NLP(一百二十一)用飞书机器人打造你的专属AI新闻推送助手(含代码实战)
本文将会介绍如何在飞书群中,使用群机器人实现每日AI新闻推送。
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。

引言
在我们的日常工作中,不少公司都会选择飞书来作为其沟通工具。笔者在了解了飞书群中的群机器人后,萌生了一个想法:能不能每天定时爬取AI新闻,并使用大模型进行总结,然后发送至飞书群中。这样,对于我们关心的AI新闻,不用每一篇都精读,通过总结后的内容了解每日AI动态,对于特别感兴趣的文章,也可以点击进去细读。
首先,笔者先介绍下如何在飞书群中,使用Python来操作群机器人发送文本消息和富文本消息。
飞书群机器人
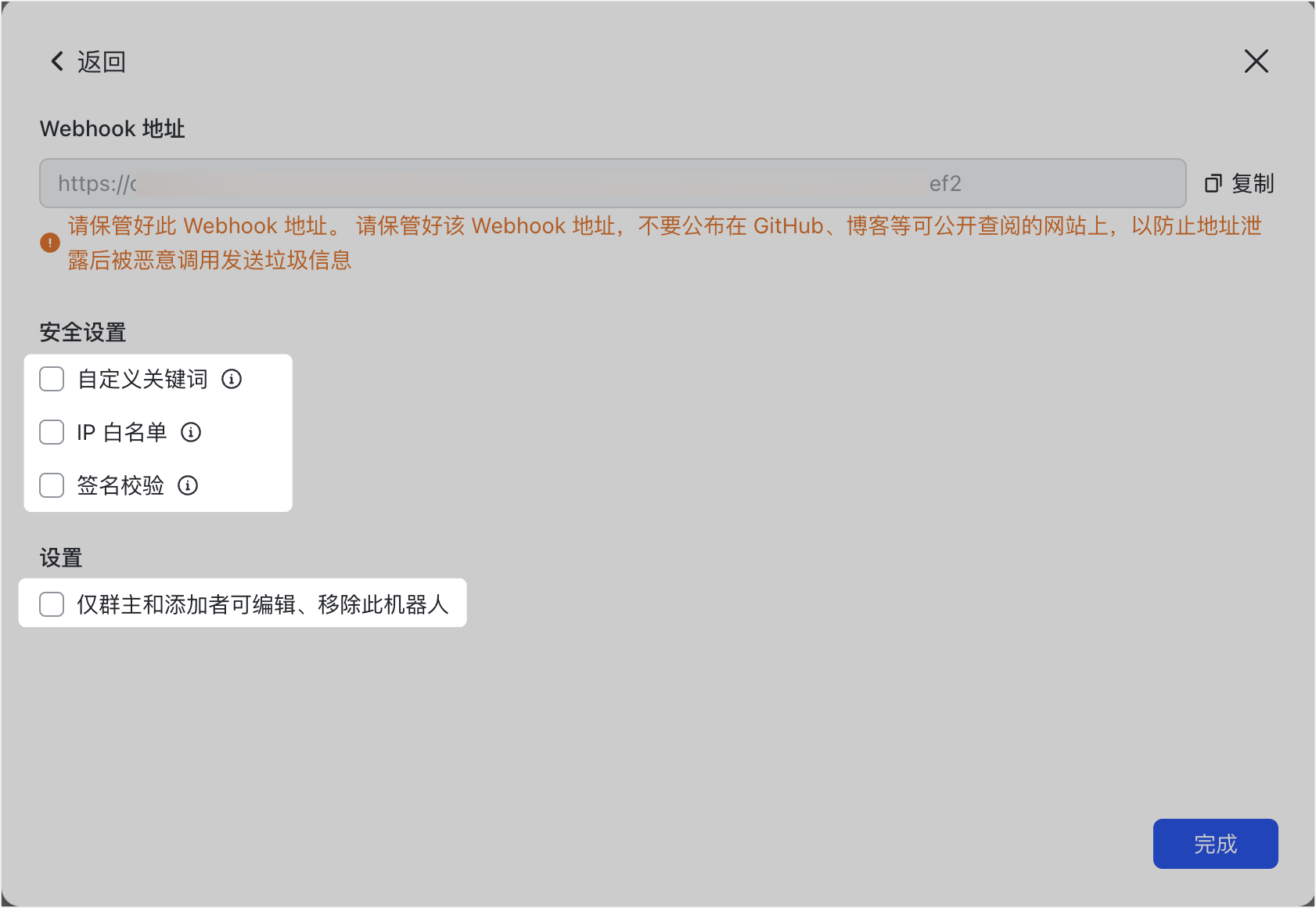
在飞书群众,点击 设置 -> 群机器人 —> 添加机器人 -> 自定义机器人,完成信息配置后,系统会自动生成该机器人的API URL和Secret(需手动开启),如下图所示:
使用Python操作该机器人在对应群众发送文本消息,代码如下:
1 | |
效果图如下:
发送富文本消息的代码如下:
1 | |
效果图如下:

每日AI新闻总结
笔者想在自己创建的飞书群中,每天定时爬取关注网站当天的AI新闻,通过大模型进行总结,发送至飞书群中,省时省力。
以techcrunch网站为例,它每天都会推送不少AI新闻,也是笔者关注的网站之一。
整体流程如下:
- 使用Docker启动Python定时任务程序
- 每天定时爬取对应网站当天的AI新闻
- 使用DeepL翻译文章标题,使用GPT-4o总结文章内容
- 通过飞书机器人发送至飞书群中
每日定时爬取网站的文章,并翻译标题和总结内容的Python程序如下:
1 | |
启动定时任务,通过群机器人将上述内容发送至飞书群中,Python代码如下:
1 | |
为了保证该任务每天能顺利执行,最好是将该服务部署至云服务器。但笔者没有这个条件,因此采用Docker来实现,这样只要笔者每天的电脑开着(上班当然要开电脑喽!),就能顺利执行。
Dockerfile设置如下:
1 | |
Docker镜像打包参考Dockerfile, 打包和执行命令如下:
1 | |
以今日为例(由于与美国的时差,故发送的是昨日AI新闻),效果图如下:

笔者特意将上述内容的文本部分放在最后的附录中,以飨读者。
总结
上述代码已开源至Github,网址为:https://github.com/percent4/ai_news_bot
本文介绍了笔者业余时间做的一个项目,也算是大模型在自己日常生活工作中的一个应用场景。
参考网站
- 在群组中使用机器人: https://www.feishu.cn/hc/zh-CN/articles/360024984973-%E5%9C%A8%E7%BE%A4%E7%BB%84%E4%B8%AD%E4%BD%BF%E7%94%A8%E6%9C%BA%E5%99%A8%E4%BA%BA
- Python实现飞书机器人定时发送文本、图片等群消息: https://blog.csdn.net/tyh_keephunger/article/details/129346297
- TechCrunch: https://techcrunch.com/
- ai_news_bot: https://github.com/percent4/ai_news_bot
附录
2025-05-09 今日AI新闻
- 埃隆-马斯克(Elon Musk)的一位长期风险投资人在据称被解雇后起诉他的前雇主
Josh Raffaelli起诉前雇主Brookfield资产管理公司,指控该公司隐瞒疫情相关房地产损失,并因他向SEC提交举报而解雇他。诉讼涉及欺诈和贿赂指控,Brookfield否认不当行为。此外,Raffaelli称Brookfield未按约定购买他获得购买权的马斯克公司股票。Raffaelli过去支持过马斯克的公司如SpaceX,并在马斯克收购推特时提供支持。Brookfield此前关闭了Raffaelli管理的风投部门。
- 微软总裁表示禁止微软员工使用 DeepSeek 应用程序
微软禁止员工使用DeepSeek,原因是数据安全和宣传问题。微软副董事长Brad Smith在参议院听证会上表示,由于数据可能存储在中国,并可能受到中方宣传的影响,微软未将DeepSeek列入其应用商店。DeepSeek存储用户数据在中国服务器,需遵循中国法律,与情报机构合作。尽管微软在Azure云服务上提供了DeepSeek的R1模型,但它修改了模型以去除“有害效果”。微软未将其直接应用于Windows应用商店,强调数据安全的重要性。
- 韩国电信巨头 SKT 数据泄露事件时间表
今年4月,韩国电信巨头SK电信遭遇网络攻击,导致约2300万客户的个人数据被盗。受影响客户中,已有约25万人更换服务提供商,若免除解约费,该数字可能增至250万。公司可能在三年内损失达50亿美元。调查显示,25类个人信息被泄露,包括手机号码和USIM数据等。SK电信已提供SIM卡保护和替换服务,并与多方展开调查。攻击可能与中国支持的黑客有关,涉及多个国家和行业。SK集团主席已就数据泄露事件道歉。
- 曙光公司将增加夜间行车和新路线,加强无人驾驶卡车服务
自动驾驶技术公司Aurora Innovation计划扩展其无人驾驶卡车业务,包括夜间驾驶和在恶劣天气条件下运行。到2025年下半年,Aurora计划在达拉斯至休斯顿的路线基础上扩展到埃尔帕索和菲尼克斯,并实现收入增长。公司已完成4,000多英里的无人驾驶测试,并计划到2025年底运营"数十辆"卡车。Aurora联合创始人兼首席产品官Sterling Anderson辞职,公司预计2025年收入将达到中等个位数百万。
- Aurora 联合创始人斯特林-安德森将离开这家自动驾驶卡车初创公司
Aurora联合创始人Sterling Anderson宣布辞职,此时恰逢公司刚在德克萨斯推出自动驾驶卡车服务。他将于6月1日正式离职,并于8月31日退出董事会。公司声明称,辞职与任何运营或政策分歧无关。Anderson将赴一家全球知名公司担任高级领导角色。他表示,虽然离开Aurora是艰难决定,但公司已经达到了重要发展节点,技术和团队已准备就绪。Aurora于2021年通过特殊目的收购公司上市,目前专注于自动驾驶卡车领域。
- Appfigures:苹果去年从美国应用商店佣金中获利超过 100 亿美元
根据Appfigures分析,2024年苹果美国App Store收入超过100亿美元。2020至2024年间,该收入翻倍,开发者总收入达336.8亿美元,扣除苹果佣金后所得为235.7亿美元。苹果逐渐放宽对App Store外交易的限制,因法院裁定苹果在执行禁令时妨碍竞争。尽管苹果计划上诉,但新规则允许开发者添加外部支付链接,例如Spotify和Amazon Kindle已受益。苹果坚持佣金政策,并声称相关限制使其遭受财务损失。
- ChatGPT 的深度研究工具有了 GitHub 连接器,可回答有关代码的问题
OpenAI推出了增强版ChatGPT深度研究工具,新增对GitHub代码库的分析功能。这一新功能允许用户提出代码库和工程文档相关问题,并帮助分解产品规格、总结代码结构等。该服务目前在测试阶段,将逐步对ChatGPT Plus、Pro和Team用户开放,并计划对企业和教育版开放。OpenAI还提供了定制模型的微调选项,并投资于编程工具开发,例如购买AI编码助手Windsurf。该功能被视为节省时间的工具,而非专家替代品。
- 据报道,Synapse 前首席执行官正试图为其新的仿人机器人企业融资 1 亿美元
Sankaet Pathak的上一家初创公司Synapse在2024年因合作方Evolve Bank & Trust的问题申请破产,数千万美元的存款去向不明。然而,Pathak现在正努力为其新的人形机器人初创公司Foundation筹集资金,目标是筹集1亿美元,估值达10亿美元。这家公司仅在今年推出了其机器人Phantom,此前8月才通过pre-seed轮获得1100万美元。这项新项目旨在通过创建复杂环境下运行的高级人形机器人来解决劳动力短缺问题。
- 社交媒体初创公司 Fizz 起诉 Instacart 和 Partiful 侵犯新 Fizz 应用程序的商标权
社交媒体初创公司Fizz起诉Instacart和活动策划应用Partiful涉嫌商标侵权。Instacart刚推出名为Fizz的饮料和零食配送应用,并与Partiful集成。Fizz要求法院限制两家公司在社交或活动策划服务中使用“FIZZ”名称,并索赔损害赔偿。Fizz称自2022年1月起使用该商标,指责Instacart和Partiful故意使用相同名称,导致消费者混淆,并希望利用其在Z世代中的品牌知名度。Fizz此前还曾因不正当竞争起诉Sidechat。
- Meta 聘用前谷歌 DeepMind 总监领导其人工智能研究实验室
Meta任命Robert Fergus领导其基础AI研究实验室FAIR。他曾任谷歌DeepMind研究总监,并有在Meta工作的经历。FAIR面临挑战,许多研究人员离开,转投其他公司或Meta的新人工智能团队。之前的AI研究副总裁Joelle Pineau四月离职。
- 谷歌推出 “隐式缓存”,让访问最新人工智能模型更便宜
Google在Gemini API中引入了一项名为“隐式缓存”的新功能,声称能为第三方开发者降低AI模型的使用成本,节省约75%的重复上下文处理费用。该功能自动启用,适用于Gemini 2.5 Pro和2.5 Flash模型,旨在减少手动工作的需要,并通过缓存提高效率。此前的明确缓存需要开发者手动定义高频请求,导致一些用户不满。新功能自动识别相同前缀请求,动态回馈成本节省。然而,Google并未提供第三方验证其效果。
- Instagram Threads 将推出视频广告
Meta宣布Instagram Threads将测试视频广告,以增强其广告功能。仅少数广告商将在Threads中测试19:9或1:1的视频广告,这些广告会出现在用户生成内容之间。此外,Meta透露Threads的月活跃用户已超过3.5亿,并且用户使用时间增加了35%。与此同时,Meta还在测试Reels趋势广告和其他广告产品,以增强广告主与趋势内容的连接。Meta还将在Creator Marketplace中引入趋势测试,帮助广告主更有效地与受欢迎的创作者合作。
- PowerSchool 支付了黑客的赎金,但现在学校说他们被勒索了
教育软件公司PowerSchool在2024年12月遭黑客攻击后付款赎回学生数据,但至少一所学校现被勒索,表示数据未被删除。该公司软件服务于数百万学生,存储有重要的个人信息。多地学校收到勒索信,专家和执法部门对支付赎金持反对态度。最新情况涉及多地学校,估计影响数百万人。PowerSchool认为这不是新事件,因为数据与前次被盗数据相符。目前暂不清楚受影响人数。
- 谷歌推出人工智能工具,保护 Chrome 浏览器用户免受欺诈
Google推出新的AI驱动防护措施以打击Chrome浏览器的网络骗局。其Gemini Nano模型将在桌面端提供增强保护,帮助识别并防范新型骗局。同时,Google在Android版本中引入AI警告,提醒用户注意垃圾通知。此举旨在即刻识别危险网站,从而保护用户免受未曾出现的骗局伤害。此外,Google计划扩展AI防护到更多设备和更多骗局类型,并在搜索中使用AI检测以阻止数百万的诈骗结果,已减少80%以上的假冒航空客服诈骗风险。
- 在与美国的贸易战中,中国吉利拟将电动汽车初创企业 Zeekr 私有化
吉利计划将其豪华电动车品牌极氪从纽约证券交易所退市,此举与特朗普政府可能将中国公司逐出美国股市的计划有关。吉利提议以每份美国存托凭证(ADS)25.66美元的价格收购余下股份,较前一日收盘价高约14%。吉利已拥有极氪65.7%的股份,收购其余股份需约22亿美元,有助于极氪抵御市场挑战并保护投资。此外,极氪与Waymo合作开发自动驾驶出租车,退市可能影响合作。
- 在 TechCrunch 会议上展示您的初创企业:人工智能,趁现在还来得及!
TechCrunch Sessions: AI即将在6月5日于UC Berkeley’s Zellerbach Hall召开,这是一个聚集AI行业顶级人才和投资者的活动。参展可以让你的品牌在AI社区内获得更多关注,并与潜在合作伙伴接触。展示创新尤为重要,因为市场噪音大,需提高可见度。参展报名截止日期为5月9日晚上11:59(太平洋时间)。抓住最后的24小时机会,预定展位。
- 星链》在印度的推出只是时间问题,而不是是否推出的问题
Starlink获得印度政府批准,可以在印度市场展开运营。SpaceX需提交合规文件并获得印度空间监管机构IN-SPACe的许可。预计Starlink在印度的正式推出需六到九个月。此前,SpaceX未经许可在印提供服务被责令退款,现在印度已指定卫星通信新规。尽管面临当地和国际竞争者,Starlink仍看好印度这一互联网用户增长潜力市场。印政府将分配卫星互联网频谱,但具体费用和要求尚未公布。
- 红杉牵头 15 亿美元收购销售自动化初创公司 Clay
Clay的联合创始人兼CEO Kareem Amin在2022年看到公司产品成功起飞。自此,公司估值超过10亿美元,员工从几十人扩展到150多人。Clay允许至少工作一年以上的员工出售部分股份给现有投资者红杉资本,公司估值升至15亿美元。Clay的技术帮助销售和市场人员实现自动化策略,吸引了OpenAI等客户,并在社区轮中筹集100万美元,支持用户参与公司成长。Amin希望此举能激励其他初创企业为员工提供流动性。
- OpenAI 在亚洲启动数据驻留计划
OpenAI在亚洲推出新的数据驻留计划,继2月在欧洲推出后,为ChatGPT Enterprise、ChatGPT Edu和OpenAI API等产品提供支持。这一计划旨在帮助亚洲组织满足当地数据主权要求,数据可存储在日本、印度、新加坡和韩国等国家。OpenAI强调数据的机密性和安全性,并表示数据完全由用户拥有。此举标志着OpenAI加快海外扩展,同时推出“OpenAI for Countries”以改进国际基础设施服务。
- 比尔-盖茨要求其基金会在 2045 年前花光所有资金
比尔·盖茨宣布其基金会将在未来20年内花光所有资金并结束运营。他承诺捐出99%的财富(估价1070亿美元),预计基金会将花费超过2000亿美元。这标志着基金会路线的重大转变,此前规定为盖茨去世后20年关闭。基金会致力于健康、教育、全球发展等领域,已支出超过1000亿美元,主要受益人为低收入国家的人们。此举恰逢美国削减对外援助之际。
- 火柴公司将裁员 13
Match Group将裁员13%,大约影响325名员工,旨在降低成本、优化利润率并精简组织结构。此次重组将减少管理层级,集中关键职能,包括技术和数据服务等。该公司预计可节省超过1亿美元,并在2025年节省约4500万美元。第一季度收入同比下降3%至8.312亿美元,净利润下降4.6%至1.176亿美元。
- 亚马逊最新的人工智能工具旨在改进产品列表
亚马逊推出了一款名为“Enhance My Listing”的生成式AI工具,帮助商家改善产品列表。这款工具能够根据季节趋势自动建议产品标题、属性和描述,商家可以选择接受、拒绝或修改建议。此次发布首先针对美国部分商家,未来几周将进一步扩展。自2023年以来,亚马逊已陆续推出多种生成式AI工具,目前已有超过90万商家使用这些工具,90%的生成内容被商家接受。其他公司如谷歌、eBay、Meta及Shopify也在推出类似的AI工具。
- Reddit 为企业客户推出新的个人资料工具
Reddit推出针对企业用户的Reddit Pro新功能,帮助品牌融入社区。企业在注册时可获取自动生成的个人简介,并展示社区帖子、评论及行业趋势。Reddit的新品功能旨在提升企业在平台的影响力和信誉,同时促进企业增长。最新财季Reddit表现强劲,营收达3.924亿美元,同比增61%,日活跃用户1.081亿,同比增31%。
- 研究发现:向聊天机器人询问简短答案会增加幻觉
一项由巴黎AI测试公司Giskard进行的研究表明,要求AI聊天机器人简洁回答可能导致其更频繁出现“幻觉”,即生成不准确的信息。研究发现,在处理模糊或错误前提的问题时,短答提示会显著影响AI模型的准确性。即使是OpenAI的最新模型,简短要求也会导致准确性的下降。研究指出,简洁指令可能会妨碍模型识别和纠正错误信息,而用户偏好的模型不一定最真实。这反映了提升用户体验与保持信息准确之间的矛盾。
- 风险投资公司 Insight Partners 证实个人数据在一月份的黑客攻击中被盗
风投公司Insight Partners在一月份遭受网络攻击后将通知某些人其个人信息被窃取。被盗信息包括现任和前任员工及有限合伙人的个人资料、某些基金、管理公司和投资组合公司的银行和税务信息。这是该公司首次承认数据在攻击中被窃取。Insight此前将黑客攻击归因于复杂的社会工程攻击,但未提供证据。该公司管理超过900亿美元资产。近年来,多家风投公司遭遇类似攻击。
- Hims & Hers 为何转向自动驾驶汽车行业寻找精通人工智能的首席技术官?
Hims & Hers聘请自动驾驶行业资深人士Mo Elshenawy担任首席技术官,以加速其AI产品议程。Elshenawy曾是自动驾驶公司Cruise的总裁兼CTO,他认为AI在医疗和自动驾驶领域有类似挑战。Hims & Hers是一家总部位于旧金山的远程医疗公司,通过与特殊目的收购公司合并于2021年上市。公司致力于通过AI模型提升诊断和治疗效率,同时强调人类医生仍在决策过程中发挥重要作用。
- 苹果公司试图推迟禁止其从外部应用支付中抽成的裁决
苹果试图延迟一项法院裁决,该裁决要求苹果允许iOS开发者在美国引导用户使用外部支付系统,以避免支付给苹果的佣金。苹果已提出紧急动议,要求暂停相关规定的执行。此前,一项新的法院裁决支持Epic Games,迫使苹果允许应用在美国App Store内包含外部购买链接,停止收取相关佣金及弹出警告信息。苹果认为,这一裁决对其业务造成重大损失且不合理。Epic批评苹果此举意在阻止竞争并从消费者和开发者中获得高费用。
- 博世风险投资 2.7 亿美元新基金将目光转向北美地区
博世创投推出新的2.7亿美元基金,旨在投资北美的深科技初创公司。尽管面临中美贸易战、股市波动和经济衰退的担忧,博世创投认为北美的项目流仍然强劲。该基金计划进行20到25项投资,重点关注汽车、气候技术、网络安全、半导体制造、能源效率和企业软件等领域。生成式AI在制造业的应用也备受关注。博世自2017年起就高度重视AI,现在所有产品均利用AI开发或生产。