pyltp的简介
语言技术平台(LTP)经过哈工大社会计算与信息检索研究中心 11
年的持续研发和推广,
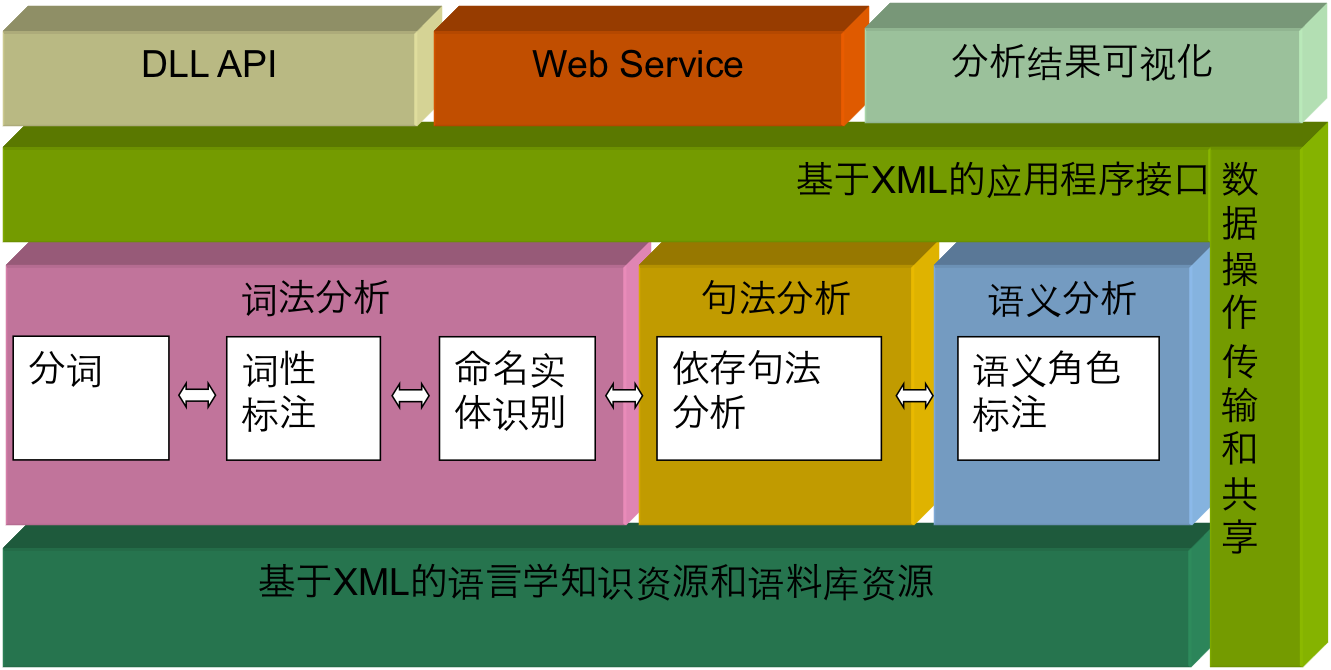
是国内外最具影响力的中文处理基础平台。它提供的功能包括中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注等。
语言技术平台架构
pyltp 是 LTP 的 Python
封装,同时支持Python2和Python3版本。Python3的安装方法为:
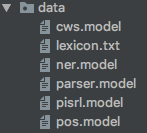
模型数据
其中,cws.model用于分词模型,lexicon.txt为分词时添加的用户字典,ner.model为命名实体识别模型,parser.model为依存句法分析模型,pisrl.model为语义角色标注模型,pos为词性标注模型。
pyltp的使用
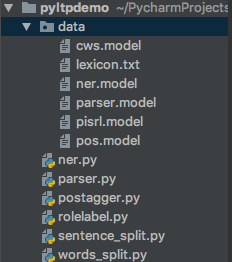
pyltp的使用示例项目结构如下:
示例项目
分句
分句指的是将一段话或一片文章中的文字按句子分开,按句子形成独立的单元。示例的Python代码sentenct_split.py如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from pyltp import SentenceSplitter'据韩联社12月28日反映,美国防部发言人杰夫·莫莱尔27日表示,美国防部长盖茨将于2011年1月14日访问韩国。' \'盖茨原计划从明年1月9日至14日陆续访问中国和日本,目前,他决定在行程中增加对韩国的访问。莫莱尔表示,' \'盖茨在访韩期间将会晤韩国国防部长官金宽镇,就朝鲜近日的行动交换意见,同时商讨加强韩美两军同盟关系等问题,' \'拟定共同应对朝鲜挑衅和核计划的方案。' for sent in sents:print (sent)
输出结果如下:
1 2 3 据韩联社12 月28 日反映,美国防部发言人杰夫·莫莱尔27 日表示,美国防部长盖茨将于2011年1月14 日访问韩国。1 月9 日至14 日陆续访问中国和日本,目前,他决定在行程中增加对韩国的访问。
分词
分词指的是将一句话按词语分开,按词语形成独立的单元。示例的Python代码words_split.py如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import osfrom pyltp import Segmentor'data/cws.model' ) 'data/lexicon.txt' ) '据韩联社12月28日反映,美国防部发言人杰夫·莫莱尔27日表示,美国防部长盖茨将于2011年1月14日访问韩国。' print ('/' .join(words))
输出的结果如下:
1 据/韩联社/ 12 月/28日/ 反映/,/ 美/国防部/ 发言人/杰夫·莫莱尔/ 27 日/表示/ ,/美/ 国防部长/盖茨/ 将/于/ 2011 年/1月/ 14 日/访问/ 韩国/。
词性标注
词性标注指的是一句话分完词后,制定每个词语的词性。示例的Python代码postagger.py如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import osfrom pyltp import Segmentor, Postagger'data/cws.model' ) 'data/lexicon.txt' ) '据韩联社12月28日反映,美国防部发言人杰夫·莫莱尔27日表示,美国防部长盖茨将于2011年1月14日访问韩国。' 'data/pos.model' ) for word, postag in zip (words, postags):print (word, postag)''' 词性标注结果说明 https://ltp.readthedocs.io/zh_CN/latest/appendix.html#id3 '''
输出结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 据 p12 月 nt28 日 ntn n 27 日 ntn 2011 年 nt1 月 nt14 日 nt
词性标注结果可参考网址:https://ltp.readthedocs.io/zh_CN/latest/appendix.html
。
命名实体识别
命名实体识别(NER)指的是识别出一句话或一段话或一片文章中的命名实体,比如人名,地名,组织机构名。示例的Python代码ner.py如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 import osfrom pyltp import Segmentor, Postagger'data/cws.model' ) 'data/lexicon.txt' ) '据韩联社12月28日反映,美国防部发言人杰夫·莫莱尔27日表示,美国防部长盖茨将于2011年1月14日访问韩国。' 'data/pos.model' ) 'data/ner.model' ) from pyltp import NamedEntityRecognizerset (), set (), set ()list (recognizer.recognize(words, postags)) print (netags)0 for tag, word in zip (netags, words):if 'Nh' in tag:if str (tag).startswith('S' ):elif str (tag).startswith('B' ):while netags[j] != 'E-Nh' :1 if j < len (words):if 'Ns' in tag:if str (tag).startswith('S' ):elif str (tag).startswith('B' ):while netags[j] != 'E-Ns' :1 if j < len (words):if 'Ni' in tag:if str (tag).startswith('S' ):elif str (tag).startswith('B' ):while netags[j] != 'E-Ni' :1 if j < len (words):1 print ('人名:' , ',' .join(persons))print ('地名:' , ',' .join(places))print ('组织机构:' , ',' .join(orgs))
输出的结果如下:
1 2 3 4 ['O' , 'S-Ni' , 'O' , 'O' , 'O' , 'O' , 'B-Ni' , 'E-Ni' , 'O' , 'S-Nh' , 'O' , 'O' , 'O' , 'S-Ns' , 'O' , 'S-Nh' , 'O' , 'O' , 'O' , 'O' , 'O' , 'O' , 'S-Ns' , 'O' ]
命名实体识别结果可参考网址:https://ltp.readthedocs.io/zh_CN/latest/appendix.html
。
依存句法分析
依存语法 (Dependency Parsing, DP)
通过分析语言单位内成分之间的依存关系揭示其句法结构。
直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。示例的Python代码parser.py代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import osfrom pyltp import Segmentor, Postagger, Parser'data/cws.model' ) 'data/lexicon.txt' ) '据韩联社12月28日反映,美国防部发言人杰夫·莫莱尔27日表示,美国防部长盖茨将于2011年1月14日访问韩国。' 'data/pos.model' ) 'data/parser.model' ) for arc in arcs] for arc in arcs] 'Root' if id == 0 else words[id -1 ] for id in rely_id] for i in range (len (words)):print (relation[i] + '(' + words[i] + ', ' + heads[i] + ')' )
输出结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ADV (据, 表示) SBV (韩联社, 反映) ATT (12 月, 28 日) ADV (28 日, 反映) POB (反映, 据) WP (,, 据) ATT (美, 国防部) ATT (国防部, 发言人) ATT (发言人, 杰夫·莫莱尔) SBV (杰夫·莫莱尔, 表示) ADV (27 日, 表示) HED (表示, Root) WP (,, 表示) ATT (美, 国防部长) ATT (国防部长, 盖茨) SBV (盖茨, 访问) ADV (将, 访问) ADV (于, 访问) ATT (2011 年, 14 日) ATT (1 月, 14 日) POB (14 日, 于) VOB (访问, 表示) VOB (韩国, 访问) WP (。, 表示)
依存句法分析结果可参考网址:https://ltp.readthedocs.io/zh_CN/latest/appendix.html
。
语义角色标注
语义角色标注是实现浅层语义分析的一种方式。在一个句子中,谓词是对主语的陈述或说明,指出“做什么”、“是什么”或“怎么样,代表了一个事件的核心,跟谓词搭配的名词称为论元。语义角色是指论元在动词所指事件中担任的角色。主要有:施事者(Agent)、受事者(Patient)、客体(Theme)、经验者(Experiencer)、受益者(Beneficiary)、工具(Instrument)、处所(Location)、目标(Goal)和来源(Source)等。示例的Python代码rolelabel.py如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import osfrom pyltp import Segmentor, Postagger, Parser, SementicRoleLabeller'data/cws.model' ) 'data/lexicon.txt' ) '据韩联社12月28日反映,美国防部发言人杰夫·莫莱尔27日表示,美国防部长盖茨将于2011年1月14日访问韩国。' 'data/pos.model' ) 'data/parser.model' ) 'data/pisrl.model' ) for role in roles:print (words[role.index], end=' ' )print (role.index, "" .join(["%s:(%d,%d)" % (arg.name, arg.range .start, arg.range .end) for arg in role.arguments]))
输出结果如下:
1 2 3 反映 4 A0 :(1 ,1 )A0 :(2 ,3 )11 MNR:(0 ,5 )A0 :(6 ,9 )TMP:(10 ,10 )A1 :(13 ,22 )21 A0 :(13 ,15 )ADV:(16 ,16 )TMP:(17 ,20 )A1 :(22 ,22 )
总结
本文介绍了中文NLP的一个杰出工具pyltp,并给出了该模块的各个功能的一个示例,希望能给读者一些思考与启示。本文到此结束,感谢大家阅读~
欢迎关注我的公众号
NLP奇幻之旅 ,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅 ”,笔者正在努力构建自己的技术社区。