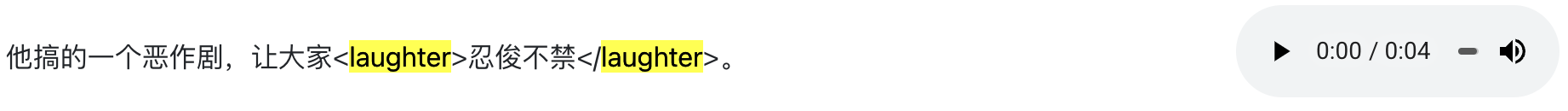本文将会介绍OpenAI中的模型系列模型,包括语音转文本(Text to
Speech),文本转语音(Speech to Text)以及语音多模态(Audio
Generation)模型。
笔者初次接触语音模型,因此首先接触下OpenAI中的语音模型。本文将会介绍OpenAI中的模型系列模型,包括语音转文本(Text
to Speech, TTS),文本转语音(Speech to Text, STT)以及语音多模态(Audio
Generation)模型。
本文中的两个演示音频文件来自网站:https://funaudiollm.github.io/
,内容截图如下:
audio1.png
audio2.png
语音转文本(TTS)
语音转文本(TTS,Text to
Speech)是一种将语音信号转换为对应文本的技术,广泛应用于语音助手、字幕生成和智能客服等领域。
OpenAI官方TTS API只有Whisper-1模型可以使用。
Python代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import osfrom dotenv import load_dotenvfrom openai import OpenAI"OPENAI_API_KEY" ))open ("./style6.wav" , "rb" )"whisper-1" ,print (transcription.text)
laughter2.wav 输出文本:
他搞的一个恶作剧 让大家人尽不尽
style6.wav 输出文本:
I win really struggling to stay calm right now because what you did
was totally out of line.
文本转语音(STT)
文本转语音(TTS,Text-to-Speech)是一种将文本转换为自然语音的技术,广泛应用于语音助手、无障碍阅读和智能播报等领域。
OpenAI的STT API内置了六种语音(voice)模式。
Python代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import osfrom dotenv import load_dotenvfrom openai import OpenAI"OPENAI_API_KEY" ))"Hi, Nice weather today. Shall we go out for a walk?" "tts-1" ,"alloy" ,input =text,"output.mp3" )
语音多模态(Audio Generation)
OepnAI的语音多模态模型(GPT-4o
audio系列)接受语音输入或输出,支持多模态(语音、文本)。它支持的模式如下:
Text in → text + audio out
Audio in → text + audio out
Audio in → text out
Text + audio in → text + audio out
Text + audio in → text out
以Text + audio in → text out模式为例,Python代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import osimport base64from dotenv import load_dotenvfrom openai import OpenAI"OPENAI_API_KEY" ))"style6.wav" with open (audio_file, "rb" ) as f:"utf-8" )"gpt-4o-audio-preview" ,"text" ],"role" : "user" ,"content" : ["type" : "text" ,"text" : "对下面的音频文件进行打分,综合考虑音频说话内容和情感语气等因素,给出你的评价。" "分数为0-1之间的一位小数,0代表消极评价,1代表积极评价。" "输出结果为json格式,里面包含score和reason字段,其中score为评分,reason为评价理由。" "type" : "input_audio" ,"input_audio" : {"data" : encoded_string,"format" : "wav" print (completion.choices[0 ].message.content)
输出结果如下:
{"score": 0.3, "reason": "The speaker expressed strong negative
emotions and frustration, indicating a negative experience or
interaction."}
以``模式为例,Python代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import osimport base64from dotenv import load_dotenvfrom openai import OpenAI"OPENAI_API_KEY" ))"laughter2.wav" with open (audio_file, "rb" ) as f:"utf-8" )"gpt-4o-audio-preview" ,"text" , "audio" ],"voice" : "alloy" , "format" : "wav" },"role" : "user" ,"content" : ["type" : "text" ,"text" : "这段音频文件中的内容和说话语气是怎样的?" "type" : "input_audio" ,"input_audio" : {"data" : encoded_string,"format" : "wav" "audio_out.wav" with open (audio_file_out, "wb" ) as f:0 ].message.audio.data)
将此段语音转化为文本,内容如下:
这段音频文件中的内容是描述某人搞了一个恶作剧
出乎意料地让大家陷入惊讶的情景 从语气来看 应该是略带调侃和幽默的感觉
总结
本文介绍了OpenAI的语音模型,包括语音转文本(TTS)、文本转语音(STT)以及语音多模态(Audio
Generation)。
其中,TTS使用Whisper-1模型将音频转换为文本,STT则利用OpenAI的API将文本合成自然语音,并支持多种语音模式。此外,文章还探讨了GPT-4o
audio系列的多模态能力,能够接受文本和音频输入,并生成文本或语音输出。通过具体的Python代码示例,展示了如何调用这些模型进行语音转换、评分和语气分析等任务。
欢迎关注我的公众号NLP奇幻之旅 ,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅 ”,笔者正在努力构建自己的技术社区。