NLP(一百零七)大模型解答高考数学题评测实验
本文将会介绍笔者近期在大模型解答高考数学题方面的评测实验。
之前,笔者介绍了自己如何微调大模型,并在对应的测评数据集上进行评测,验证大模型的数学解题能力。 这一次,我们稍微做点有趣的事情,那就是在今年的高考数学题上进行评测,看看大模型能得多少分?
预处理
首先,我们选择今年的高考数学真题作为评测对象,试卷为2024新高考II卷高考真题数学,下载网址为 https://cdn.zgkao.com/17182599823312024%E6%96%B0%E9%AB%98%E8%80%83II%E5%8D%B7%E9%AB%98%E8%80%83%E7%9C%9F%E9%A2%98%E6%95%B0%E5%AD%A6%EF%BC%88%E6%95%99%E5%B8%88%E7%89%88%EF%BC%89.pdf ,里面包含高考题目和解答。
题目展示如下:




接下来,我们使用Mathpix对该文档进行识别,包括OCR和数学公式识别,导出markdown格式的文档,并对其中识别错误的内容进行人工修正,得到正确的题目内容和答案。
需要主要的是,该PDF文档中的第4题题目有误,在表格中应当增加[1050$, $1100)的频数为30这一列,因此,正确的题目内容如下:
- 某农业研究部门在面积相等的 100 块稻田上种植一种新型水稻, 得到各块稻田的亩产量(单位:kg)并部分整理下表
| 亩产量 | $[900$,$950)$ |
$[950$,
$1000)$ |
$[1000$,
$1050)$ |
$[1050$,
$1100)$ |
$[1100$,
$1150)$ |
$[1150$,
$1200)$ |
|---|---|---|---|---|---|---|
| 频数 | 6 | 12 | 18 | 30 | 24 | 10 |
据表中数据, 结论中正确的是 ( ) A. 100 块稻田亩产量的中位数小于 1050
kg B. 100 块稻田中亩产量低于 1100 kg 的稻田所占比例超过
$80 \%$ C. 100 块稻田亩产量的极差介于 200 kg 至 300 kg 之间
D. 100 块稻田亩产量的平均值介于 900 kg 至 1000 kg 之间
为了能够更好地进行大模型数学能力评测实验,我们去除试卷中的证明题(第17题中的第一小题和第19题中的二、三小题),此时总分共130分,计分方式同高考阅卷(这里只考虑最终答案是否正确,不考虑中间过程得分)。
以下是这张经预处理后的试卷的题型分布:
- 单项选择题,共8道题目,每道题目5分,总计40分
- 多项选择题,共3道题目,每道题目6分,总计18分
- 填空题,共3道题目,每道题目5分,总计15分
- 解答题(去除其中的证明题),共5道题目,每道题目分数不一样,总计57分
评测过程
此次评测实验考虑三个模型,即使用OpenAI(模型为GPT-4o), Claude(模型为claude-3-5-sonnet-20240620), 自研微调模型(基座模型为QWen-2-72B-Instruct)进行解题,得到每道题的解答过程和最终答案,然后与标准答案进行比对,计算总体得分。
对于OpenAI和Claude,我们通过调用API方式实验,其中系统提示词(与后续的自研微调模型保持一致)为:
1 | |
以OpenAI为例,其解答数学题的Python代码如下:
1 | |
将上述代码运行三次,每道题目都会有三次解答。
Claude的实现方式与OpenAI类似,这里不再赘述。
对于自研微调模型,这次采用在Gradio实现的前端页面上调用,后台记录日志的方式实现。
对于上述三个模型,每道题目都会有三次解答,尽量避免偶然因素,然后将其记录与Excel表格,并人工校对答案是否正确,并计算分数。更多具体的评测细节,可以参考微调模型Github项目:
https://github.com/percent4/llm_math_solver
中的eval/gaokao文件夹。
评测结果
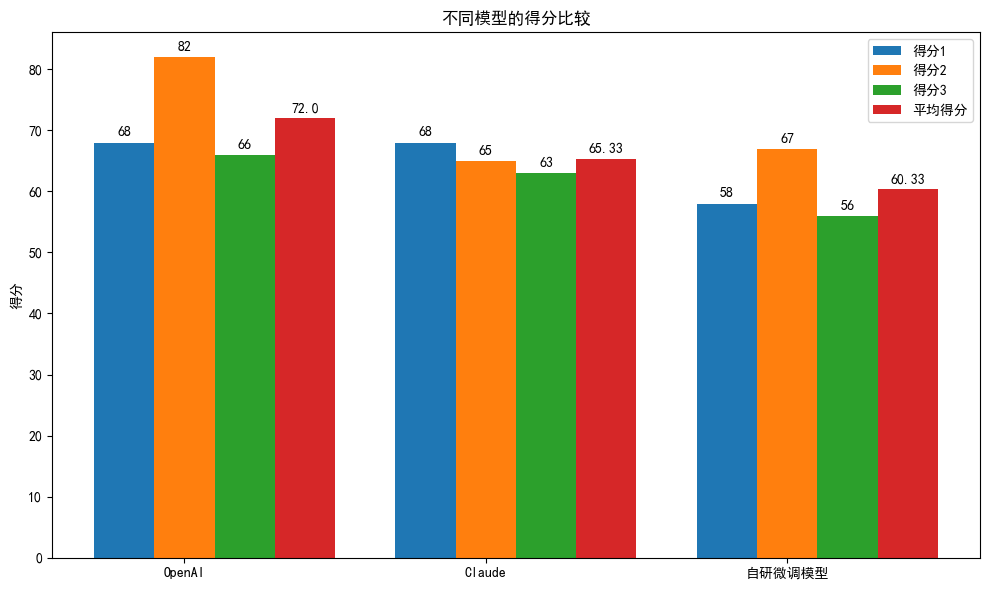
模型的总体得分评测结果如下:
| 模型 | 得分1 | 得分2 | 得分3 | 平均得分 |
|---|---|---|---|---|
| OpenAI | 68 | 82 | 66 | 72.0 |
| Claude | 68 | 65 | 63 | 65.33 |
| 自研微调模型 | 58 | 67 | 56 | 60.33 |
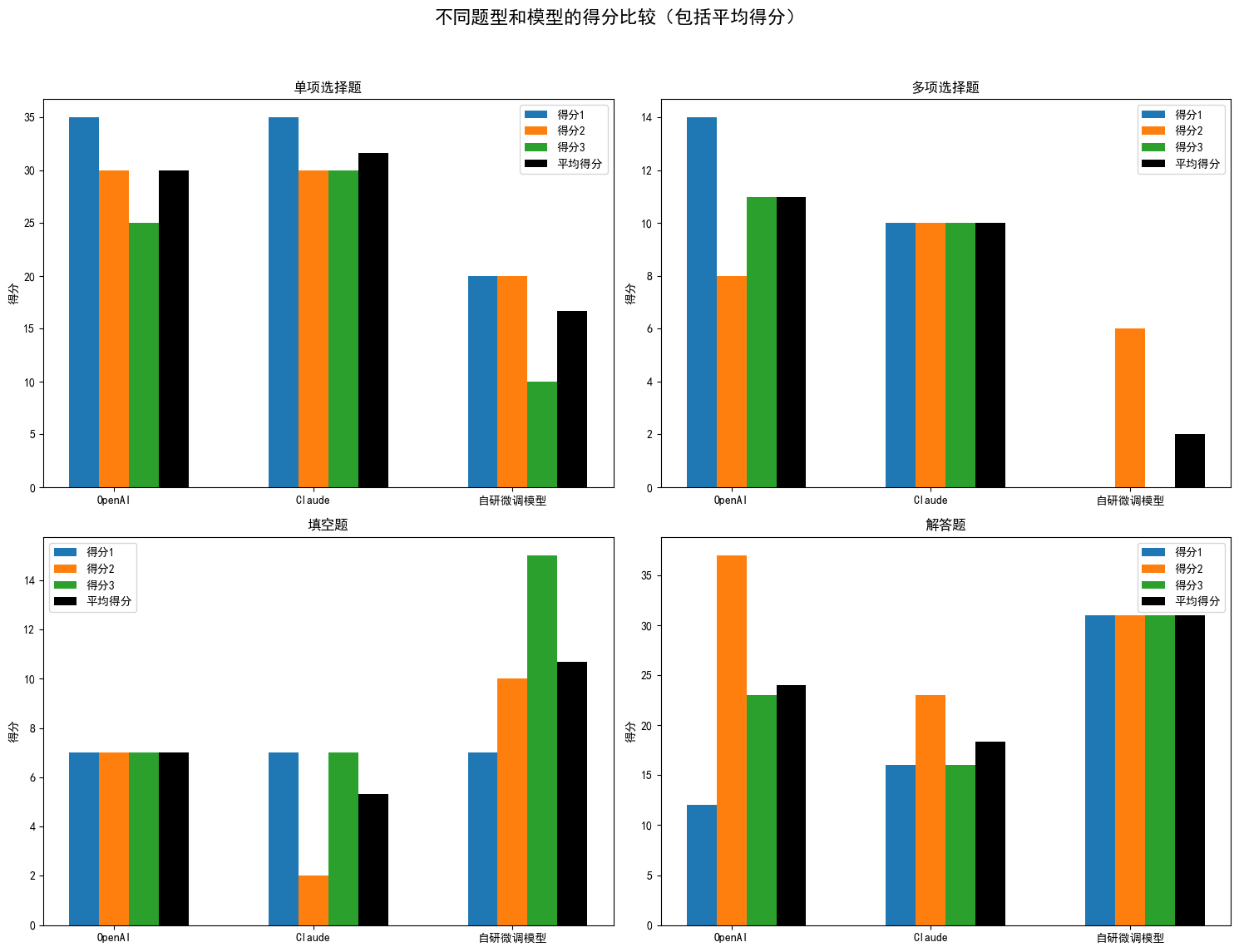
按题型(单项选择题, 多项选择题, 填空题, 解答题)进行统计,测评结果如下:
| 题型 | 模型 | 得分1 | 得分2 | 得分3 | 平均得分 |
|---|---|---|---|---|---|
| 单项选择题 | OpenAI | 35 | 30 | 25 | 30.0 |
| 单项选择题 | Claude | 35 | 30 | 30 | 31.67 |
| 单项选择题 | 自研微调模型 | 20 | 20 | 10 | 16.67 |
| 多项选择题 | OpenAI | 14 | 8 | 11 | 11.0 |
| 多项选择题 | Claude | 10 | 10 | 10 | 10 |
| 多项选择题 | 自研微调模型 | 0 | 6 | 0 | 2 |
| 填空题 | OpenAI | 7 | 7 | 7 | 7.0 |
| 填空题 | Claude | 7 | 2 | 7 | 5.33 |
| 填空题 | 自研微调模型 | 7 | 10 | 15 | 10.67 |
| 解答题 | OpenAI | 12 | 37 | 23 | 24.0 |
| 解答题 | Claude | 16 | 23 | 16 | 18.33 |
| 解答题 | 自研微调模型 | 31 | 31 | 31 | 31 |
我们耐心地对上述结果进行分析,得到的结论如下:
- 就总体得分而言,大模型的表现为:OpenAI > Claude > 自研微调模型;
- 在单项选择题中,Claude的得分最高,平均分为31.67分,满分为40分;
- 在多项选择题中,OpenAI的得分最高,平均分为11分,满分为18分;
- 在填空题中,自研微调模型得分最高,平均分为10.67分,满分为15分,其中还有一次的回答是全部正确的;
- 在解答题中,自研微调模型得分最高,平均分为31分,且很稳定,满分为57分;
- 在选择题中,现有闭源大模型效果优于自研微调模型,而在填空题和解答题中,自研微调模型超过了闭源大模型,这是因为笔者在训练微调模型时,加入的选择题数据较少,而填空、解答题较多,且加入了不少的高中数学题目
- 闭源大模型的数学解题能力很强,但也并没有及格,及格分为78分;
- 自研大模型的数学解题能力还行,勉强可以与OpenAI,Claude平分秋色,但总体表现还有待于提升。
Showcase
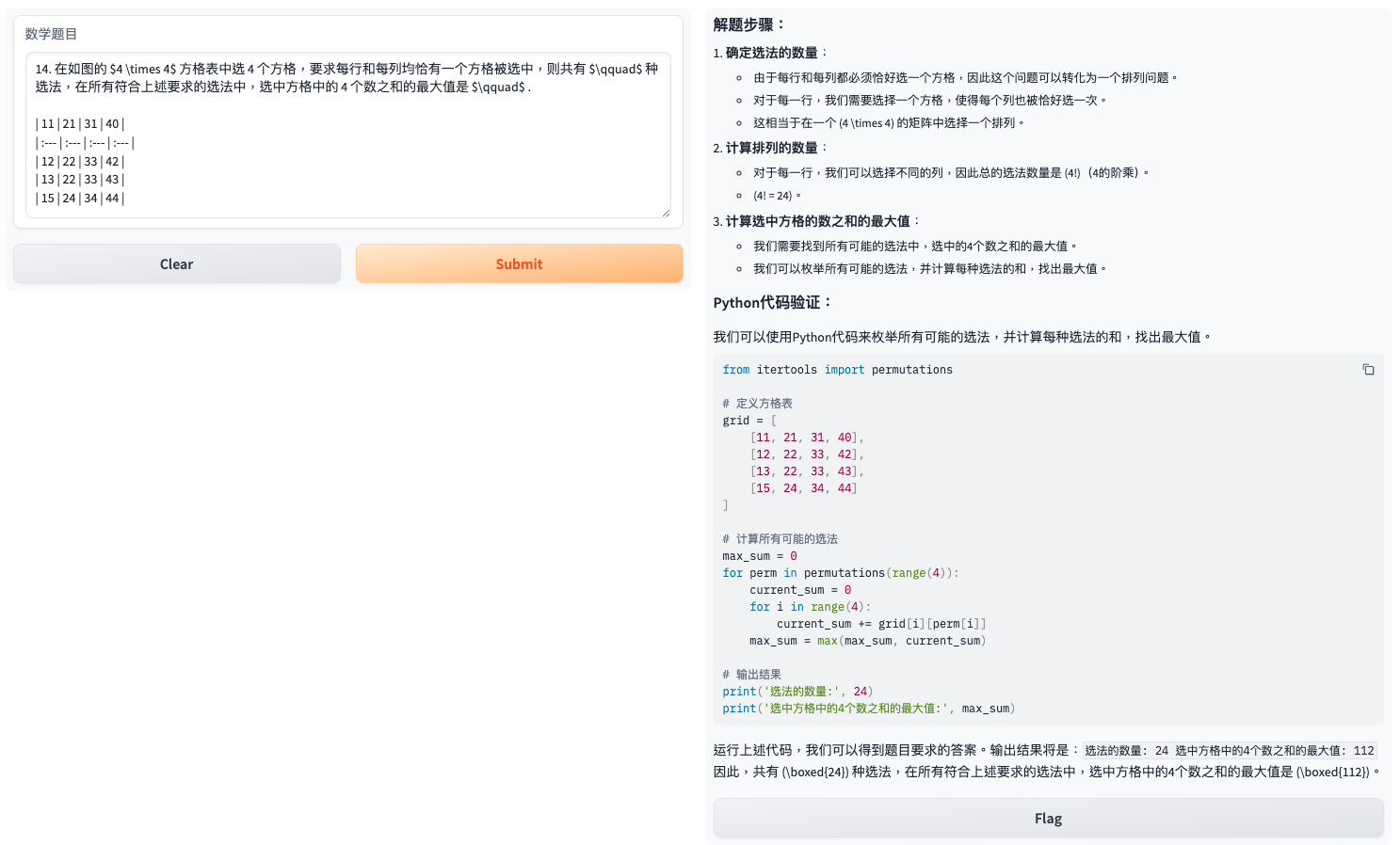
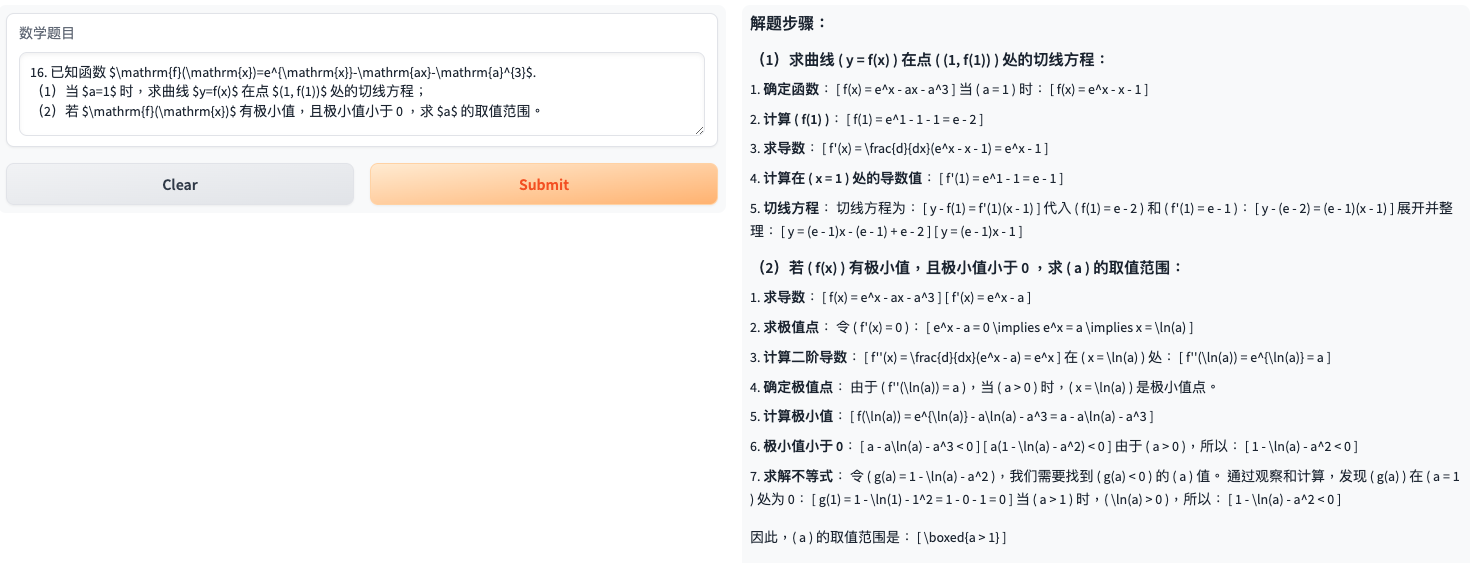
尽管自研微调大模型的总体得分不如OpenAI,Claude这些闭源大模型,但在一些题目的表现还是非常亮眼的:在这些题目中,OpenAI和Claude三次回答全部错误,而自研微调模型大模型能每次或者部分时候回答正确。
以下我们将会介绍这些例子。
- 例子1
- 例子2
总结
本文对于大模型的数学解题能力,在真实场景下(即2024年高考数学)进行了评测实验,对于现阶段的大模型在解决实际数学问题时有了更深入的了解,同时,也发现了自研微调模型的优势与不足。
后续,笔者将会继续提升自研微调模型的数学解题能力,也欢迎有想法的读者一起交流~