==============================] - 0s 9ms/step Test Accuracy: loss = 0.003092 accuracy = 100.00% 012 0 Darlington B-ORG B-ORG 14 O O 2 Swansea B-ORG B-ORG 31 O O ################################################################################
1/1 [==============================] - 0s 8ms/step Test Accuracy: loss = 0.000705 accuracy = 100.00% 012 0 Exeter B-ORG B-ORG 12 O O 2 Scarborough B-ORG B-ORG 32 O O ################################################################################ 测试样本的平均预测准确率:95.55%.
# -*- coding: utf-8 -*- # Name entity recognition for new data
# Import the necessary modules import pickle import numpy as np from utils import CONSTANTS from keras.preprocessing.sequence import pad_sequences from keras.models import load_model from nltk import word_tokenize
# 导入字典 withopen(CONSTANTS[1], 'rb') as f: word_dictionary = pickle.load(f) withopen(CONSTANTS[4], 'rb') as f: output_dictionary = pickle.load(f)
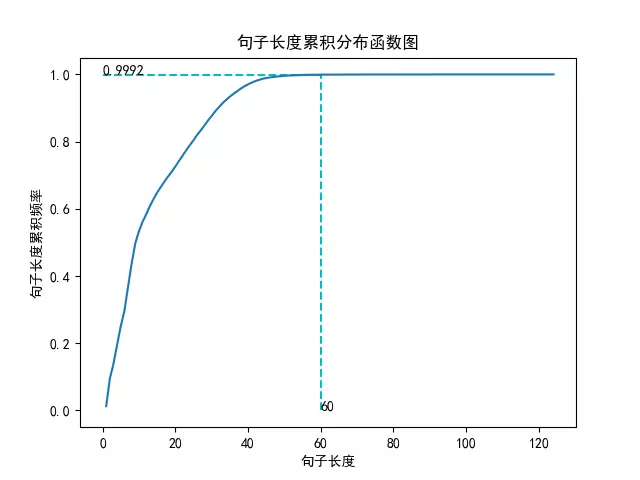
try: # 数据预处理 input_shape = 60 sent = 'New York is the biggest city in America.' new_sent = word_tokenize(sent) new_x = [[word_dictionary[word] for word in new_sent]] x = pad_sequences(maxlen=input_shape, sequences=new_x, padding='post', value=0)
ner_tag = [] for i inrange(0, len(new_sent)): ner_tag.append(np.argmax(y_predict[0][i]))
ner = [output_dictionary[i] for i in ner_tag] print(new_sent) print(ner)
# 去掉NER标注为O的元素 ner_reg_list = [] for word, tag inzip(new_sent, ner): if tag != 'O': ner_reg_list.append((word, tag))
# 输出模型的NER识别结果 print("NER识别结果:") if ner_reg_list: for i, item inenumerate(ner_reg_list): if item[1].startswith('B'): end = i+1 while end <= len(ner_reg_list)-1and ner_reg_list[end][1].startswith('I'): end += 1