1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
| import gradio as gr
import numpy as np
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
def chunk_by_sentences(input_text: str, tokenizer: callable, separator: str):
inputs = tokenizer(input_text, return_tensors='pt', return_offsets_mapping=True)
punctuation_mark_id = tokenizer.convert_tokens_to_ids(separator)
print(f"separator: {separator}, punctuation_mark_id: {punctuation_mark_id}")
sep_id = tokenizer.eos_token_id
token_offsets = inputs['offset_mapping'][0]
token_ids = inputs['input_ids'][0]
chunk_positions = [
(i, int(start + 1))
for i, (token_id, (start, end)) in enumerate(zip(token_ids, token_offsets))
if token_id == punctuation_mark_id
and (
token_offsets[i + 1][0] - token_offsets[i][1] >= 0
or token_ids[i + 1] == sep_id
)
]
chunks = [
input_text[x[1]: y[1]]
for x, y in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)
]
span_annotations = [
(x[0], y[0]) for (x, y) in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)
]
return chunks, span_annotations
def late_chunking(model_output, span_annotation, max_length=None):
token_embeddings = model_output[0]
outputs = []
for embeddings, annotations in zip(token_embeddings, span_annotation):
if max_length is not None:
annotations = [
(start, min(end, max_length - 1))
for (start, end) in annotations
if start < (max_length - 1)
]
pooled_embeddings = [
embeddings[start:end].sum(dim=0) / (end - start)
for start, end in annotations
if (end - start) >= 1
]
pooled_embeddings = [
embedding.detach().cpu().numpy() for embedding in pooled_embeddings
]
outputs.append(pooled_embeddings)
return outputs
def embedding_retriever(query_input, text_input, separator):
chunks, span_annotations = chunk_by_sentences(text_input, tokenizer, separator)
print(f"chunks: ", chunks)
inputs = tokenizer(text_input, return_tensors='pt', max_length=4096, truncation=True)
model_output = model(**inputs)
late_chunking_embeddings = late_chunking(model_output, [span_annotations])[0]
query_inputs = tokenizer(query_input, return_tensors='pt')
query_embedding = model(**query_inputs)[0].detach().cpu().numpy().mean(axis=1)
traditional_chunking_embeddings = model.encode(chunks)
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
naive_embedding_score_dict = {}
late_chunking_embedding_score_dict = {}
for chunk, trad_embed, new_embed in zip(chunks, traditional_chunking_embeddings, late_chunking_embeddings):
naive_embedding_score_dict[chunk] = round(cos_sim(query_embedding, trad_embed).tolist()[0], 4)
late_chunking_embedding_score_dict[chunk] = round(cos_sim(query_embedding, new_embed).tolist()[0], 4)
naive_embedding_order = sorted(
naive_embedding_score_dict.items(), key=lambda x: x[1], reverse=True
)
late_chunking_order = sorted(
late_chunking_embedding_score_dict.items(), key=lambda x: x[1], reverse=True
)
df_data = []
for i in range(len(naive_embedding_order)):
df_data.append([i+1, naive_embedding_order[i][0], naive_embedding_order[i][1],
late_chunking_order[i][0], late_chunking_order[i][1]])
return df_data
if __name__ == '__main__':
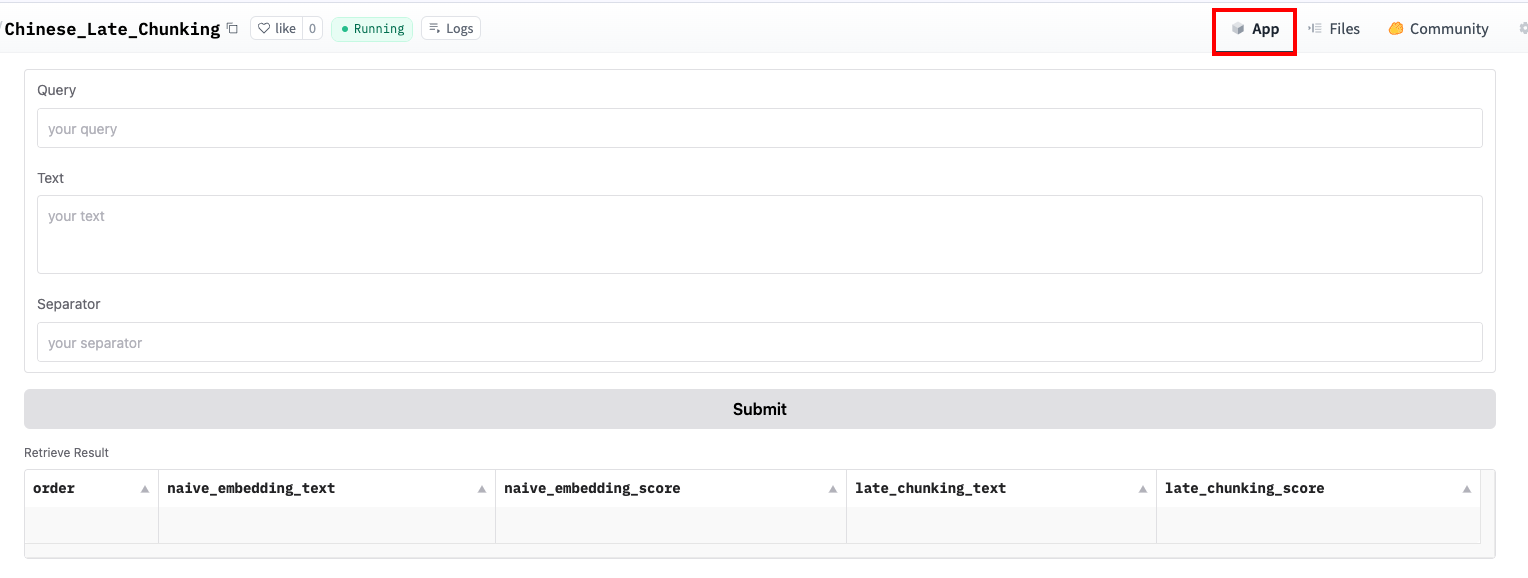
with gr.Blocks() as demo:
query = gr.TextArea(lines=1, placeholder="your query", label="Query")
text = gr.TextArea(lines=3, placeholder="your text", label="Text")
sep = gr.TextArea(lines=1, placeholder="your separator", label="Separator")
submit = gr.Button("Submit")
result = gr.DataFrame(headers=["order", "naive_embedding_text", "naive_embedding_score",
"late_chunking_text", "late_chunking_score"],
label="Retrieve Result",
wrap=True)
submit.click(fn=embedding_retriever,
inputs=[query, text, sep],
outputs=[result])
demo.launch()
|