本文将会介绍如何使用mem0工具来为你的大模型加入记忆层。
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
与那些使用参数化方式(Parametric Memory)或者增加模型上下文长度(长上下文)来实现大模型的记忆相比,使用Memo等工具来实现大模型的记忆的方式主要是依靠工程化能力,其背后的技术栈主要如下:
- 使用LLM从多轮对话中提取记忆
- 记忆层的更新机制(记忆的增删改查)
- 记忆的召回机制(使用向量检索及图数据库Graph Memory)
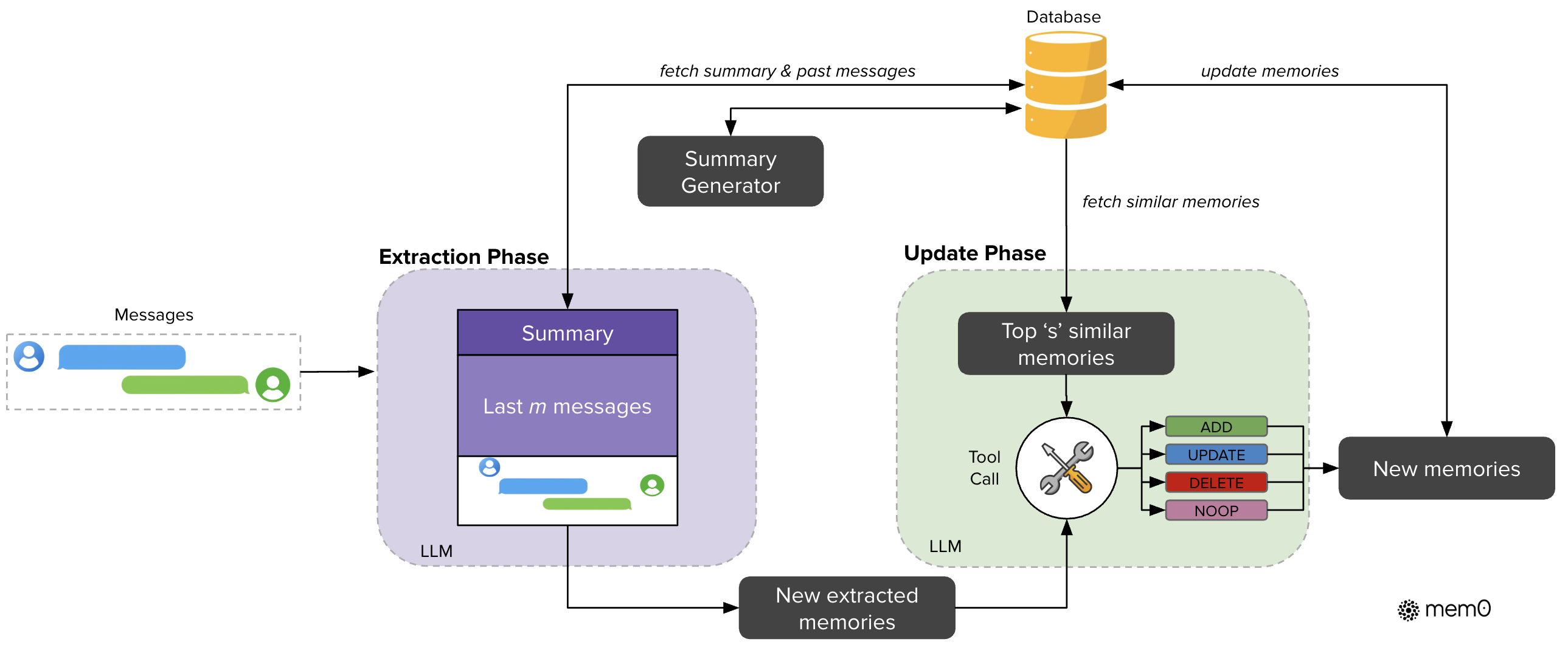
Mem0主要采用工程化方式来实现多轮对话的长期记忆,从对话中提取所需的记忆,并在记忆层中实现记忆的更新,然后在新的对话中根据query召回相关记忆并使用LLM回复,使得回复更符合用户的个性和以往习惯,提升问答的体验,更懂用户。
Mem0的Github网址为https://github.com/mem0ai/mem0,是目前工程化实现LLM长期记忆的代表性工作之一,目前start数量36.6K,深受开发者青睐。
本文将会简单介绍Mem0的使用方式,其背后的实现原理可以放在下一篇文章中进行详细探讨。
记忆层更新
Mem0的使用方式主要为使用托管平台和自定义托管。笔者在托管平台使用Google账号注册,并在本地安装所需第三方模块:
1
| $ pip install mem0ai openai python-dotenv
|
Mem0使用OpenAI的gpt-4o-mini为默认大模型从对话中抽取记忆。
新增记忆
下面是从对话中抽取记忆,并新增记忆,演示代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import os
from dotenv import load_dotenv
from mem0 import MemoryClient
load_dotenv()
client = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))
messages = [
{ "role": "user", "content": "我身体比较肥胖,但是小王就比较瘦,多动就容易出汗,有什么好的运动方式吗?" },
{ "role": "assistant", "content": "我建议你尝试一下羽毛球,羽毛球是一项很好的有氧运动,可以锻炼你的心肺功能,同时也可以锻炼你的协调性和反应能力。" },
{ "role": "user", "content": "我和小王今天打了三个小时的羽毛球。" },
{ "role": "assistant", "content": "很棒啊,继续加油!" },
{ "role": "user", "content": "最近是夏天,听说云南的天气很凉爽,我想去云南旅游。" },
{ "role": "assistant", "content": "云南的天气确实很凉爽,但是最近是旅游旺季,人很多,你可以考虑错峰出行。" },
{ "role": "user", "content": "我最近在学Python,我想用Python写一个爬虫,爬取豆瓣电影的Top250。" },
{ "role": "assistant", "content": "Python写爬虫是一个很好的选择,但是你需要先学习爬虫的基础知识,比如HTTP请求、HTML解析、数据存储等。" },
]
client.add(messages, user_id="Jackie")
|
在托管平台查看Jackie用户下,新增了8条Memory,如下图:
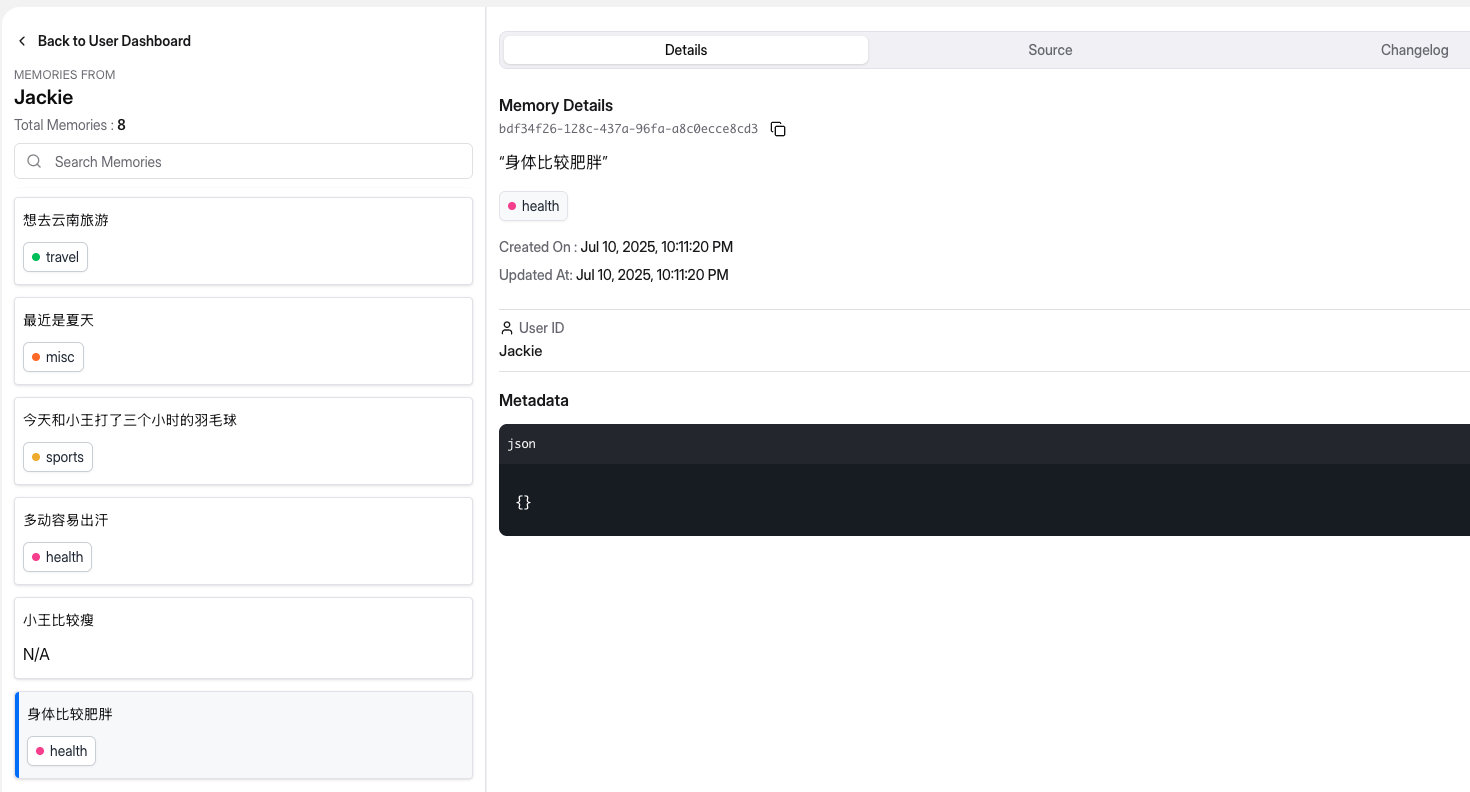
从上图中,我们可以看到,Mem0提取的记忆不仅包含必要的元数据(比如id、用户、创建时间、更新时间),还给出了记忆的分类,比如身体比较肥胖属于health类别。
搜索记忆
Mem0支持对记忆进行检索,主要使用文本相似度方案实现。
下面是对记忆进行搜索的示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
| import os
from dotenv import load_dotenv
from mem0 import MemoryClient
load_dotenv()
client = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))
query = "最近想去哪里旅行?"
result = client.search(query, user_id="Jackie")
for item in result:
print(f"Memory id: {item['id']}, memory: {item['memory']}, category: {item['categories']}, score: {round(item['score'], 4)}")
|
输出结果如下:
1
2
3
4
5
6
7
8
| Memory id: cc6ef246-8010-4e67-9b99-55f717931a01, memory: 多动容易出汗, category: ['health'], score: 0.4635
Memory id: bdf34f26-128c-437a-96fa-a8c0ecce8cd3, memory: 身体比较肥胖, category: ['health'], score: 0.4478
Memory id: b87f7b82-fbbd-46cf-8600-655bba186de5, memory: 小王比较瘦, category: [], score: 0.4355
Memory id: f8a6c566-7828-4732-b4e0-93a449ceb6eb, memory: 今天和小王打了三个小时的羽毛球, category: ['sports'], score: 0.4027
Memory id: 4c1f0b4e-fe12-45a9-a478-6547a3b3372f, memory: 想去云南旅游, category: ['travel'], score: 0.4008
Memory id: 7e76025e-5593-4de5-a8cd-663b9945a9c1, memory: 最近在学Python, category: ['technology'], score: 0.3962
Memory id: ff9c32d5-498b-4d8b-ab72-4cbe52866099, memory: 最近是夏天, category: ['misc'], score: 0.3882
Memory id: 68ebf5cc-269a-405f-8256-df5fcb5ba233, memory: 想用Python写一个爬虫爬取豆瓣电影的Top250, category: ['technology'], score: 0.3614
|
Mem0默认使用OpenAI的向量模型,从上面的输出结果看,该模型的召回效果一般,并没有达到理想效果。
更新记忆
Mem0支持对记忆进行更新,示例代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import os
from dotenv import load_dotenv
from mem0 import MemoryClient
load_dotenv()
client = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))
memory_id="f8a6c566-7828-4732-b4e0-93a449ceb6eb"
client.update(
memory_id=memory_id,
text="今天和小王打羽毛球,时间不是3小时,而是两小时。"
)
|
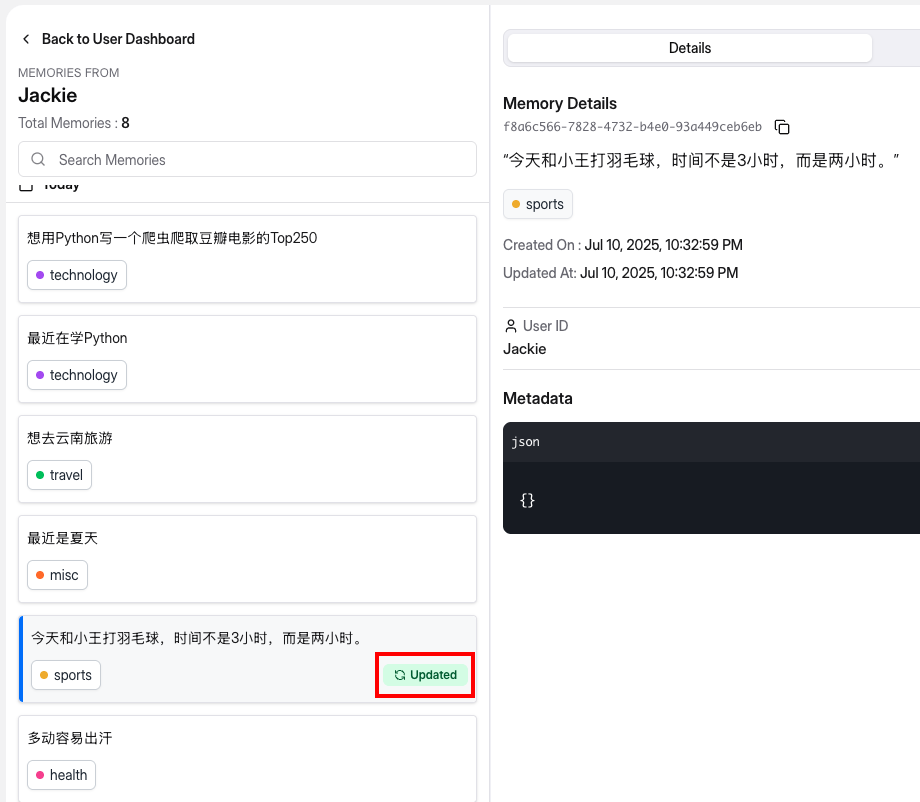
从上图中可以看出,这条记忆已经更新了。
删除记忆
Mem0支持对记忆进行更新,示例代码如下:
1
2
3
4
5
6
7
8
9
10
11
| import os
from dotenv import load_dotenv
from mem0 import MemoryClient
load_dotenv()
client = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))
memory_id="f8a6c566-7828-4732-b4e0-93a449ceb6eb"
client.delete(memory_id=memory_id)
|
运行后,这条记忆已被成功删除。
加入记忆后的模型回复
让我们来尝试下,模型加入记忆前后的回复结果的对比。示例代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| import os
from dotenv import load_dotenv
from mem0 import MemoryClient
from openai import OpenAI
load_dotenv()
mem0_client = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))
openai_client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def get_memory(query: str, limit: int = 3) -> str:
result = mem0_client.search(query, user_id="Jackie")
memories = []
for item in result[:limit]:
memories.append(item["memory"])
return "\n".join(memories)
def get_answer(messages: list[dict]) -> str:
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
temperature=0.5,
max_tokens=1000
)
return response.choices[0].message.content
if __name__ == "__main__":
query = "我想去云南旅游,需要注意什么?"
messages = [
{"role": "user", "content": query}
]
answer = get_answer(messages)
print("未加入记忆的回答:\n", answer)
print("-" * 100)
memory = get_memory(query)
prompt = f"""
用户的问题是:{query}
用户的姓名是:Jackie
用户的历史记忆是:{memory}
请根据用户的问题和历史记忆,给出回答。
"""
messages = [
{"role": "user", "content": prompt},
]
answer = get_answer(messages)
print("加入记忆的回答:\n", answer)
print("-" * 100)
|
输出结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| 未加入记忆的回答:
去云南旅游时,有几个方面需要注意:
1. **气候与穿着**:云南地处高原,气候变化较大,早晚温差较大。建议准备适合的服装,尤其是保暖衣物和防晒用品。
2. **高原反应**:云南部分地区海拔较高,尤其是丽江、大理等地,初到时可能会有高原反应。建议适当休息,避免剧烈运动,多喝水,必要时可携带一些抗高原反应的药物。
3. **饮食注意**:云南的饮食以辣味为主,且有些地方的水质与饮食习惯可能与您平时不同。尽量选择当地人推荐的餐馆,避免生食和不洁食物。
4. **交通安全**:云南的部分山区道路较为复杂,出行时注意安全。如果自驾游,确保车辆状况良好,并了解当地交通规则。
5. **文化习俗**:云南是一个多民族聚居的地方,各民族有其独特的文化和习俗。在与当地人交流时,尊重他们的文化,避免不当行为。
6. **自然保护**:云南有许多独特的自然景观和生态环境,游玩时请注意环保,不打扰野生动物,遵循景区的相关规定。
7. **提前规划**:云南的旅游资源丰富,建议提前规划行程,选择自己感兴趣的景点,并预定好住宿。
8. **注意安全**:在游玩过程中,特别是在进行户外活动时,注意自身安全,遵循导游的指引。
希望你在云南的旅行愉快!
----------------------------------------------------------------------------------------------------
加入记忆的回答:
你好,Jackie!去云南旅游是个不错的选择,那里有美丽的自然风光和丰富的文化。以下是一些你在云南旅游时需要注意的事项:
1. **气候变化**:云南的气候多变,早晚温差大。建议你准备适合的衣物,尤其是外套,以应对早晚的寒冷。
2. **防晒措施**:云南的紫外线较强,尤其是在高海拔地区。记得带上防晒霜、太阳帽和太阳镜,以保护皮肤。
3. **水源安全**:在云南的一些地区,饮用水可能不太安全,建议购买瓶装水,避免生水。
4. **高原反应**:如果你计划去大理、丽江等高海拔地区,注意可能出现的高原反应。适当休息,避免剧烈运动,逐渐适应海拔。
5. **饮食习惯**:云南的饮食以辣为主,如果你不太能吃辣,可以提前告知餐厅,选择适合自己的菜品。
6. **保持水分**:由于你提到容易出汗,保持充足的水分摄入非常重要,随身携带水瓶,及时补水。
7. **注意安全**:在旅游时,注意个人财物安全,尤其是在繁忙的旅游景点。
希望这些建议能帮助你更好地享受云南之旅!如果还有其他问题,随时问我哦。
|
大模型在加入用户记忆前,回复结果比较笼统,没有个性;但在加入用户记忆后,会结合用户的记忆,比如用户之前提到比较容易出汗,因此回复结果更个性化,针对性更强,有效提升了用户的体验。
自定义向量数据库
Mem0支持自定义向量数据库,笔者以本地启动的Milvus为例,演示如何使用自定义向量数据库:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| import os
from dotenv import load_dotenv
from mem0 import Memory
from openai import OpenAI
load_dotenv()
openai_client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
config = {
"vector_store": {
"provider": "milvus",
"config": {
"collection_name": "mem0_test",
"embedding_model_dims": "1536",
"url": "http://localhost:19530",
"metric_type": "L2"
}
}
}
m = Memory.from_config(config)
messages = [
{ "role": "user", "content": "我身体比较肥胖,但是小王就比较瘦,多动就容易出汗,有什么好的运动方式吗?" },
{ "role": "assistant", "content": "我建议你尝试一下羽毛球,羽毛球是一项很好的有氧运动,可以锻炼你的心肺功能,同时也可以锻炼你的协调性和反应能力。" },
{ "role": "user", "content": "我和小王今天打了三个小时的羽毛球。" },
{ "role": "assistant", "content": "很棒啊,继续加油!" },
{ "role": "user", "content": "最近是夏天,听说云南的天气很凉爽,我想去云南旅游。" },
{ "role": "assistant", "content": "云南的天气确实很凉爽,但是最近是旅游旺季,人很多,你可以考虑错峰出行。" },
{ "role": "user", "content": "我最近在学Python,我想用Python写一个爬虫,爬取豆瓣电影的Top250。" },
{ "role": "assistant", "content": "Python写爬虫是一个很好的选择,但是你需要先学习爬虫的基础知识,比如HTTP请求、HTML解析、数据存储等。" },
]
m.add(messages, user_id="Jackie")
|
注意:事先不需要在Milvus中创建mem0_test这个集合(Collection),Mem0会自动创建。
运行上述脚本,发现在Milvus中已自动创建两个Collection(多出来的Collection名称为mem0migrations),mem0_test的Schema如下图:
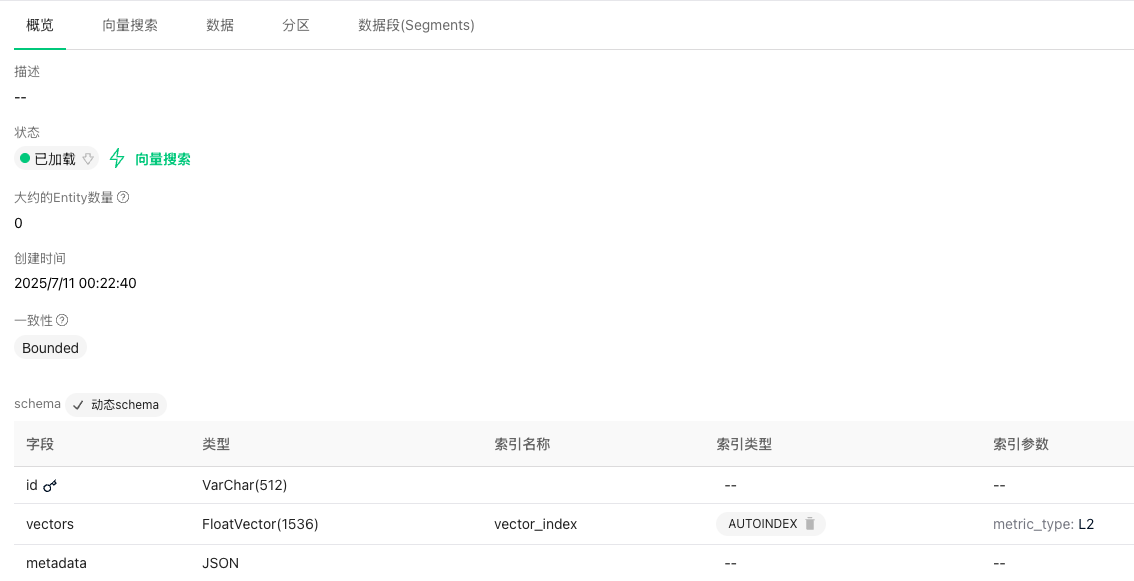
mem0_test的数据如下图:
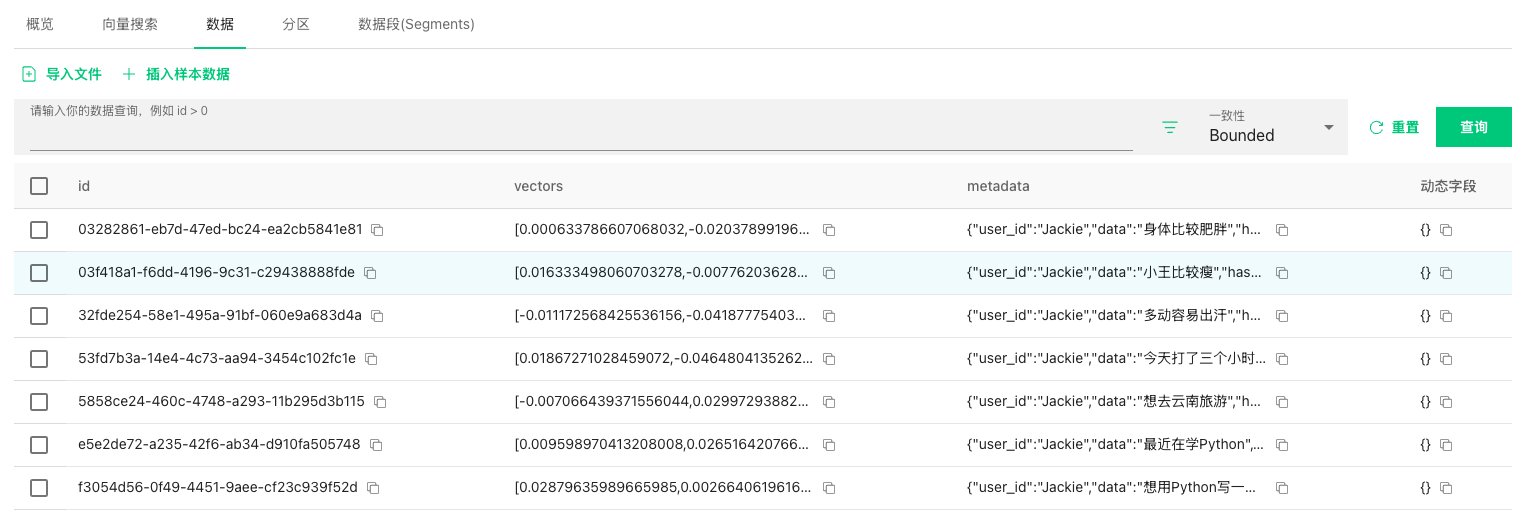
其中metadata字段中的数据结构如下:
1
| {"user_id":"Jackie","data":"身体比较肥胖","hash":"05eddefbd69e75b4360b1e1490163cc2","created_at":"2025-07-10T09:22:57.110932-07:00"}
|
对上述记忆进行搜索,演示代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import os
from dotenv import load_dotenv
from mem0 import Memory
from openai import OpenAI
load_dotenv()
openai_client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
config = {
"vector_store": {
"provider": "milvus",
"config": {
"collection_name": "mem0_test",
"embedding_model_dims": "1536",
"url": "http://localhost:19530",
"metric_type": "IP"
}
}
}
m = Memory.from_config(config)
query = "最近想去哪里旅行?"
result = m.search(query, user_id="Jackie")
for item in result['results']:
print(f"Memory id: {item['id']}, memory: {item['memory']}, score: {round(item['score'], 4)}")
|
输出结果如下:
1
2
3
4
5
6
7
| Memory id: 53fd7b3a-14e4-4c73-aa94-3454c102fc1e, memory: 想去云南旅游, score: 1.102
Memory id: 32fde254-58e1-495a-91bf-060e9a683d4a, memory: 最近在学Python, score: 1.1775
Memory id: 5858ce24-460c-4748-a293-11b295d3b115, memory: 今天打了三个小时的羽毛球, score: 1.6116
Memory id: 03282861-eb7d-47ed-bc24-ea2cb5841e81, memory: 想用Python写一个爬虫,爬取豆瓣电影的Top250, score: 1.701
Memory id: 03f418a1-f6dd-4196-9c31-c29438888fde, memory: 小王比较瘦, score: 1.7036
Memory id: f3054d56-0f49-4451-9aee-cf23c939f52d, memory: 身体比较肥胖, score: 1.7836
Memory id: e5e2de72-a235-42f6-ab34-d910fa505748, memory: 多动容易出汗, score: 1.8162
|
由于我们在使用Milvus时对embedding字段指定的metric_type为L2(Mem0暂时只支持L2和IP这两个metric type,不支持COSINE),因此输出的相似度分数(score)不在0到1之间。
自定义大模型
Memo还支持自定义大模型和Embedding模型,我们以Gemini系列模型为例进行演示,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| import os
from dotenv import load_dotenv
from mem0 import Memory
load_dotenv()
os.environ["GEMINI_API_KEY"] = os.getenv("GEMINI_API_KEY")
config = {
"embedder": {
"provider": "gemini",
"config": {
"model": "models/text-embedding-004",
}
},
"llm": {
"provider": "gemini",
"config": {
"model": "gemini-2.5-flash",
"temperature": 0.0,
"max_tokens": 2000,
}
},
"vector_store": {
"provider": "milvus",
"config": {
"collection_name": "mem0_gemini",
"embedding_model_dims": "768",
"url": "http://localhost:19530",
"metric_type": "L2"
}
}
}
memory = Memory.from_config(config)
messages = [
{ "role": "user", "content": "我身体比较肥胖,但是小王就比较瘦,多动就容易出汗,有什么好的运动方式吗?" },
{ "role": "assistant", "content": "我建议你尝试一下羽毛球,羽毛球是一项很好的有氧运动,可以锻炼你的心肺功能,同时也可以锻炼你的协调性和反应能力。" },
{ "role": "user", "content": "我和小王今天打了三个小时的羽毛球。" },
{ "role": "assistant", "content": "很棒啊,继续加油!" },
{ "role": "user", "content": "最近是夏天,听说云南的天气很凉爽,我想去云南旅游。" },
{ "role": "assistant", "content": "云南的天气确实很凉爽,但是最近是旅游旺季,人很多,你可以考虑错峰出行。" },
{ "role": "user", "content": "我最近在学Python,我想用Python写一个爬虫,爬取豆瓣电影的Top250。" },
{ "role": "assistant", "content": "Python写爬虫是一个很好的选择,但是你需要先学习爬虫的基础知识,比如HTTP请求、HTML解析、数据存储等。" },
]
memory.add(messages, user_id="Tom")
|
总结
本文简单介绍了Memo工具是如何在大模型中加入记忆,并实现记忆的增删改查,同时还介绍了Memo中如何支持自定义的向量数据库和大模型、Embedding模型。
后续笔者将会更加深入调研Memo工具,欢迎大家阅读~
参考文献
- Integrating Long-Term Memory with Gemini 2.5: https://www.philschmid.de/gemini-with-memory
- Mem0 Documentation: https://docs.mem0.ai/what-is-mem0