本文将会介绍如何使用vLLM框架来部署大模型以及大模型应用利器Open
WebUI的使用场景和其它功能,本文可作为Open WebUI方面的入门文章。
在介绍Open WebUI相关内容之前,我们先使用vLLM框架来部署本文中所使用的大模型。
关于vLLM框架的相关介绍和使用方法,可以参考笔者之前的文章:vLLM入门(一)初始vLLM
。
使用vLLM部署模型
本章节将介绍以下4个大模型的部署和获取方式:
Qwen2-72B-Instruct
llava-v1.6-34b-hf
llama3-70b-8192
mixtral-8x7b-32768
我们使用vLLM框架来部署通用模型Qwen2-72B-Instruct和多模态模型llava-v1.6-34b-hf。vLLM框架在最新的版本v0.5.0中已添加了对多模态模型的部署支持,不过暂时还只支持LLaVA系列模型。而llama3-70b-8192模型和mixtral-8x7b-32768模型可以在Groq官网中获取,不必再自行部署。
Qwen2-72B-Instruct的部署
我们在GPU机器上启动Docker Nvidia服务:
1 docker run --gpus 2 -itd --rm --privileged --name=llm --ipc=host -p 50080:8000 -v /data3/data-ai/usr/models:/workspace/models nvcr.io/nvidia/pytorch:23.08-py3
此处,我们使用0,1两张GPU卡,并对模型路径进行外挂,我们需要的模型路径就位于这个路径下。接着我们进入容器中,安装最新版vllm:
部署Qwen2-72B-Instruct模型,命令如下:
1 CUDA_VISIBLE_DEVICES=0,1 nohup python -m vllm.entrypoints.openai.api_server --model /workspace/models/Qwen2-72B-Instruct --served-model-name Qwen2-72B-Instruct --gpu-memory-utilization 0.95 --max-model-len 8192 --dtype auto --api-key token-abc123 --tensor-parallel-size 2 &
72B模型所占用显存较大,如无其它优化,则一般需用两张80G显存的显卡,笔者这里使用的显卡类型是A800-SXM4-80GB。该部署服务为OpenAI风格的API服务,其中Bearer
Token为token-abc123。
接着我们来验证模型是否部署成功:
输入:
1 curl http://localhost:8000/v1/models -H "Authorization: Bearer token-abc123" | jq
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 { "object" : "list" , "data" : [ { "id" : "Qwen2-72B-Instruct" , "object" : "model" , "created" : 1719047559 , "owned_by" : "vllm" , "root" : "Qwen2-72B-Instruct" , "parent" : null , "max_model_len" : 8192 , "permission" : [ { "id" : "modelperm-f97254d07f81448988cd6733aa69ddce" , "object" : "model_permission" , "created" : 1719047559 , "allow_create_engine" : false , "allow_sampling" : true , "allow_logprobs" : true , "allow_search_indices" : false , "allow_view" : true , "allow_fine_tuning" : false , "organization" : "*" , "group" : null , "is_blocking" : false } ] } ] }
输入:
1 2 3 4 5 6 7 8 9 10 11 12 curl --location 'http://localhost :8000 /v1/chat/completions' \--header 'Content-Type: application/json' \--header 'Authorization: Bearer token-abc123' \--data '{"model" : "Qwen2-72B-Instruct" ,"messages" : ["role" : "user" ,"content" : "中国的首都是哪里?"
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 { "id" : "cmpl-7aa0528dabf34fc8a6d4be431cc588d5" , "object" : "chat.completion" , "created" : 1719047641 , "model" : "Qwen2-72B-Instruct" , "choices" : [ { "index" : 0 , "message" : { "role" : "assistant" , "content" : "中国的首都是北京。" , "tool_calls" : [ ] } , "logprobs" : null , "finish_reason" : "stop" , "stop_reason" : null } ] , "usage" : { "prompt_tokens" : 24 , "total_tokens" : 30 , "completion_tokens" : 6 } }
llava-v1.6-34b-hf的部署
vLLM框架官网文档(https://docs.vllm.ai/en/stable/models/vlm.html)给出了多模态模型llava-1.5-7b-hf的部署方式和使用方式,但很少有资料给出了vLLM框架部署llava-v1.6-34b-hf模型的方法。
笔者参考vLLM中的脚本:https://github.com/vllm-project/vllm/blob/main/tests/multimodal/test_processor.py
,给出的部署命令为:
1 2 3 4 5 6 7 8 CUDA_VISIBLE_DEVICES=0,1 python -m vllm.entrypoints.openai.api_server \
这其中,
template_llava.jinja在vLLM源码中的examples文件夹中已经给出。验证模型成功的方法参考同上,输入命令为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 curl --location 'http://localhost:8000/v1/chat/completions' \'Content-Type: application/json' \'{ "model": "llava-v1.6-34b-hf", "messages": [ { "role": "user", "content": [ { "type": "text", "text": "How many persons are there in this image?" }, { "type": "image_url", "image_url": { "url": "https://k.sinaimg.cn/n/sinakd20240607s/108/w1024h684/20240607/7124-f44122427ecc58740167b6b24ee6fa6c.jpg/w700d1q75cms.jpg?by=cms_fixed_width" } } ] } ] }'
llama3-70b-8192 和
mixtral-8x7b-32768 的获取
llama3-70b-8192模型和mixtral-8x7b-32768模型可以在Groq官网中获取,官网体验网址为
https://groq.com/ ,需要先注册账号。
当然,我们也可以使用API来调用Groq上已部署好的模型,不过需要先申请API
KEY,申请网址为:https://console.groq.com/docs/quickstart 。
申请完API
KEY之后,我们就能以OpenAI风格的API来调用上述模型了,以llama3-70b-8192模型为例,示例的调用curl命令为:
1 2 3 4 5 6 7 8 9 10 11 12 curl --location 'https://api.groq.com/openai/v1/chat/completions' \'Content-Type: application/json' \'Authorization: Bearer gsk_xxx' \'{ "model": "llama3-70b-8192", "messages": [ { "role": "user", "content": "中国的首都是哪里?" } ] }'
将命令中的Bearer Token换成你自己的就行。
输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 { "id" : "chatcmpl-xxx" , "object" : "chat.completion" , "created" : 1719069639 , "model" : "llama3-70b-8192" , "choices" : [ { "index" : 0 , "message" : { "role" : "assistant" , "content" : " Easy one! 😊\n\n中国的首都是北京 (běi jīng)。\n\nBeijing is the capital of China, and it's located in the northern part of the country." } , "logprobs" : null , "finish_reason" : "stop" } ] , "usage" : { "prompt_tokens" : 16 , "prompt_time" : 0.005321601 , "completion_tokens" : 40 , "completion_time" : 0.106680264 , "total_tokens" : 56 , "total_time" : 0.11200186499999999 } , "system_fingerprint" : "fp_xxx" , "x_groq" : { "id" : "req_xxx" } }
至此 ,我们已经完成了上述4个模型的部署或获取,这样我们的准备工作就完成了。
Open WebUI介绍
Open WebUI(以前称为Ollama
WebUI)是一款面向大型语言模型(LLMs)的用户友好型Web界面,支持Ollama和兼容OpenAI的API运行。通过一个直观的界面,它为用户提供了一种便捷的方式,与语言模型进行交互、训练和管理。
主要特点
直观的界面:灵感来源于ChatGPT,保证了用户友好的体验。
响应式设计:无论是在桌面还是移动设备上,都能享受到无缝的体验。
快速响应:性能快速且响应迅速。
简明的设置过程:通过Docker或Kubernetes安装,旨在提供无忧的体验。
代码语法高亮:提高代码的可读性。
完整的Markdown和LaTeX支持:为了丰富交互体验,提供广泛的Markdown和LaTeX功能。
本地RAG集成:未来聊天交互的特色功能,通过#命令加载文档或添加文件。
网页浏览功能:使用#命令来丰富聊天体验。
快捷预设支持:使用/命令快速访问预设提示。
RLHF注释:通过评分消息帮助构建用于RLHF的数据集。
对话标签:方便地分类和查找特定聊天。
多模型支持:无缝切换不同聊天模型。
多模态支持:允许与支持图像等多模态的模型进行交互。
使用场景
Open WebUI适用于各种涉及大型语言模型交互的场景,可以是数据科学家、研究人员、开发者或任何对人工智能和自然语言处理感兴趣的个人或团队。以下是一些可能的应用场景:
数据分析和研究:研究者和学者可以通过与LLMs交互,探索数据集,进行自然语言理解和生成研究。
软件开发:开发人员可以利用其代码语法高亮和多模型支持功能进行编程问题的解决和代码生成。
教育:教师和学习者可以使用它作为一种教学和学习工具,以探索自然语言处理和人工智能的概念。
个人娱乐和探索:普通用户也可以使用它来探索AI对话的乐趣,获取信息或进行创造性写作。
安装使用
Open WebUI的安装使用非常方便,可以直接使用Docker部署,也可以使用第三方模块open-webui部署服务。
本文中,笔者使用第三方模块open-webui来部署Open WebUI服务。
首先,安装对应模块:
1 pip install open-webui==0.3.5
接着启动服务:
服务启动成功后,在浏览器中输入localhost:8080 即可看到用户登录界面,如下:
Open WebUI登录界面
完成用户登录后,即可使用Open WebUI服务了。
Open WebUI使用场景
Open WebUI提供了大量的大模型(LLMs)应用场景,使用起来也非常方便,本文将探讨如下使用场景:
模型问答: 使用vLLM框架部署模型,再使用Open
WebUI直接进行模型问答
多模型支持: 多模型回复比对(Qwen2-72B-Instruct, llama3-70b-8192,
mixtral-8x7b)
RAG场景1: 文档问答
RAG场景2: 使用Web Search进行问答
Function Calling: 需用Python实现工具(Tool)代码
多模态场景: 对图片进行问答(VQA)
Pipelines: pipeline编排,可自定义工作流程
模型问答
首先我们需要配置模型服务连接。在个人的Settings页面中,选择Admin
Settings,在Connections选项中,配置好我们自己部署或获取的OpenAI风格的API,配置页面如下:
open-webui-settings-connections.png
点击Save按钮进行保存。
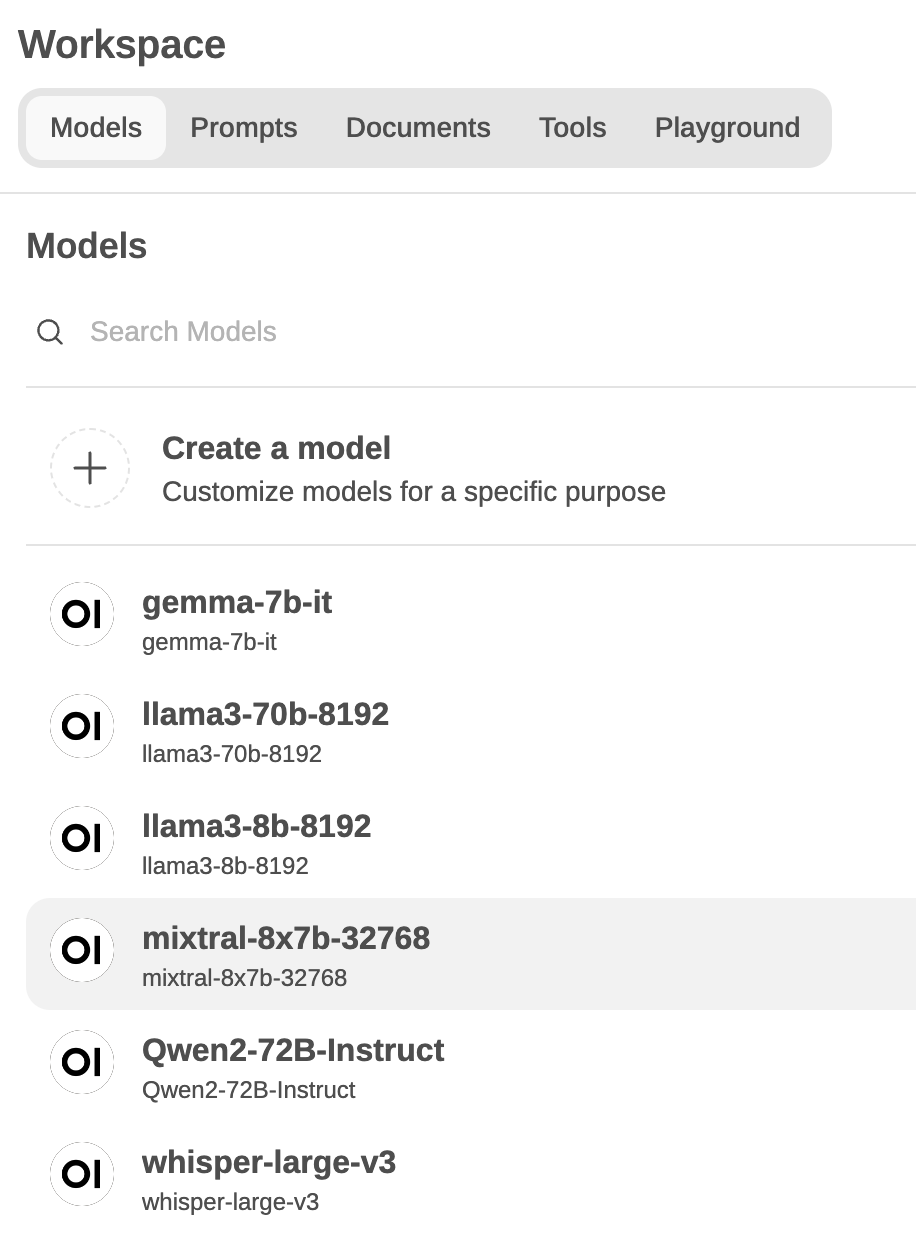
在首页中的Wokespace选项中,就能看到配置好的页面,如下图:
open-webui-workspace-models.png
在首页中,点击New
Chat创建新对话,点击+号选择Qwen2-72B-Instruct模型,这样就能使用该模型进行对话聊天了,样例对话如下图:
open-webui-new-chat-single-model.png
多模型问答
上述的例子为单个模型进行对话,Open
WebUI还支持多个模型同时回答,方便用户对不同模型的回复进行直观方便地进行对比。
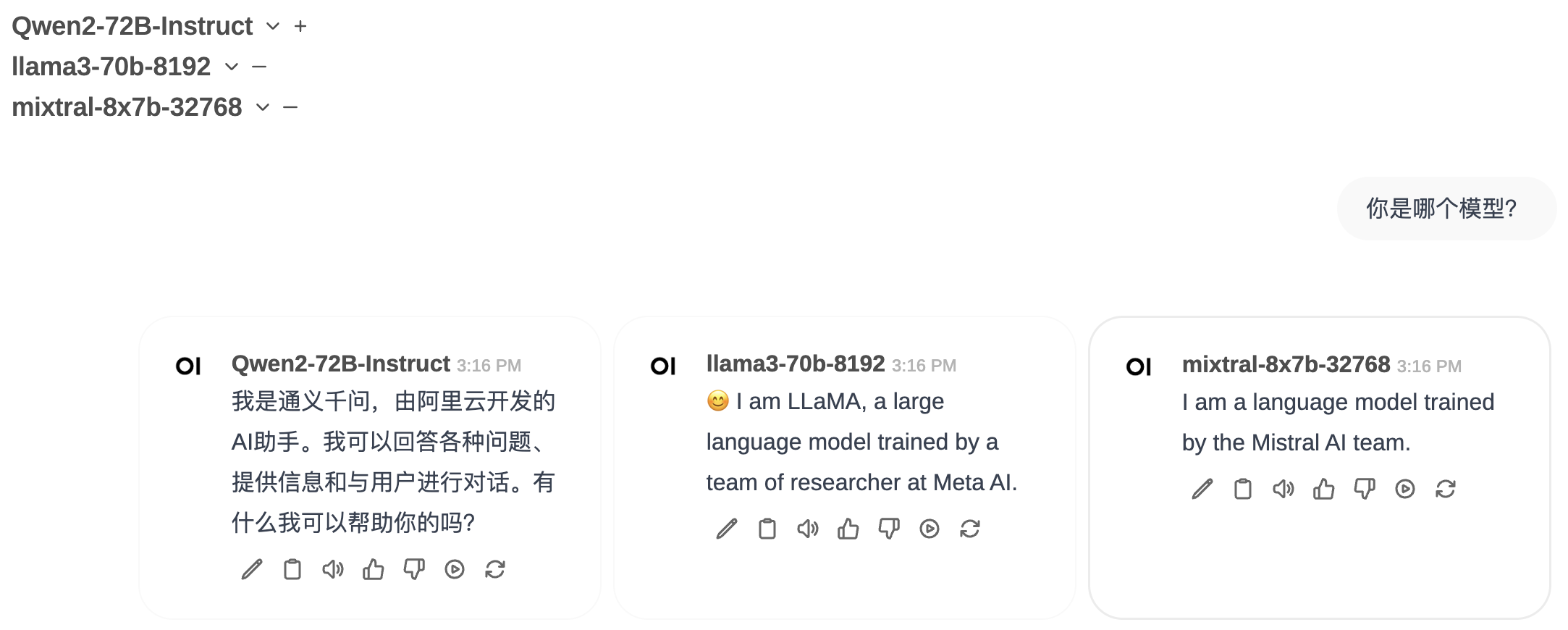
样例多模型回答如下图:
open-webui-new-chat-multi-model-1.png
open-webui-new-chat-multi-model-2.png
上面第二个问题是数学题目,选择的三个模型都回答正确。
文档问答
在Open WebUI中,可以很轻松地实现RAG场景中的文档问答。
首先我们需要上传一个示例PDF文档:oppo_n3_flip.pdf
。操作步骤为:在首页的Workspace中选择Documents栏,点击上传对应的PDF文件即可。在对相应文档进行问答时,只需要在聊天框中输入#号,再选择对应的文档即可。
或者,也可以直接在聊天框中点击+号,选择Upload
Files,可直接实现文档上传,再对文档直接进行回答就行了。
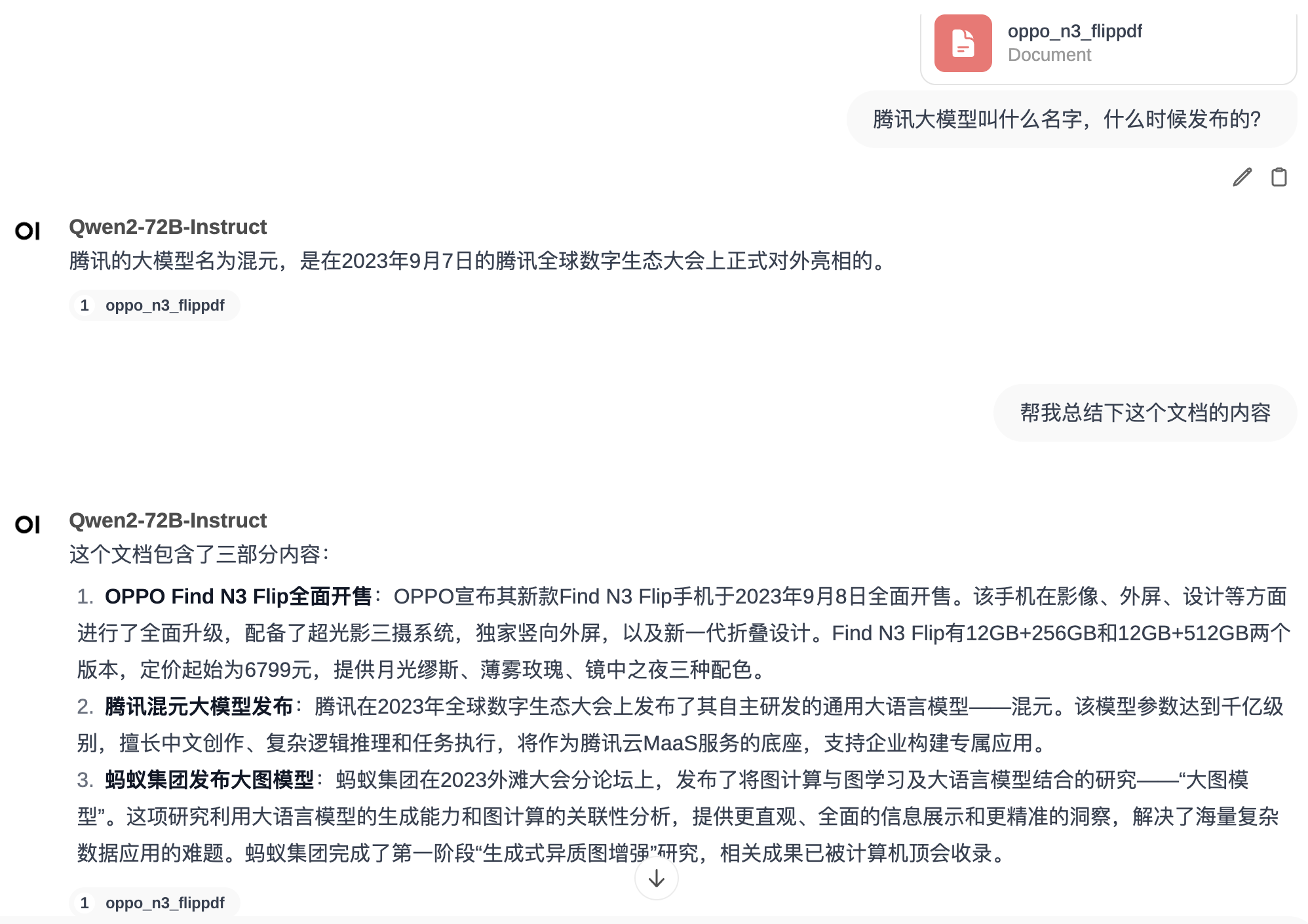
样例文档问答如下图:
open-webui-new-chat-doc-qa.png
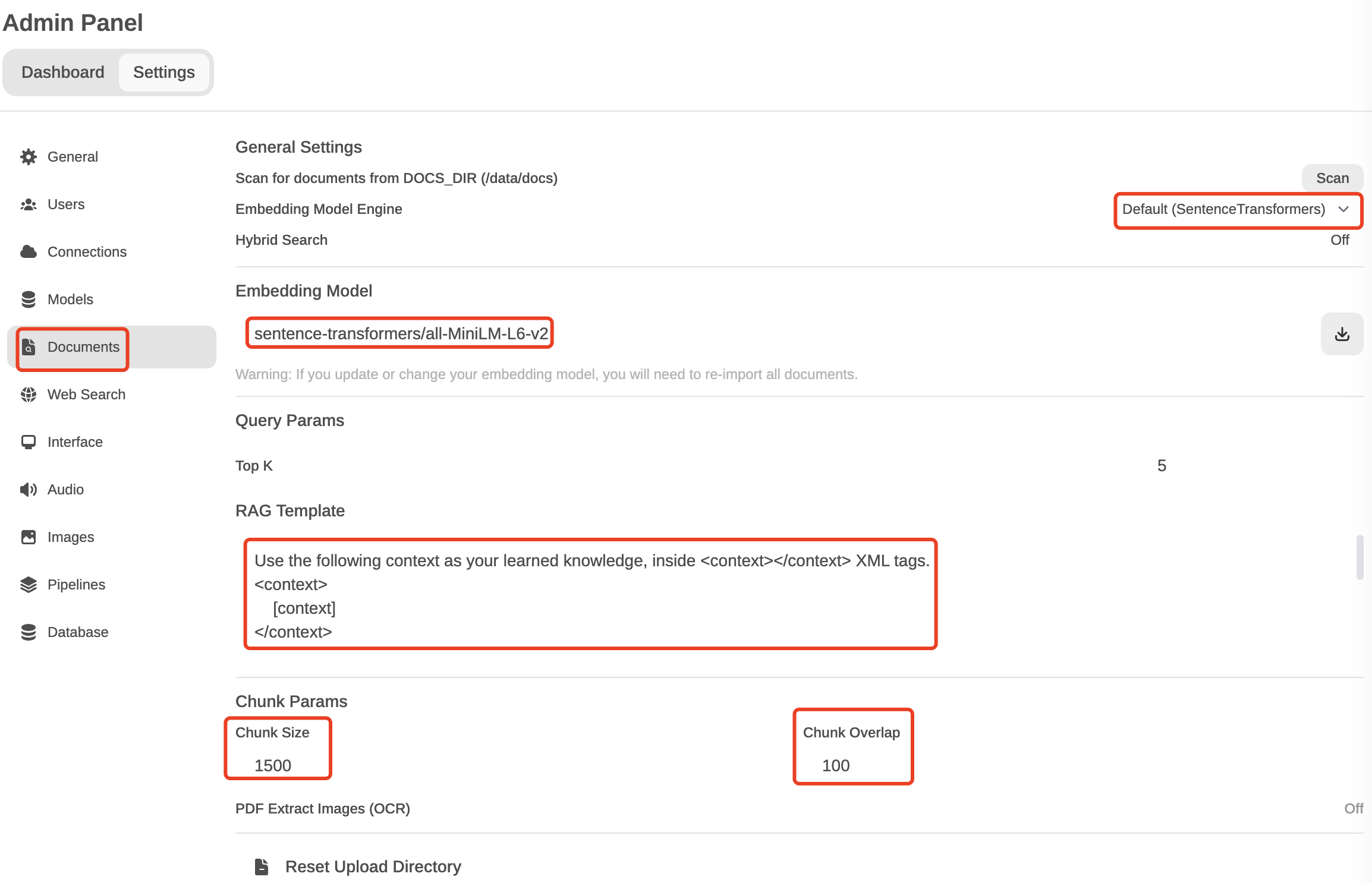
如果我们还想了解下在Open WebUI中是如何实现RAG框架的,可以在Settings
-> Admin Settings -> Documents中查看参数设置:
open-webui-new-chat-doc-qa-param.png
在默认的RAG
Documents配置中,选择的文档相似度计算方式为文本相似度,Embedding模型使用sentence-transformers/all-MiniLM-L6-v2
(注意 :这个模型在服务启动时就会下载并加载),同时也给出了问答回复模板(RAG
Template)。
Web Search问答
接下来,我们在来看RAG场景中的Web Search问答,此时,我们将web
search结果作为输入文档,整体的问答流程与上述的文档回答类似。
首先,我们需要配置搜索引擎参数:在 Settings -> Admin Settings
-> Web Search 中进行配置,选择Web Search
Engine为goole_pse,并配置好Google PSE API Key和Google PSE Engine
id,如下图:
open-webui-new-chat-web-qa.png
配置完Web
Search之后,我们可以在聊天中加入搜索引擎的内容了,此时,只需要再聊天框中的+号中开启Web
Search即可。
样例Web Search问答如下图:
open-webui-new-chat-web-qa.png
在上述的样例回答中,第一个问题没有使用Web
Search,可以看到大模型的回答不正确,产生了幻觉 ;第二个问题使用了Web
Search,回答正确,并且给出了参考网站,点击网址可查看网页的标题和内容。
Function Calling
Function
Calling允许大模型调用外部API或工具(Tool),从而进一步拓展大模型的知识范围。
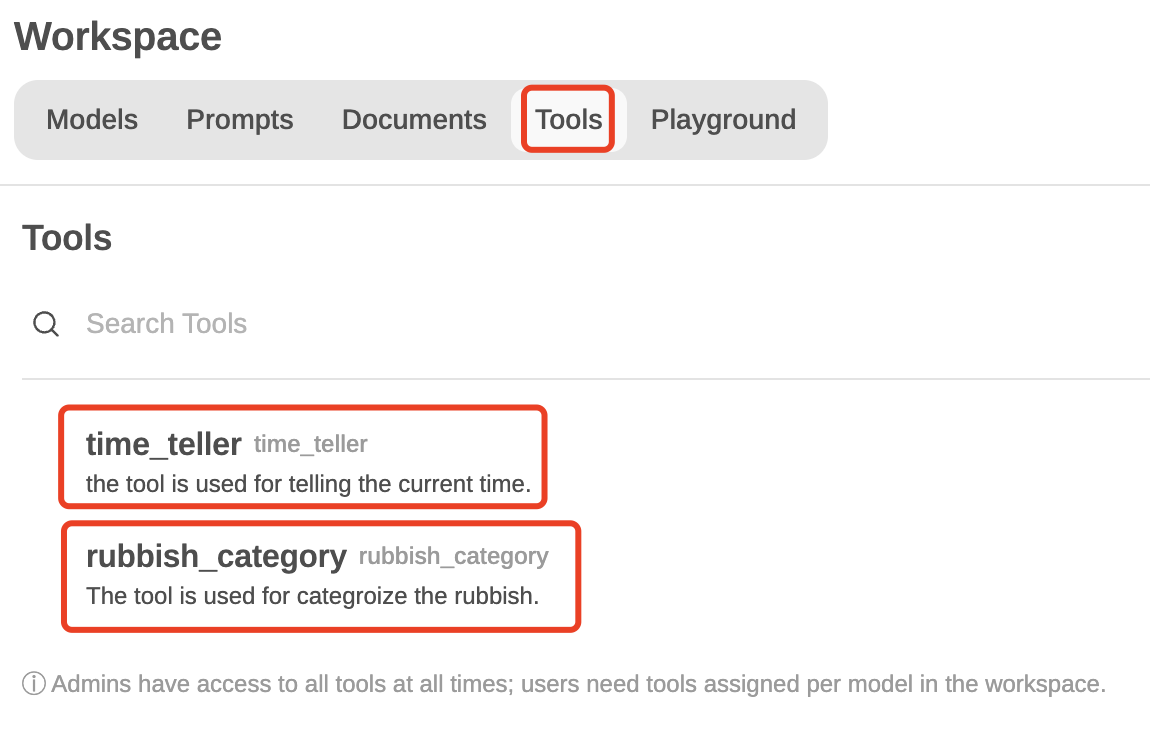
在首页的 Workspace -> Tools
中进行工具配置,此时需要按格式写好工具外调的Python代码。这里给出两个工具:time_teller和rubbbish_category,其中time_teller工具调用Python中的datetime模块给出当前时间,而rubbbish_category工具则借助外部API对用户问题中的垃圾进行垃圾分类。
open-webui-workspace-tools.png
其中,time_teller工具的Python实现代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import osimport requestsfrom datetime import datetimeclass Tools :def __init__ (self ):pass def get_current_time (self ) -> str :""" Get the current time in a more human-readable format. :return: The current time. """ "%I:%M:%S %p" ) "%A, %B %d, %Y" return f"Current Date and Time = {current_date} , {current_time} "
在聊天框中的+号开启time_teller工具即可使用该工具。
样例问答如下图:
open-webui-new-chat-tools-1.png
上述回答中,第一个问答调用了外部工具time_teller,因此大模型可以正确地回答当前时间,而第二个问题未开启外部工具,因而大模型无法回答当前时间。
rubbbish_category工具的Python实现代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import osimport requestsfrom datetime import datetimeclass Tools :def __init__ (self ):pass def get_rubbish_category (self, rubbish: str ) -> str :""" get the category of the rubbish. """ f"https://api.timelessq.com/garbage?keyword={rubbish} " "GET" , url)for item in response.json()["data" ]:f"{item['name' ]} : {item['categroy' ]} " )return "\n" .join(output_str_list)
样例问答如下图:
open-webui-new-chat-tools-2.png
上述回答中,第一个问题未调用外部工具,大模型的回答中规中矩;而第二个问题调用了外部工具rubbbish_category,借助外部API的数据,使得大模型的回答更加丰富,回复质量无疑比未调用工具时更高。
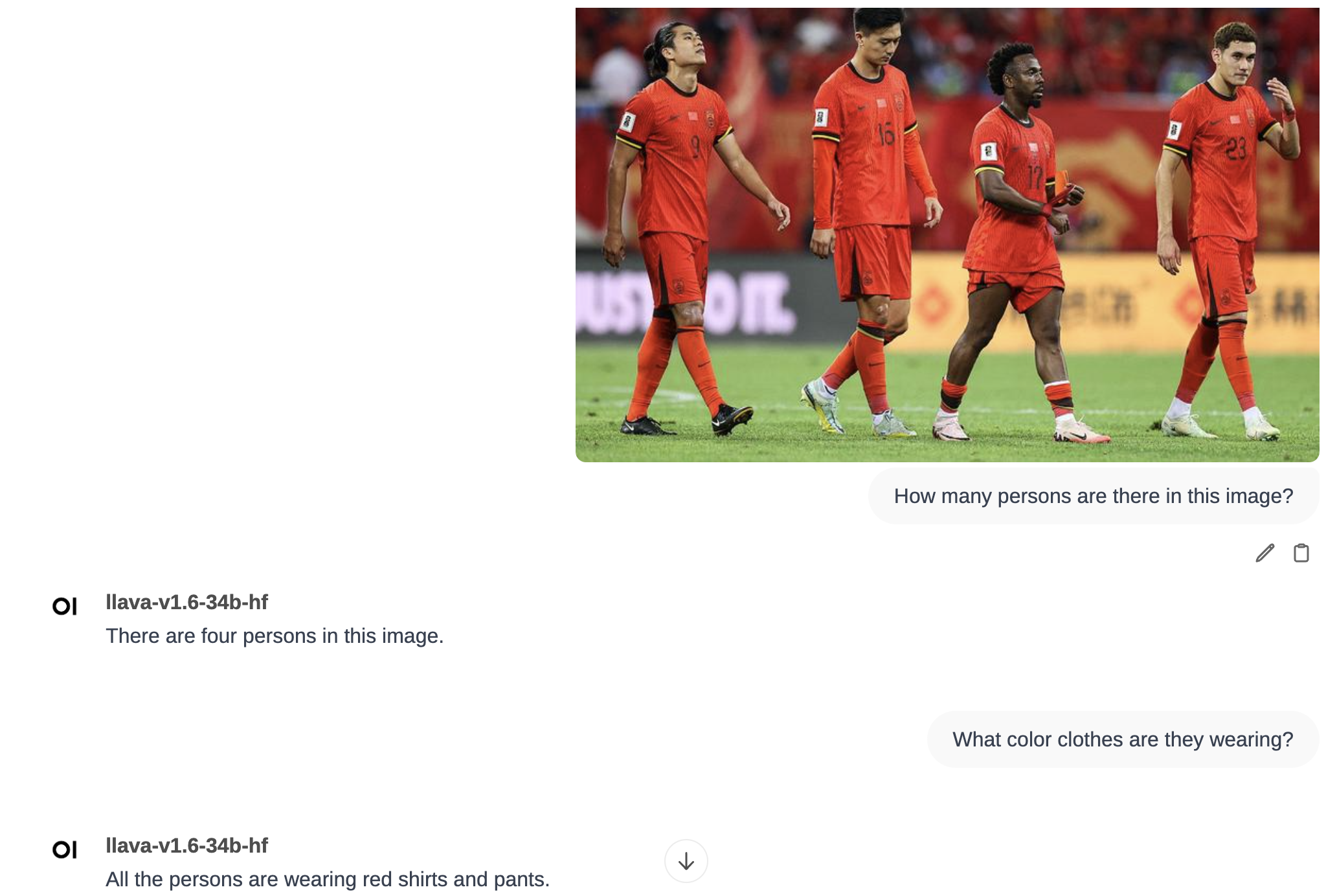
多模态问答
在上述的模型部署章节,我们已经完成了多模态模型llava-v1.6-34b-hf的部署,因此,可直接在Open WebUI中上传图片进行问答。
样例问答如下图:
open-webui-new-chat-multi-modal-qa.png
Pipelines
Pipelines允许我们在Open WebUI中自定义流水线作业,比如实现代码运行等。
本文不再给出Pipelines的使用方式,后续有机会将专门写这方面的文章进行介绍,计划是使用大模型解数学题目,其中回答过程中会给出Python代码,并需要获取Python代码运行结果。
Open WebUI其它功能
Open WebUI还提供了一些其它有用的小功能,本文尝试着讨论如下:
会话点赞/点踩功能
会话导出
代码语法高亮
Latex格式支持(公式需用$...$包围起来)
Swagger接口文档(需要授权,Bearer Token可在网页中直接找到)
会话点赞/点踩功能
Open WebUI的New
Chat中,支持对模型回复进行点赞/点踩,对模型回复进行评价,还有重新生成及继续生成功能,还支持对模型回复进行编辑。
对模型回复进行点赞/点踩,有助于为后续Reward
Model及RLHF阶段的训练提供数据集。
会话导出
Open WebUI还支持对话导出,点击···按钮,选择Download
-> Export Chat(.json),即可获得JSON格式的对话导出数据。
以时间查询对话为例,导出文件为chat-export-1719111625238.json,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 [ { "id" : "9412b79f-09c2-404d-84b1-bda48bc7463b" , "user_id" : "48343703-94f0-4b63-b954-2a995d3b7093" , "title" : "⏰ 查询时间 🕰️" , "chat" : { "id" : "" , "title" : "⏰ 查询时间 🕰️" , "models" : [ "Qwen2-72B-Instruct" ] , "options" : { } , "messages" : [ { "id" : "9cea61cf-d5d1-4236-8ec8-303ac8b28981" , "parentId" : null , "childrenIds" : [ "9cf1147b-b868-4ecb-884a-270549b43c77" ] , "role" : "user" , "content" : "现在几点了" , "timestamp" : 1718955676 , "models" : [ "Qwen2-72B-Instruct" ] } , { "parentId" : "9cea61cf-d5d1-4236-8ec8-303ac8b28981" , "id" : "9cf1147b-b868-4ecb-884a-270549b43c77" , "childrenIds" : [ "5472812b-aeb8-4f2e-a903-29a6bac42756" ] , "role" : "assistant" , "content" : "现在时间是下午03:41:17,但是请注意这个时间是基于2024年6月21日星期五的时间点。如果您需要当前实际时间,请查看您的设备时间。" , "model" : "Qwen2-72B-Instruct" , "modelName" : "Qwen2-72B-Instruct" , "userContext" : null , "timestamp" : 1718955676 , "done" : true } , { "id" : "5472812b-aeb8-4f2e-a903-29a6bac42756" , "parentId" : "9cf1147b-b868-4ecb-884a-270549b43c77" , "childrenIds" : [ "5b8f70b4-6517-4414-992c-890772b53b17" ] , "role" : "user" , "content" : "现在几点了" , "timestamp" : 1718955692 , "models" : [ "Qwen2-72B-Instruct" ] } , { "parentId" : "5472812b-aeb8-4f2e-a903-29a6bac42756" , "id" : "5b8f70b4-6517-4414-992c-890772b53b17" , "childrenIds" : [ ] , "role" : "assistant" , "content" : "对不起,作为一个AI,我无法实时提供当前的时间。请查看你所在设备的时间以获取准确时间。" , "model" : "Qwen2-72B-Instruct" , "modelName" : "Qwen2-72B-Instruct" , "userContext" : null , "timestamp" : 1718955692 , "done" : true } ] , "history" : { "messages" : { "9cea61cf-d5d1-4236-8ec8-303ac8b28981" : { "id" : "9cea61cf-d5d1-4236-8ec8-303ac8b28981" , "parentId" : null , "childrenIds" : [ "9cf1147b-b868-4ecb-884a-270549b43c77" ] , "role" : "user" , "content" : "现在几点了" , "timestamp" : 1718955676 , "models" : [ "Qwen2-72B-Instruct" ] } , "9cf1147b-b868-4ecb-884a-270549b43c77" : { "parentId" : "9cea61cf-d5d1-4236-8ec8-303ac8b28981" , "id" : "9cf1147b-b868-4ecb-884a-270549b43c77" , "childrenIds" : [ "5472812b-aeb8-4f2e-a903-29a6bac42756" ] , "role" : "assistant" , "content" : "现在时间是下午03:41:17,但是请注意这个时间是基于2024年6月21日星期五的时间点。如果您需要当前实际时间,请查看您的设备时间。" , "model" : "Qwen2-72B-Instruct" , "modelName" : "Qwen2-72B-Instruct" , "userContext" : null , "timestamp" : 1718955676 , "done" : true } , "5472812b-aeb8-4f2e-a903-29a6bac42756" : { "id" : "5472812b-aeb8-4f2e-a903-29a6bac42756" , "parentId" : "9cf1147b-b868-4ecb-884a-270549b43c77" , "childrenIds" : [ "5b8f70b4-6517-4414-992c-890772b53b17" ] , "role" : "user" , "content" : "现在几点了" , "timestamp" : 1718955692 , "models" : [ "Qwen2-72B-Instruct" ] } , "5b8f70b4-6517-4414-992c-890772b53b17" : { "parentId" : "5472812b-aeb8-4f2e-a903-29a6bac42756" , "id" : "5b8f70b4-6517-4414-992c-890772b53b17" , "childrenIds" : [ ] , "role" : "assistant" , "content" : "对不起,作为一个AI,我无法实时提供当前的时间。请查看你所在设备的时间以获取准确时间。" , "model" : "Qwen2-72B-Instruct" , "modelName" : "Qwen2-72B-Instruct" , "userContext" : null , "timestamp" : 1718955692 , "done" : true } } , "currentId" : "5b8f70b4-6517-4414-992c-890772b53b17" } , "tags" : [ ] , "timestamp" : 1718955676711 } , "updated_at" : 1718955693 , "created_at" : 1718955676 , "share_id" : null , "archived" : false } ]
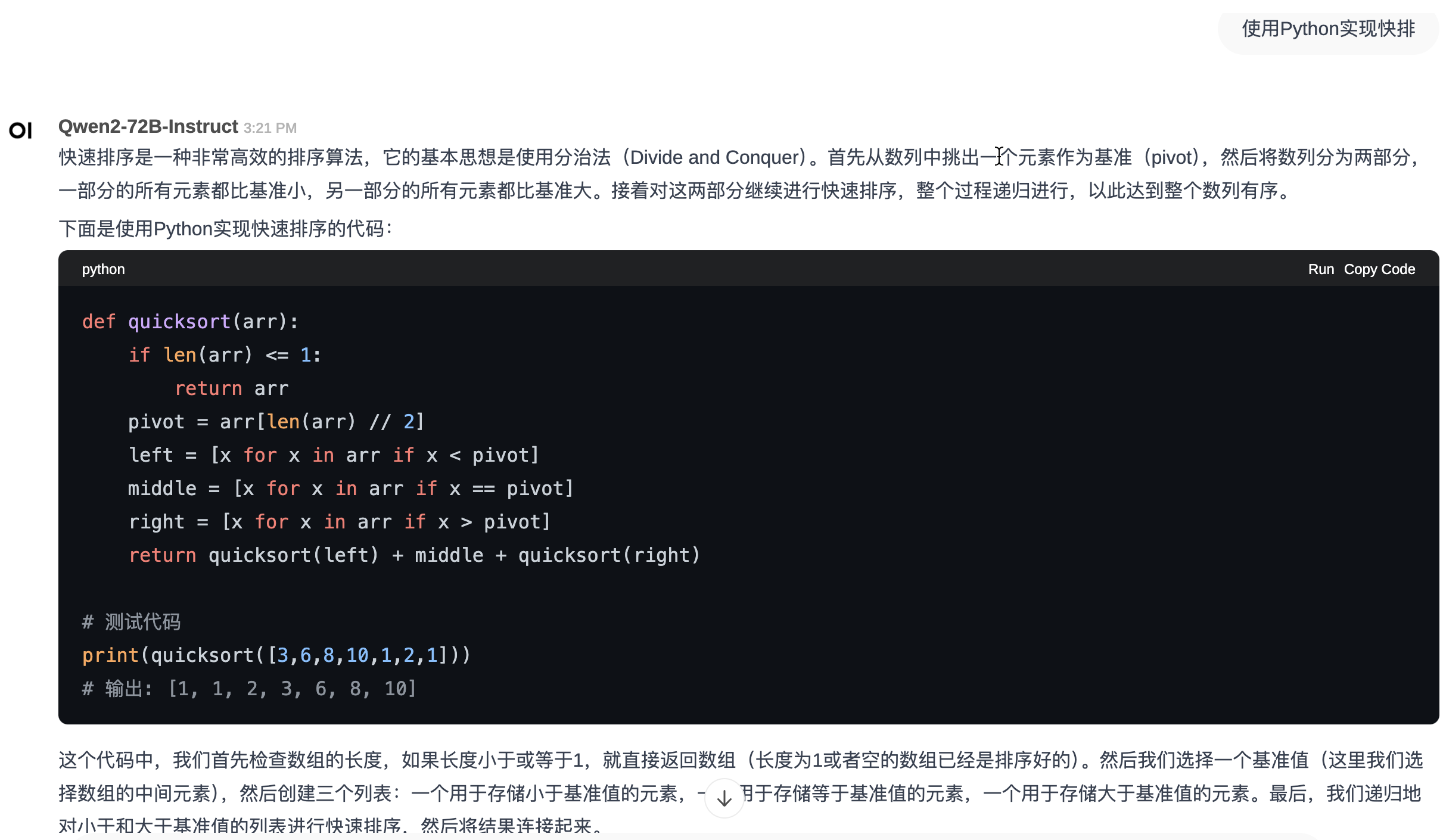
代码语法高亮
Open WebUI还支持对模型回复中的代码进行语法高亮,使得代码显示更优雅。
以快排程序为例,如下图:
open-webui-new-chat-code-highlight.png
Latex格式支持
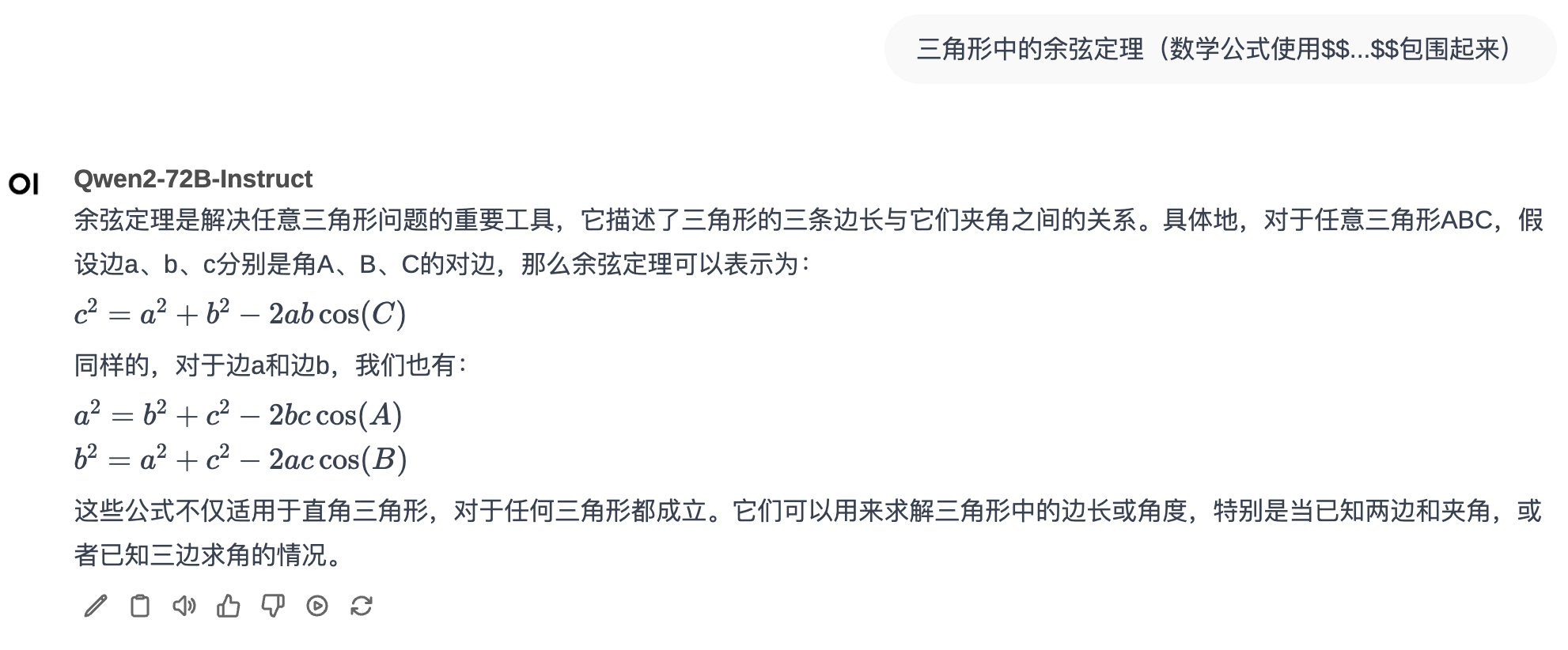
Open WebUI还支持对模型回复中的Latex格式的数学公式进行渲染,前提是数学公式需要用\[...\] 包围起来。
样例对话如下图:
open-webui-new-chat-latex.png
Swagger接口文档
Open WebUI还提供了平台完整功能的Swagger接口文档,如下:
WebUI
/api/v1/docs
Ollama
/ollama/docs
OpenAI
/openai/api/docs
Images
/images/api/v1/docs
Audio
/audio/api/v1/docs
RAG
/rag/api/v1/docs
以WebUI为例,在浏览器中输入http://localhost:8080/api/v1/docs 即会显示WebUI的Swagger接口文档。
点击右上方的Authorize按钮进行授权认证,Bearer
Token可在Open WebUI网页中的个人信息(Settings -> Account
-> API Key)中直接找到。
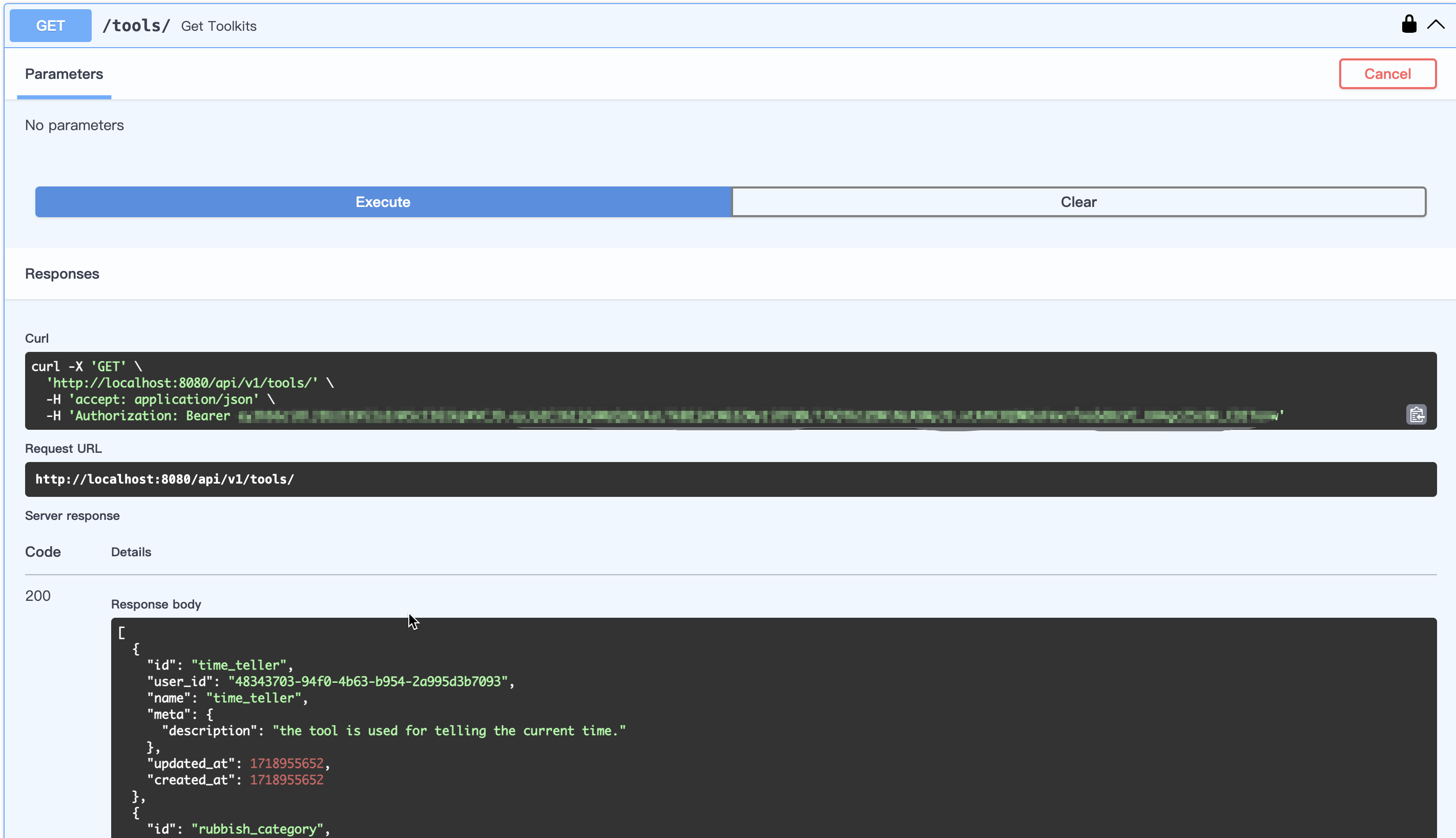
以获取工具接口(/tools/)为例,直接在页面进行测试,如下图:
open-webui-swagger-webui.png
总结
本文重点介绍了如何使用vLLM来部署通用模型Qwen2-72B-Instruct和多模态模型llava-v1.6-34b-hf,以及在Groq官网中获取llama3-70b-8192
和 mixtral-8x7b-32768模型的调用方式。
接着,本文介绍了Open WebUI的基本信息,以及一些重要特性,包括单/多模型回复、文档问答、Web
Search问答、Function Calling、多模态问答等,还有其它一些小功能等。
本文可作为Open WebUI的入门文章,后续笔者将探索Open WebUI的更多功能,欢迎关注~
参考文献
Latex support issue in Open Webui: https://github.com/open-webui/open-webui/issues/2615
NLP(九十六)使用LLaMA-Factory实现function calling: https://zhuanlan.zhihu.com/p/694577892
Quickstart of groq: https://console.groq.com/docs/quickstart
features of Open Webui: https://docs.openwebui.com/features/
vllm/tests/multimodal/test_processor.py: https://github.com/vllm-project/vllm/blob/main/tests/multimodal/test_processor.py