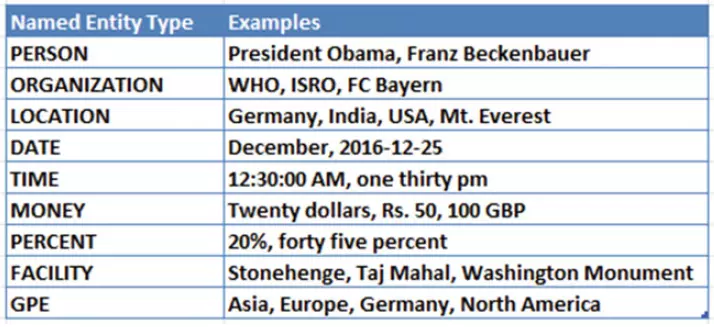
FIFA was founded in 1904 to oversee international competition among
the national associations of Belgium, Denmark, France, Germany, the
Netherlands, Spain, Sweden, and Switzerland. Headquartered in Zürich,
its membership now comprises 211 national associations. Member countries
must each also be members of one of the six regional confederations into
which the world is divided: Africa, Asia, Europe, North & Central
America and the Caribbean, Oceania, and South America.
defparse_document(document): document = re.sub('\n', ' ', document) ifisinstance(document, str): document = document else: raise ValueError('Document is not string!') document = document.strip() sentences = nltk.sent_tokenize(document) sentences = [sentence.strip() for sentence in sentences] return sentences
# sample document text = """ FIFA was founded in 1904 to oversee international competition among the national associations of Belgium, Denmark, France, Germany, the Netherlands, Spain, Sweden, and Switzerland. Headquartered in Zürich, its membership now comprises 211 national associations. Member countries must each also be members of one of the six regional confederations into which the world is divided: Africa, Asia, Europe, North & Central America and the Caribbean, Oceania, and South America. """
# tokenize sentences sentences = parse_document(text) tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences] # tag sentences and use nltk's Named Entity Chunker tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences] ne_chunked_sents = [nltk.ne_chunk(tagged) for tagged in tagged_sentences] # extract all named entities named_entities = [] for ne_tagged_sentence in ne_chunked_sents: for tagged_tree in ne_tagged_sentence: # extract only chunks having NE labels ifhasattr(tagged_tree, 'label'): entity_name = ' '.join(c[0] for c in tagged_tree.leaves()) #get NE name entity_type = tagged_tree.label() # get NE category named_entities.append((entity_name, entity_type)) # get unique named entities named_entities = list(set(named_entities))
# store named entities in a data frame entity_frame = pd.DataFrame(named_entities, columns=['Entity Name', 'Entity Type']) # display results print(entity_frame)
输出结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Entity Name Entity Type 0 FIFA ORGANIZATION 1 Central America ORGANIZATION 2Belgium GPE 3 Caribbean LOCATION 4 Asia GPE 5 France GPE 6 Oceania GPE 7 Germany GPE 8 South America GPE 9 Denmark GPE 10 Zürich GPE 11 Africa PERSON 12Sweden GPE 13 Netherlands GPE 14 Spain GPE 15Switzerland GPE 16North GPE 17 Europe GPE
import re from nltk.tag import StanfordNERTagger import os import pandas as pd import nltk
defparse_document(document): document = re.sub('\n', ' ', document) ifisinstance(document, str): document = document else: raise ValueError('Document is not string!') document = document.strip() sentences = nltk.sent_tokenize(document) sentences = [sentence.strip() for sentence in sentences] return sentences
# sample document text = """ FIFA was founded in 1904 to oversee international competition among the national associations of Belgium, Denmark, France, Germany, the Netherlands, Spain, Sweden, and Switzerland. Headquartered in Zürich, its membership now comprises 211 national associations. Member countries must each also be members of one of the six regional confederations into which the world is divided: Africa, Asia, Europe, North & Central America and the Caribbean, Oceania, and South America. """
sentences = parse_document(text) tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
# set java path in environment variables java_path = r'C:\Program Files\Java\jdk1.8.0_161\bin\java.exe' os.environ['JAVAHOME'] = java_path # load stanford NER sn = StanfordNERTagger('E://stanford-ner-2018-10-16/classifiers/english.muc.7class.distsim.crf.ser.gz', path_to_jar='E://stanford-ner-2018-10-16/stanford-ner.jar')
# tag sentences ne_annotated_sentences = [sn.tag(sent) for sent in tokenized_sentences] # extract named entities named_entities = [] for sentence in ne_annotated_sentences: temp_entity_name = '' temp_named_entity = None for term, tag in sentence: # get terms with NE tags if tag != 'O': temp_entity_name = ' '.join([temp_entity_name, term]).strip() #get NE name temp_named_entity = (temp_entity_name, tag) # get NE and its category else: if temp_named_entity: named_entities.append(temp_named_entity) temp_entity_name = '' temp_named_entity = None
# get unique named entities named_entities = list(set(named_entities)) # store named entities in a data frame entity_frame = pd.DataFrame(named_entities, columns=['Entity Name', 'Entity Type']) # display results print(entity_frame)
输出结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Entity Name Entity Type 01904DATE 1 Denmark LOCATION 2 Spain LOCATION 3 North & Central America ORGANIZATION 4 South America LOCATION 5 Belgium LOCATION 6 Zürich LOCATION 7 the Netherlands LOCATION 8 France LOCATION 9 Caribbean LOCATION 10 Sweden LOCATION 11 Oceania LOCATION 12 Asia LOCATION 13 FIFA ORGANIZATION 14 Europe LOCATION 15 Africa LOCATION 16 Switzerland LOCATION 17 Germany LOCATION
可以看到,在Stanford
NER的帮助下,NER的实现效果较好,将Africa识别为LOCATION,将1904识别为时间(这在NLTK中没有识别出来),但还是对North
& Central America识别有误,将其识别为ORGANIZATION。