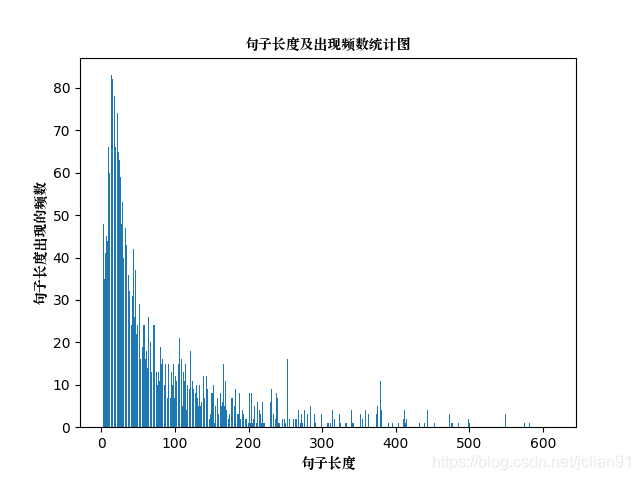
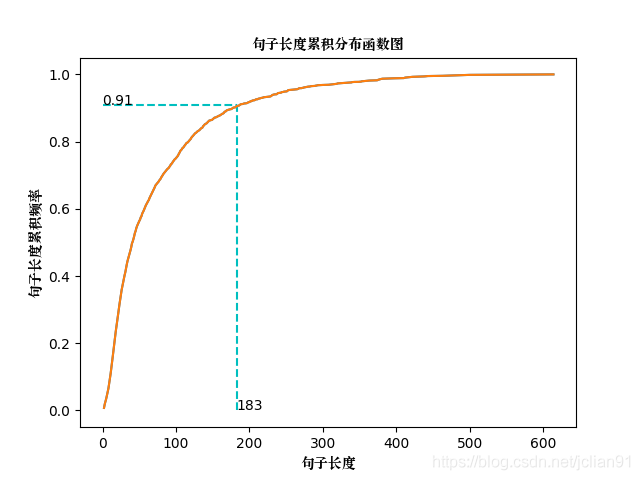
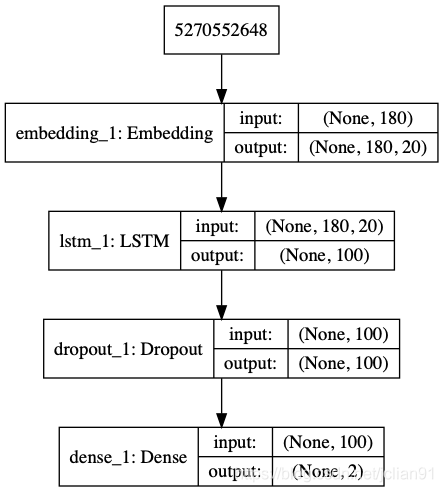
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
|
import pickle
import numpy as np
import pandas as pd
from keras.utils import np_utils, plot_model
from keras.models import Sequential
from keras.preprocessing.sequence import pad_sequences
from keras.layers import LSTM, Dense, Embedding, Dropout
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def load_data(filepath, input_shape=20):
df = pd.read_csv(filepath)
labels, vocabulary = list(df['label'].unique()), list(df['evaluation'].unique())
string = ''
for word in vocabulary:
string += word
vocabulary = set(string)
word_dictionary = {word: i+1 for i, word in enumerate(vocabulary)}
with open('word_dict.pk', 'wb') as f:
pickle.dump(word_dictionary, f)
inverse_word_dictionary = {i+1: word for i, word in enumerate(vocabulary)}
label_dictionary = {label: i for i, label in enumerate(labels)}
with open('label_dict.pk', 'wb') as f:
pickle.dump(label_dictionary, f)
output_dictionary = {i: labels for i, labels in enumerate(labels)}
vocab_size = len(word_dictionary.keys())
label_size = len(label_dictionary.keys())
x = [[word_dictionary[word] for word in sent] for sent in df['evaluation']]
x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)
y = [[label_dictionary[sent]] for sent in df['label']]
y = [np_utils.to_categorical(label, num_classes=label_size) for label in y]
y = np.array([list(_[0]) for _ in y])
return x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionary
def create_LSTM(n_units, input_shape, output_dim, filepath):
x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionary = load_data(filepath)
model = Sequential()
model.add(Embedding(input_dim=vocab_size + 1, output_dim=output_dim,
input_length=input_shape, mask_zero=True))
model.add(LSTM(n_units, input_shape=(x.shape[0], x.shape[1])))
model.add(Dropout(0.2))
model.add(Dense(label_size, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
plot_model(model, to_file='./model_lstm.png', show_shapes=True)
model.summary()
return model
def model_train(input_shape, filepath, model_save_path):
x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionary = load_data(filepath, input_shape)
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size = 0.1, random_state = 42)
n_units = 100
batch_size = 32
epochs = 5
output_dim = 20
lstm_model = create_LSTM(n_units, input_shape, output_dim, filepath)
lstm_model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=1)
lstm_model.save(model_save_path)
N = test_x.shape[0]
predict = []
label = []
for start, end in zip(range(0, N, 1), range(1, N+1, 1)):
sentence = [inverse_word_dictionary[i] for i in test_x[start] if i != 0]
y_predict = lstm_model.predict(test_x[start:end])
label_predict = output_dictionary[np.argmax(y_predict[0])]
label_true = output_dictionary[np.argmax(test_y[start:end])]
print(''.join(sentence), label_true, label_predict)
predict.append(label_predict)
label.append(label_true)
acc = accuracy_score(predict, label)
print('模型在测试集上的准确率为: %s.' % acc)
if __name__ == '__main__':
filepath = './corpus.csv'
input_shape = 180
model_save_path = './corpus_model.h5'
model_train(input_shape, filepath, model_save_path)
|