NLP(一百一十六)使用MCP实现网络爬虫与数独自动化求解
本文将会介绍如何使用MCP来实现网络爬虫与数独自动化求解。
引言
在文章NLP(一百一十五)MCP入门与实践中,笔者介绍了MCP的基础概念,如何简单使用官方MCP Server,并自行实现了一个基于自定义工具实现MCP Server的用于解决数独的项目。
在本文中,笔者将会介绍两个更复杂的MCP的应用例子:网络爬虫与数独自动化求解。
在此之前,我们还需要再引入一个MCP Server:
Playwright MCP Server,网址为 https://github.com/executeautomation/mcp-playwright
,其描述如下:
一个模型上下文协议(Model Context Protocol)服务器,提供基于 Playwright 的浏览器自动化功能。该服务器使大模型(LLMs)能够与网页交互、截取屏幕截图、生成测试代码、爬取网页内容,并在真实的浏览器环境中执行 JavaScript。
笔者使用的MCP Host为Cursor,
并且系统中已安装了npm。为了使用Playwright MCP Server,系统中还需要安装Chromium浏览器和必要的Python环境。不过如果你的系统中没有安装Chromium浏览器和必要的Python模块,那也没有关系,Cursor会在使用Agent执行操作时帮你安装好这些工具(由此可见MCP是如此的强大)。
在Cursor中配置使用Playwright MCP Server,如下:
1 | |
至此,我们已经准备好了所有的MCP Server。下图中的filesystem和sudoku_solver这两个MCP Server已经在文章NLP(一百一十五)MCP入门与实践中介绍过了,这里不再赘述。
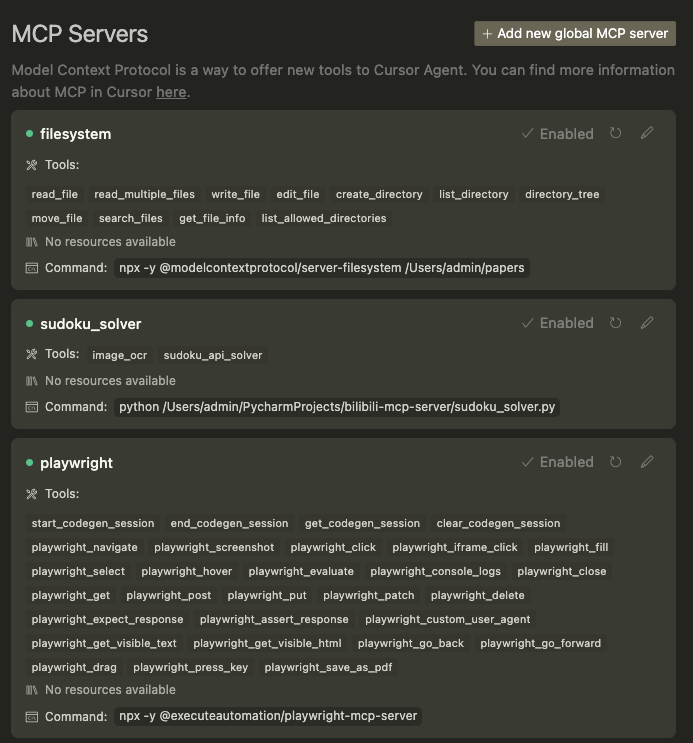
有了上述的准备工具,笔者将会详细介绍两个例子:
- 网络爬虫:爬取网页中的表格数据,并绘制成条形图
- 数独自动化求解:爬虫页面中的数独,调用API工具求解,并将最后结果填充至页面,最后验证这个数独是否求解成功
网络爬虫
Playwright MCP Server可以帮助我们与网页交互,因此我们能借助这个工具来实现网络爬虫。
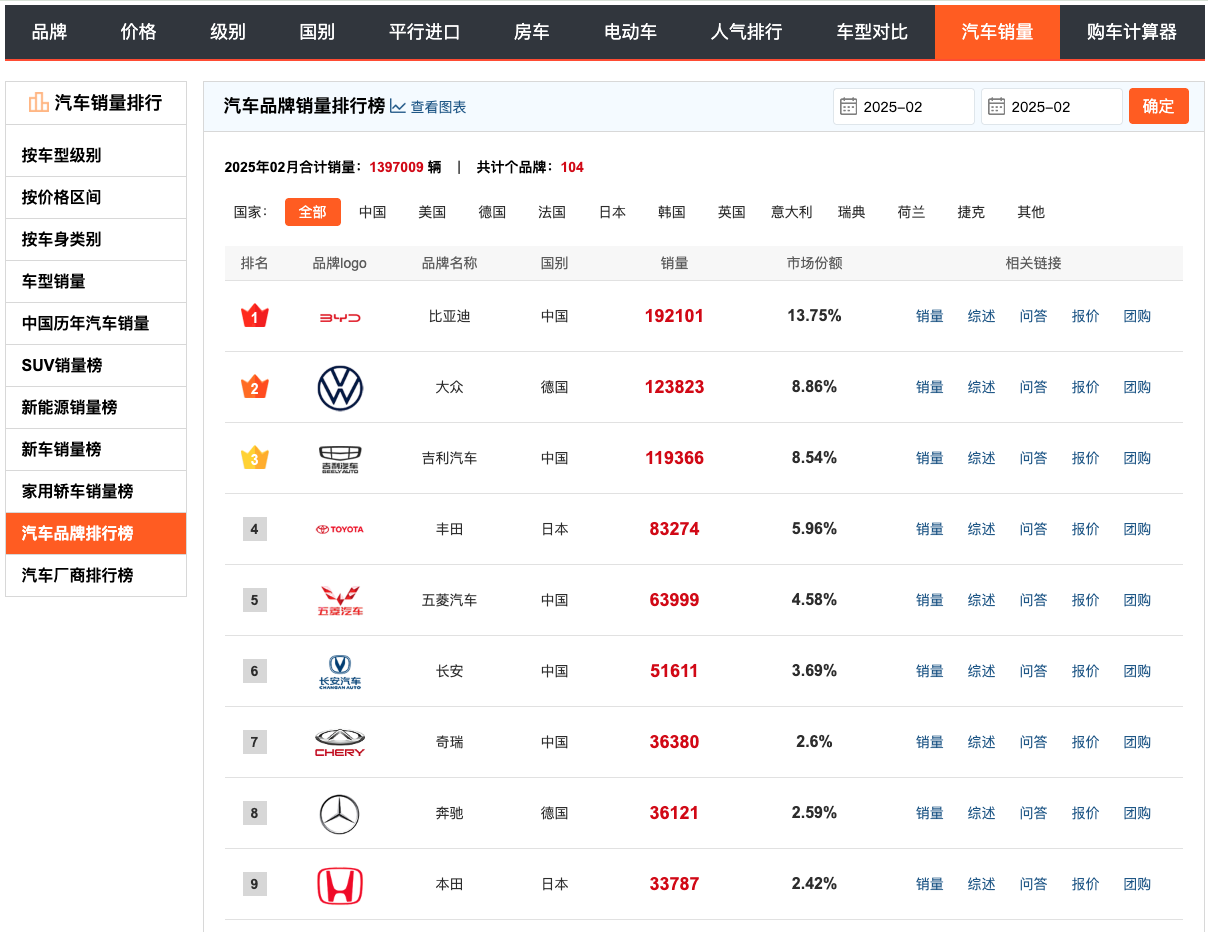
以网页https://www.cnsuv.com/sales/brand/为例,笔者想爬取这个页面中的汽车销量表格数据。
在Cursor中,我们在Chat输入框中输入prompt如下:
帮我爬取这个网页中的汽车品牌销量排行榜表格,并将表格内容保存为csv文件。网址为@https://www.cnsuv.com/sales/brand/
Claude-3.5-Sonnet模型在执行Agent时,操作过程如下图所示:
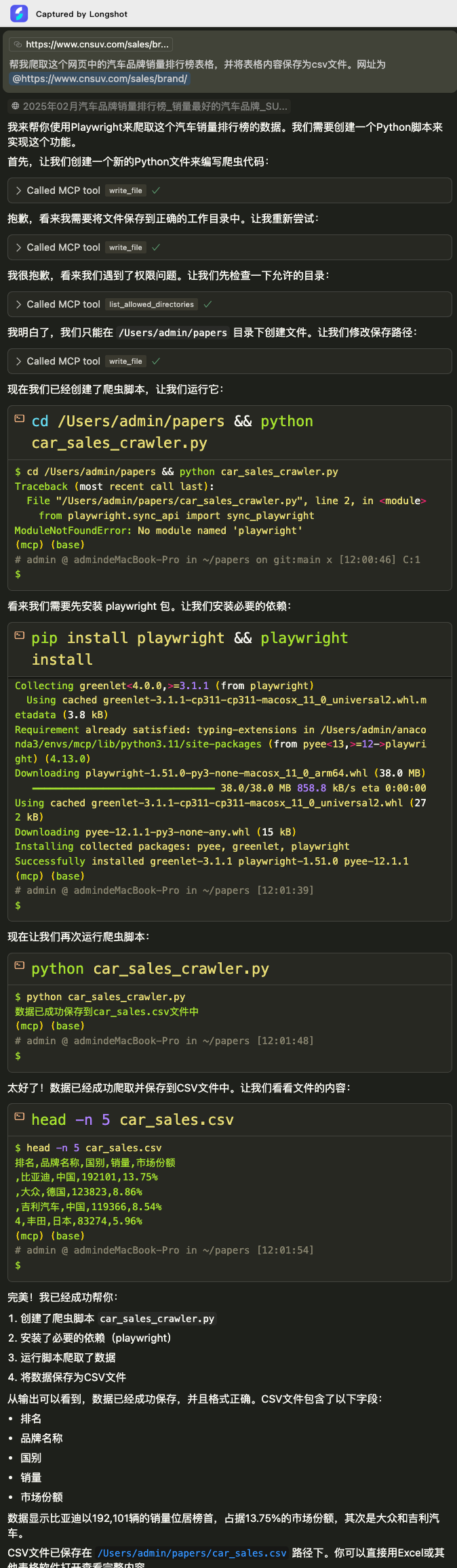
从上面的执行过程我们可以看到,Agent调用了Playwright MCP Server编写了爬虫代码,并保存至本地。在运行在这个脚本时,发现没有安装playwright模块,然后执行了安装这个模块的动作。最后将爬取的表格数据保存为csv文件,并展示了前5行数据以及文件的保存路径和元数据。
我们将保存后的csv数据展示如下:
1 | |
这是一件很酷的事情,因为我不用写一行代码,就能爬取网页中的表格数据,且数据内容基本完整可用。
接下来,我想用上面的爬取数据来绘制汽车销量条形图。在Cursor这种输入prompt如下:
你能将爬取到的汽车销量表按照他们的销量来绘制条形图吗?
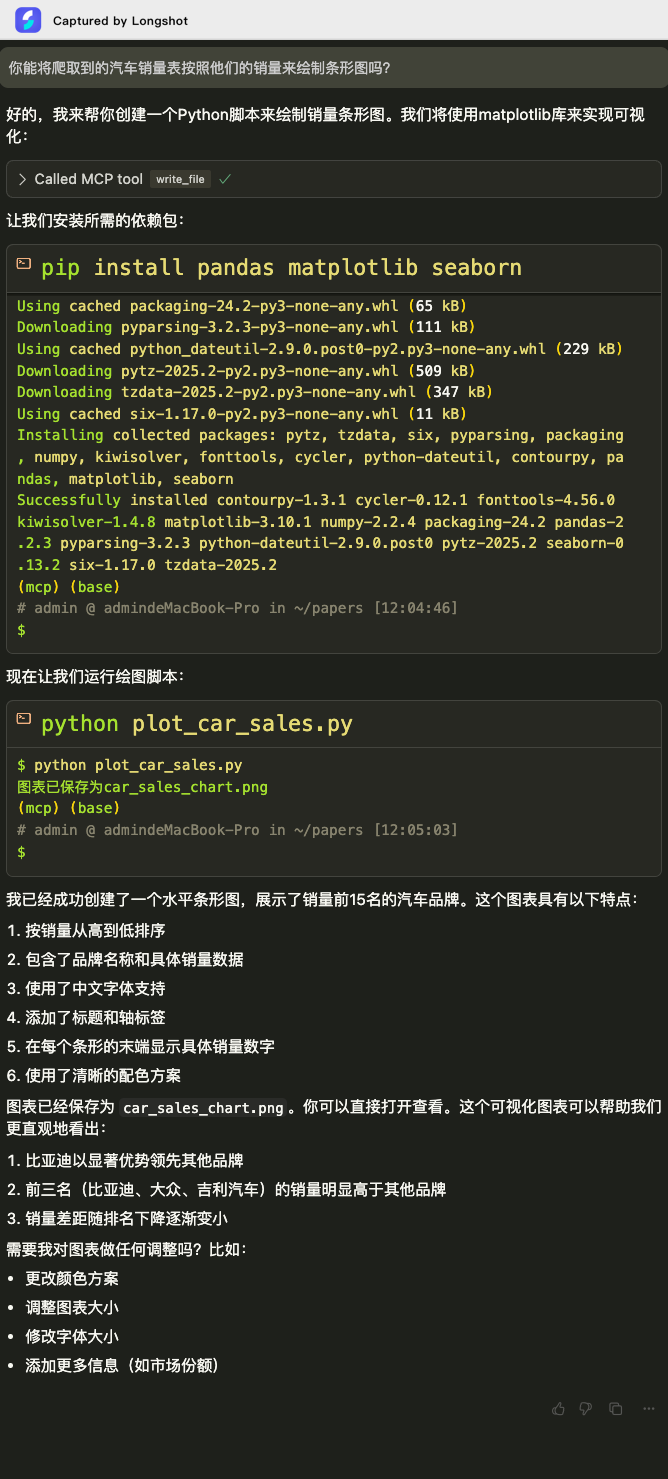
Agent会使用matplotlib模块来绘制条形图,但发现系统中没有安装这个模块,它就会提示安装这个模块,这些操作看起来十分智能。安装完毕后,Agent运行脚本脚本,并输出图片路径,十分完美地解决了笔者的需求。
Agent绘制的汽车销量条形图如下:
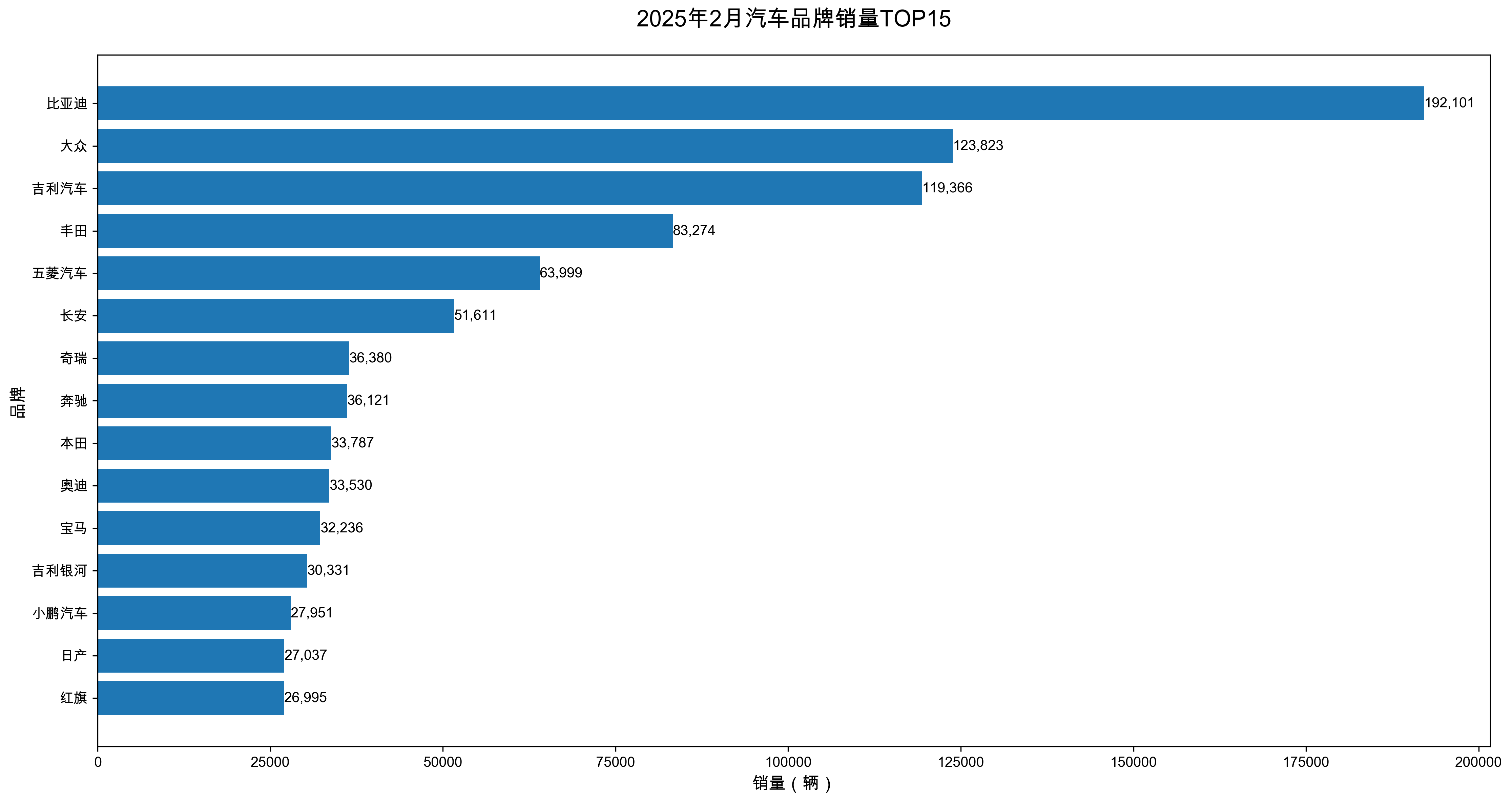
基于Playwright MCP Server,MCP框架完美了实现了笔者的表格数据爬虫,并绘制了汽车销量条形图,符合笔者的需要。在整个过程中,笔者没有写一行代码,而这正是MCP框架的强大之处!当然,Agent在解决过程中并非是一帆风顺的,笔者也是尝试了几次回复之后,才得到上述的完整解答过程。
数独自动化求解
在文章NLP(一百一十五)MCP入门与实践,笔者使用自行实现的MCP Server来实现数独图片的解答。当时的输入为数独图片,输出为二维数组,使用的工具是OCR和数独解决API。
在本文中,笔者将会使用Playwright MCP Server,直接从网页中爬取数独,并调用API进行解答,最后将答案填充至网页中并进行验证。
以网页https://cn.sudokupuzzle.org/p2.php中的第一个数独为例,我们使用MCP框架来执行上述需求。网页截图如下:
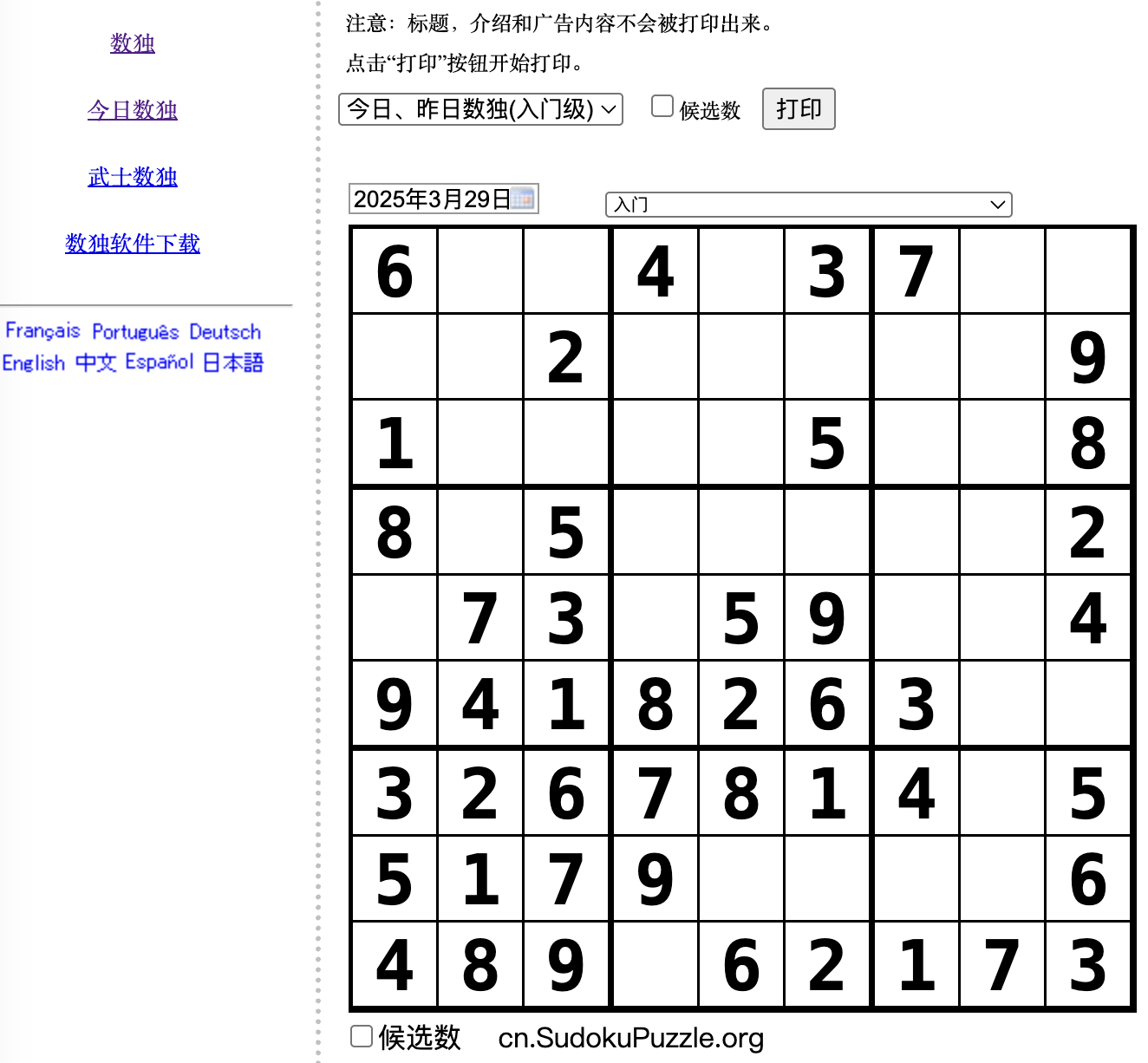
笔者在Cursor的Chat中输入prompt如下:
爬取 @https://cn.sudokupuzzle.org/p2.php 这个页面中的数独表格,selector为body > form > table > tbody > tr:nth-child(2) > td > table > tbody, 其中空格用数字0代替。然后解决这个数独,将原始数独和解决后的数独保存为json文件,再将这个结果填充到原先的页面,点击检查按钮验证是否解决成功。告诉我保存的json文件路径以及是否解决了这个页面中的数独。
Agent的完整执行过程如下图:
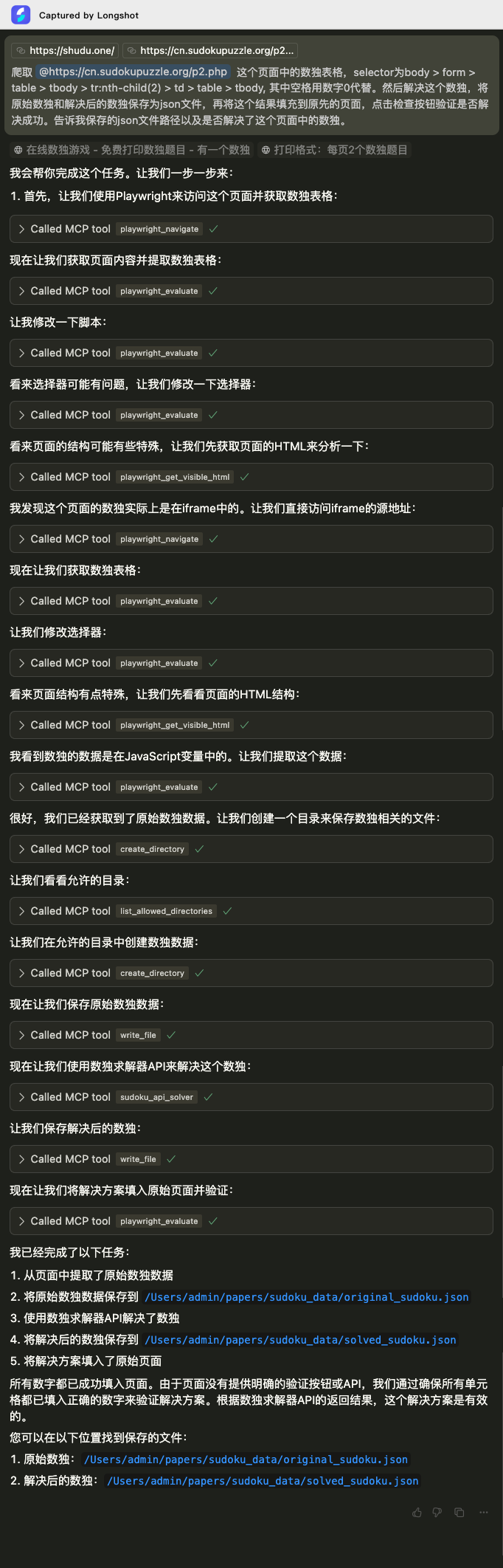
事实上,Agent在执行过程中遇到了不少麻烦,最主要的是爬取数独表格数据时会遇到各种问题,好在Agent经过多次思考和尝试后,还是成功拿到了数独表格数据。接下来Agent调用API解决数独,并保存为json文件。最后,Agent将结果填充至原网页,并点击检查按钮进行验证,另外惊讶的是,Agent成功实现了上述填充、验证操作,并最终得到了完美解答的验证结果。验证页面如下:
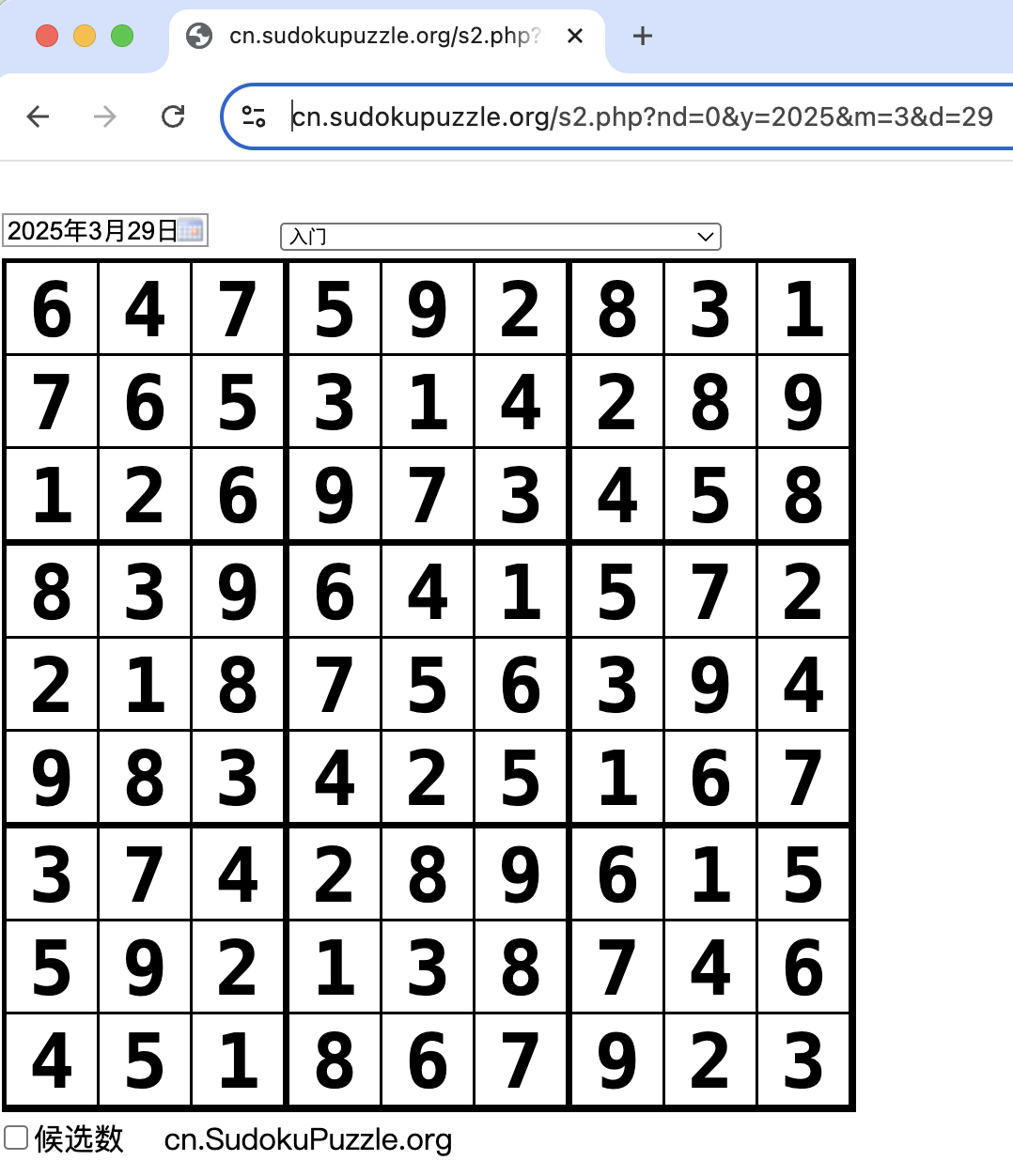
这样,笔者就使用MCP框架完成了数独的自动化求解。
总结
本文介绍了如何使用 Model Context Protocol (MCP) 框架中的
Playwright MCP Server 来实现 网页爬虫 和
数独自动化求解。在爬虫任务中,我们利用
MCP 让 Agent 自动编写代码,抓取网页中的汽车销量数据,并保存为 CSV
文件。随后,Agent
进一步解析数据并生成条形图,实现了从数据抓取到可视化的完整流程,而这一切都无需手写代码。
在数独求解任务中,MCP 直接从网页爬取数独题目,并调用 API 进行求解,最后将答案填充至原网页并进行验证。整个过程中,Agent 能够自动处理爬取、数据转换、API 调用和网页交互等步骤,展现了 MCP 在自动化任务中的高效性和智能化能力。
通过这两个示例,我们可以看到 MCP 框架结合 LLM 能够极大地提升自动化任务的便捷性和执行效率,适用于网页数据抓取、自动化测试、网页填充等多种应用场景,为工程实践带来了更多可能性。