import os import cohere from uuid import uuid4 from dotenv import load_dotenv from openai import OpenAI from langfuse import Langfuse from operator import itemgetter
from utils.db_client import es_client, milvus_client
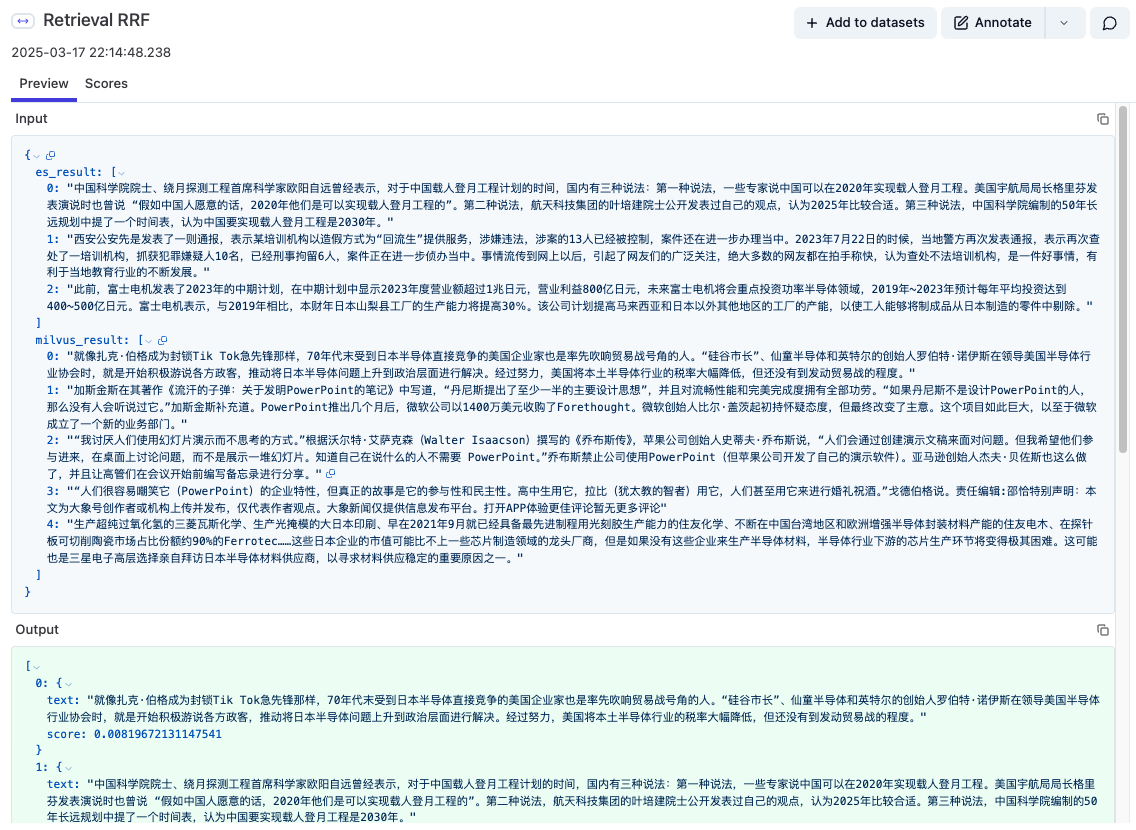
# sort the es and milvus retrieval results by rrf defretrieval( self ) -> list[dict[str, float]]: """ Sort the ES and Milvus retrieval results by RRF. :return: """ es_result = [_["content"] for _ in self._es_retrieval()] milvus_result = [_["content"] for _ in self._milvus_retrieval()] doc_lists = [es_result, milvus_result] # Create a union of all unique documents in the input doc_lists all_documents = set() for doc_list in doc_lists: for doc in doc_list: all_documents.add(doc)
# Initialize the RRF score dictionary for each document rrf_score_dic = {doc: 0.0for doc in all_documents}
# Calculate RRF scores for each document weights = [0.5, 0.5] c = 60 for doc_list, weight inzip(doc_lists, weights): for rank, doc inenumerate(doc_list, start=1): rrf_score = weight * (1 / (rank + c)) rrf_score_dic[doc] += rrf_score
# Sort documents by their RRF scores in descending order sorted_documents = sorted(rrf_score_dic.items(), key=itemgetter(1), reverse=True) # get top 5 documents result = [] for i inrange(len(sorted_documents)): text, score = sorted_documents[i] result.append({"text": text, "score": score}) # add langfuse tracing self.trace.span( name="Retrieval RRF", input={"es_result": es_result, "milvus_result": milvus_result}, output=result ) return result
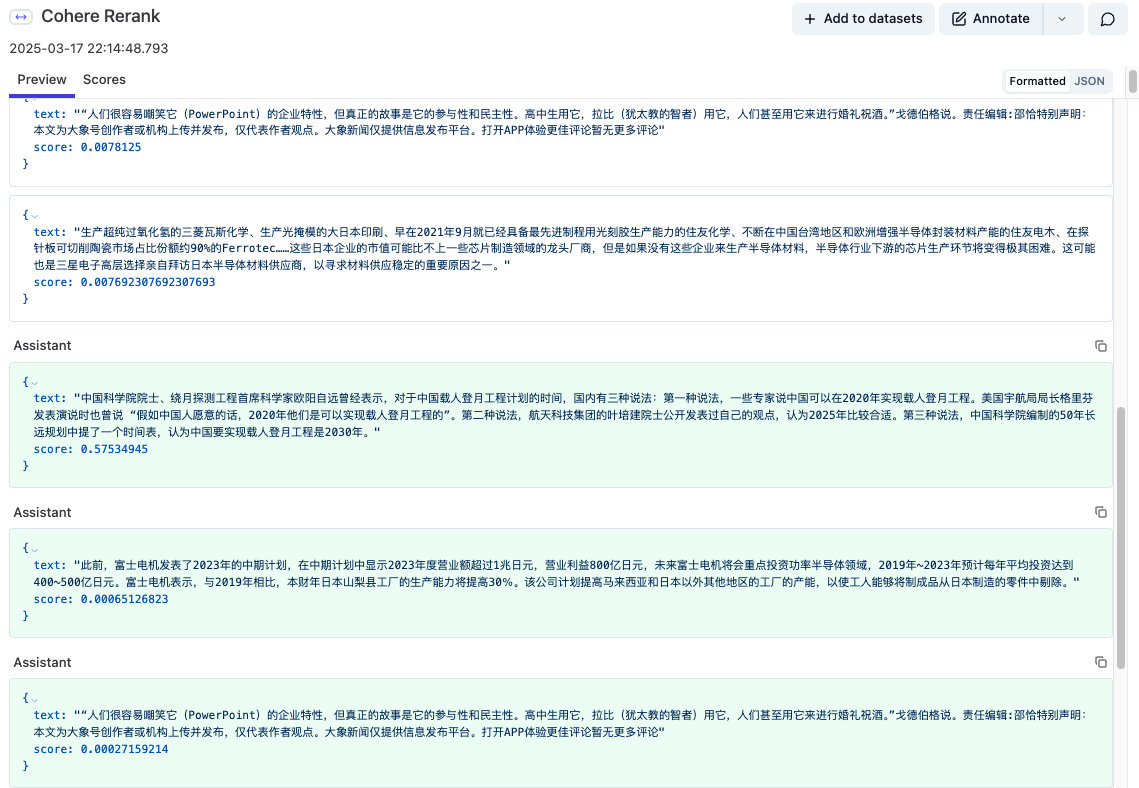
重排
使用Cohere的Rerank模型对上述融合召回结果进行精排。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
defrerank(self, before_rerank_contents): documents = [_["text"] for _ in before_rerank_contents] cohere_client = cohere.Client(os.getenv("COHERE_API_KEY", "")) results = cohere_client.rerank(model="rerank-multilingual-v2.0", query=self.query, documents=documents, top_n=5) after_rerank_contents = [] for hit in results: after_rerank_contents.append({"text": hit.document['text'], "score": hit.relevance_score}) self.trace.span( name="Cohere Rerank", input=before_rerank_contents, output=after_rerank_contents ) return after_rerank_contents