NLP(一百零九)Embedding中的Late-Chunking(迟分)策略
本文将会介绍Embedding模型中的Late Chunking(迟分)策略,演示多个中文Late Chunking的例子,并搭建相关Gradio服务,最后再展示其在RAG框架中对于大模型回复质量的提升作用。
Late Chunking技术及原理
Late Chunking(迟分)技术是Jina AI公司(<https://jina.ai)于今年8月份介绍的在Embedding模型方面的新技术。
众所周知,在保留上下文信息的同时对长文本进行分块并保证召回的效果,是一项有难度的挑战。而Late Chunking技术利用长上下文嵌入模型生成上下文的分块嵌入,以实现更好的检索应用。
Late Chunking(迟分)是一种先通读全文再分块的新方法,包含两个主要步骤:
- 编码全文:先编码整个文档,得到每个 token 的向量表示,保留完整的上下文信息。
- 分块池化:根据分块边界,对同一个文本块的 token 向量进行平均池化,生成每个文本块的向量。由于每个 token 的向量是在全文的语境下生成的,因此迟分可以保留块之间的上下文信息。
其原理如下图所示:
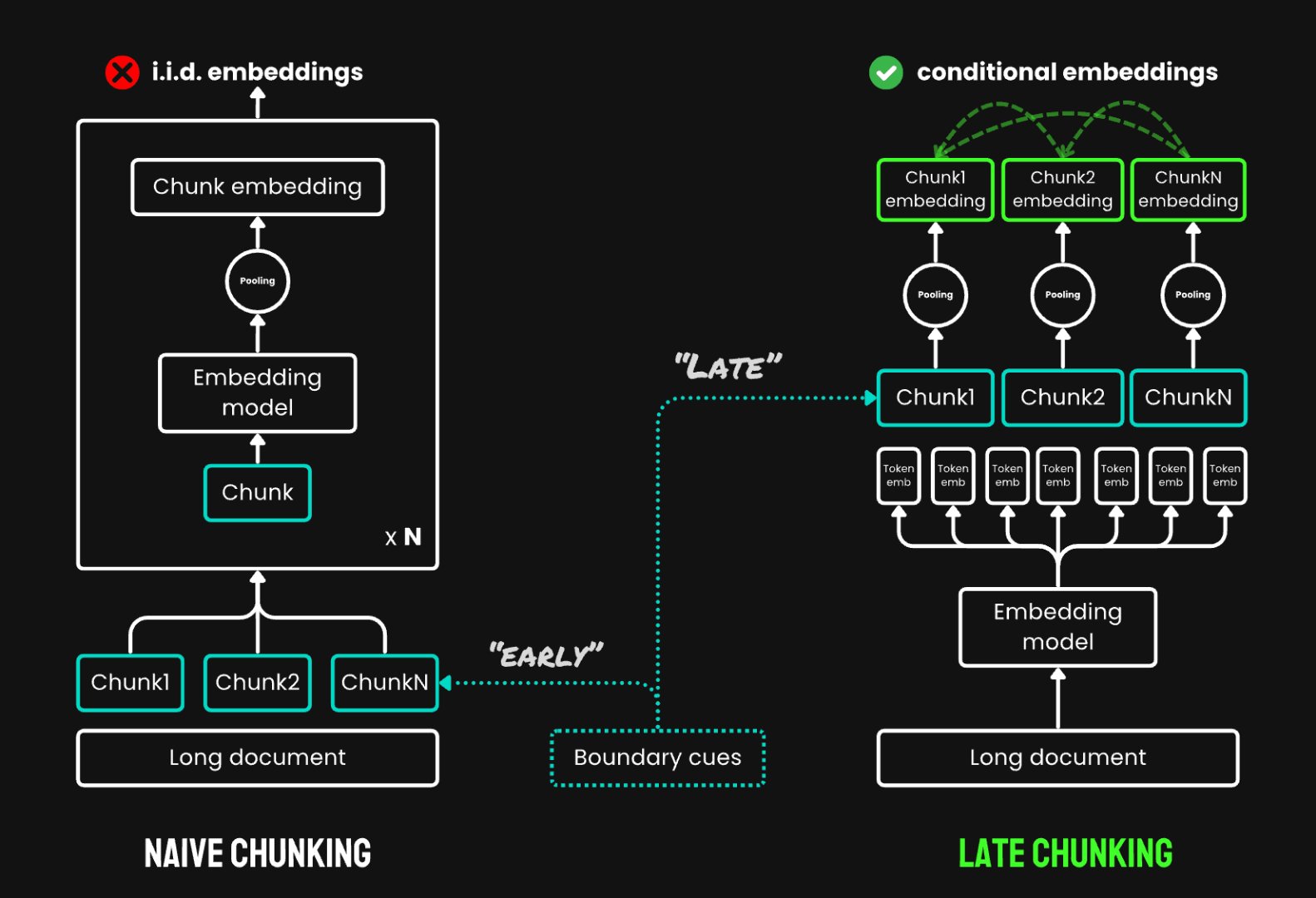
从上面的原理图中,我们可以看到,Late
Chunking技术并没有改变Embedding模型的内部结构,而是在对文本进行嵌入时改变了嵌入方式。传统的嵌入方式(Naive
Chunking)是先对文本进行切分,分别对每个chunk进行嵌入;而Late
Chunking是先对文本进行token级别的嵌入,获取每个token的嵌入,再根据文本块的token向量进行平均池化,生成每个文本块的嵌入向量,这也是它被称为“迟分”的原因。当然,Late
Chunking并不是对所有Embedding模型都会生效,目前只有Jina
AI的Embedding模型能做到。
Jina
AI官网给出了一个英语方面的生动例子,使用的Embedding模型为jina-embeddings-v2-base-en,对于输入的文本,按照句子进行切分,共生成3个chunk,输入的query为Berlin,朴素嵌入(即我们现在在用的常见的嵌入方式)和Late
Chunking的相似度分数计算如下:
| Query | Chunk | Sim. on naive chunking | Sim. on late chunking |
|---|---|---|---|
| Berlin | Berlin is the capital and largest city of Germany, both by area and by population. | 0.849 | 0.850 |
| Berlin | Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. | 0.708 | 0.825 |
| Berlin | The city is also one of the states of Germany, and is the third smallest state in the country in terms of area. | 0.753 | 0.850 |
从上面的英语例子中,我们可以看到Late Chunking很好地保留了上下文之间的信息,每个chunk与query之间的相似度都比较高,而朴素嵌入时其余两个文本中不含Berlin,因此与query的相似度较低。这个例子很好地展示了Late Chunking技术有不错的上下文信息保留能力。
网络上能搜索到的关于Late Chunking技术大概就这么多。笔者想要在这基础上再深入一步,探索Late Chunking的更多应用。
中文Late Chunking的例子
官网给出了Late
Chunking在英语方面的例子,这里我们将其扩充至中文。笔者选用的中文Embedding模型为jinaai/jina-embeddings-v2-base-zh,使用的示例文本为(来源于王安石的百度词条):
王安石(1021年12月19日-1086年5月21日),字介甫,号半山。抚州临川县(今属江西省抚州市)人。中国北宋时期政治家、文学家、思想家、改革家。庆历二年(1042年),王安石中进士,历任扬州签判、鄞县知县、舒州通判等职,政绩显著。宋仁宗末年,曾作《上仁宗皇帝言事书》,要求对宋初以来的法度进行全盘改革,但未被采纳。
- 加载模型:
1 | |
- 按句子进行切分
1 | |
- 对示例文本进行切分
1 | |
输出结果如下:
Chunks:
- "王安石(1021年12月19日-1086年5月21日),字介甫,号半山。"
- "抚州临川县(今属江西省抚州市)人。"
- "中国北宋时期政治家、文学家、思想家、改革家。"
- "庆历二年(1042年),王安石中进士,历任扬州签判、鄞县知县、舒州通判等职,政绩显著。"
- "宋仁宗末年,曾作《上仁宗皇帝言事书》,要求对宋初以来的法度进行全盘改革,但未被采纳。"- 定义late_chunking函数
1 | |
- 对比朴素嵌入与Late Chunking的结果
1 | |
输出结果如下:
similarity_new("王安石是哪个朝代的", "王安石(1021年12月19日-1086年5月21日),字介甫,号半山。"): 0.6774667
similarity_trad("王安石是哪个朝代的", "王安石(1021年12月19日-1086年5月21日),字介甫,号半山。"): 0.7342801
similarity_new("王安石是哪个朝代的", "抚州临川县(今属江西省抚州市)人。"): 0.61272216
similarity_trad("王安石是哪个朝代的", "抚州临川县(今属江西省抚州市)人。"): 0.27474773
similarity_new("王安石是哪个朝代的", "中国北宋时期政治家、文学家、思想家、改革家。"): 0.63981277
similarity_trad("王安石是哪个朝代的", "中国北宋时期政治家、文学家、思想家、改革家。"): 0.49549717
similarity_new("王安石是哪个朝代的", "庆历二年(1042年),王安石中进士,历任扬州签判、鄞县知县、舒州通判等职,政绩显著。"): 0.61709845
similarity_trad("王安石是哪个朝代的", "庆历二年(1042年),王安石中进士,历任扬州签判、鄞县知县、舒州通判等职,政绩显著。"): 0.57014936
similarity_new("王安石是哪个朝代的", "宋仁宗末年,曾作《上仁宗皇帝言事书》,要求对宋初以来的法度进行全盘改革,但未被采纳。"): 0.5486519
similarity_trad("王安石是哪个朝代的", "宋仁宗末年,曾作《上仁宗皇帝言事书》,要求对宋初以来的法度进行全盘改革,但未被采纳。"): 0.36279958根据上面的对比结果,我们输入的query为王安石是哪个朝代的,在朴素嵌入结果中,正确答案对应文本排在第三位,相似度分数为0.4955,而在Late
Chunking的结果中,正确答案对应文本排在第二位,相似度分数为0.6398。
由此可见,Late Chunking比朴素嵌入更能保留上下文信息,尤其是上下文之间存在指代关系的文本,Late Chunking的表现更为出色。
使用Gradio实现中文Late Chunking服务
上面的例子仅仅是中文Late
Chunking的一个简单例子,让我们来使用Gradio工具,实现中文Late
Chunking服务,将query的召回结果按照文本相似度排序,获得更为直观的展示。
搭建Gradio服务的Python代码如下:
1 | |
下面笔者将借助这个Gradio服务,来展示几个Late
Chunking与朴素嵌入的对比结果的例子。其中示例文本分别来自王安石和清明上河图密码百度词条。
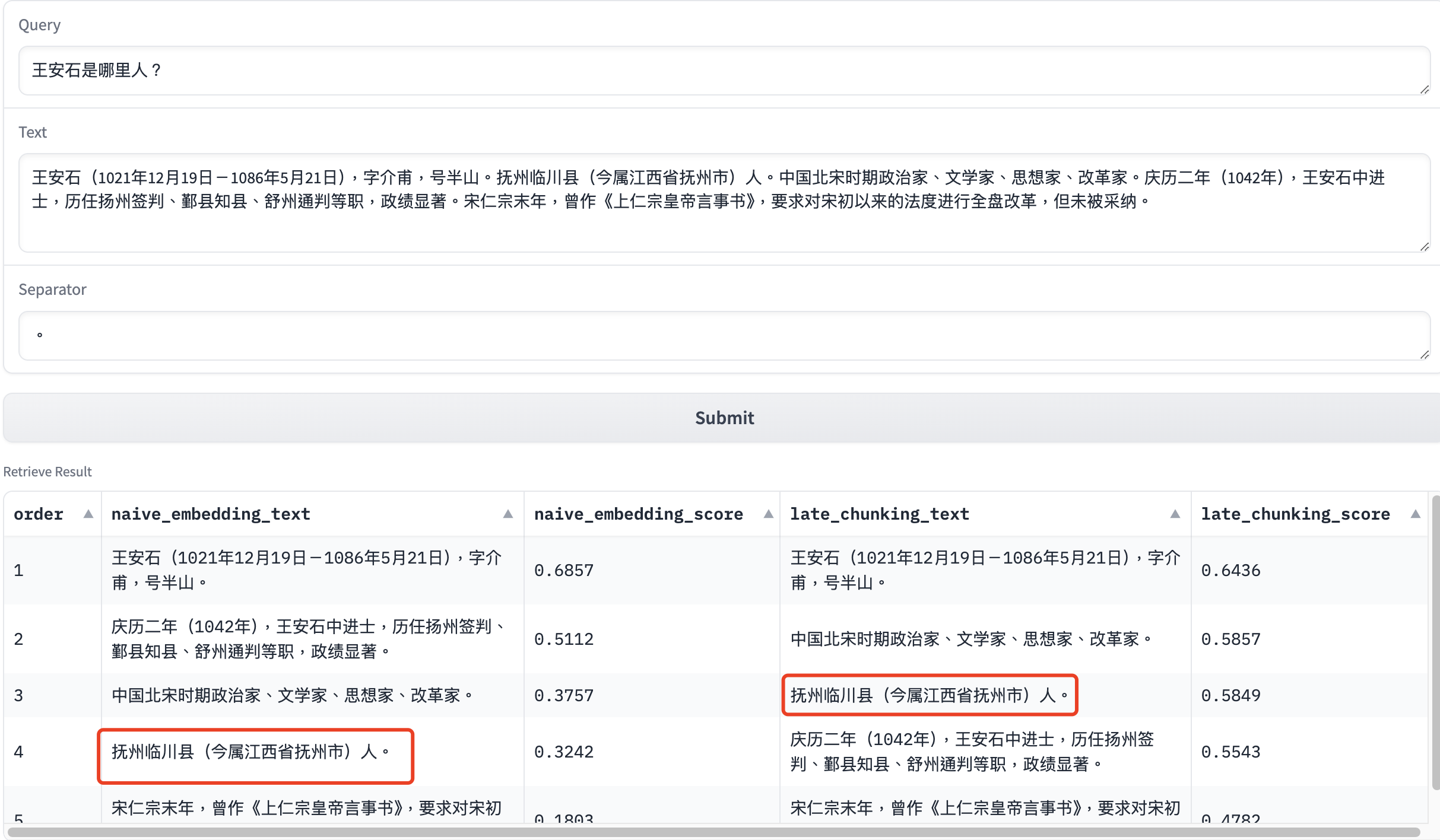
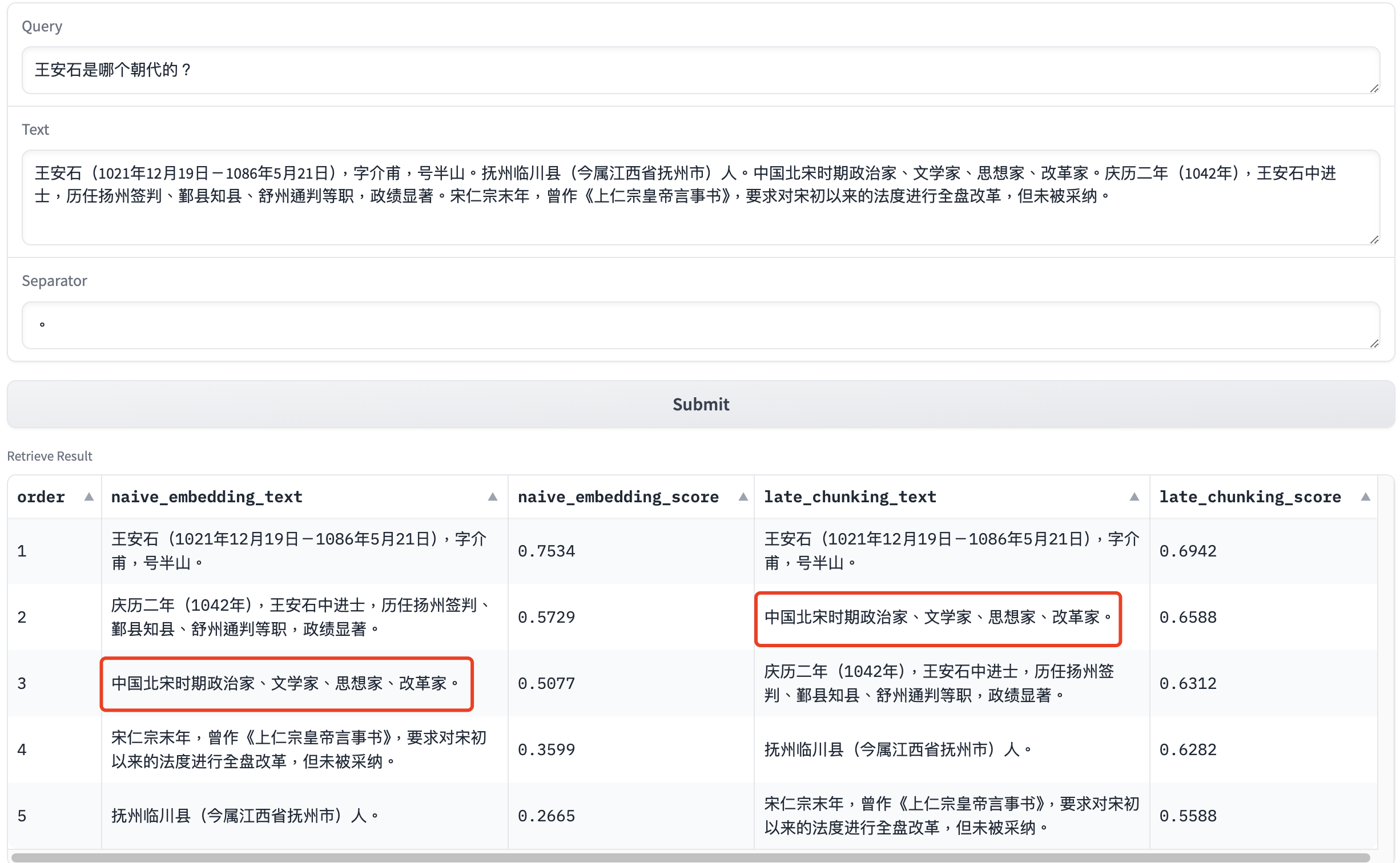
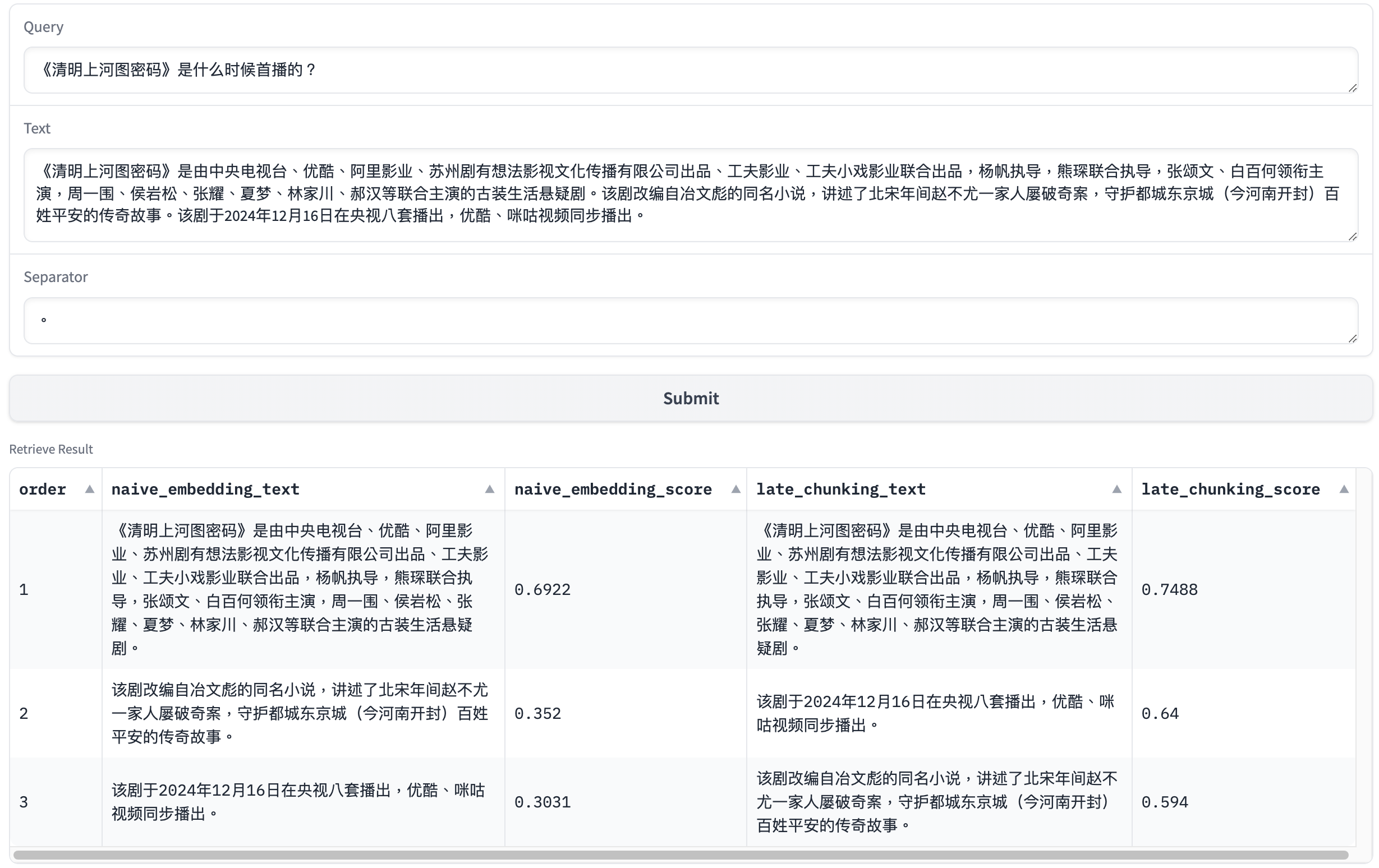
上面的几个例子中,Late Chunking的召回结果都比朴素嵌入的要好,这是因为这些文本块之间存在着明显的指代关系,而Late Chunking此时能很好地保留这些文本块之间的上下文信息。
上述的Gradio服务,笔者后续将会放在HuggingFace Spaces中进行部署,有兴趣的读者到时可以试用。
Late Chunking在RAG框架中的作用
下面笔者将会来介绍Late Chunking在RAG框架中的作用,看看Late Chunking是如何在RAG过程中提升召回效果,保证回复质量的。
我们的示例文本是关于蔚来ET9的,其文章标题为蔚来ET9正式上市 售78.8万元起,网址为
https://news.qq.com/rain/a/20241221A07RW900 。
我们对上面的Late Chunking中的切分方式做个小小的改动,之前是按照分隔符进行句子级别的切分,这里我们保留原文中的段落切分的方式。对于Embedding的召回结果,我们取top 4合并成参考文本,并使用大模型进行问题回复。
笔者实现了对比Late Chunking与朴素嵌入在RAG过程的回复结果的Python代码,如下:
1 | |
根据示例文本,笔者测试了三个简单的问题,对比结果如下:
| 序号 | 问题 | 朴素嵌入时LLM回复 | Late Chunking时LLM回复 |
|---|---|---|---|
| 1 | 蔚来ET9的车身强度是多少? | 文本中并没有提供关于蔚来ET9车身强度的具体信息,所以无法回答这个问题。 | 蔚来ET9的车身强度达到2000MPa。 |
| 2 | 蔚来ET9有多少个电动遮阳帘? | 文本中并未提到蔚来ET9的电动遮阳帘数量。因此,无法回答这个问题。 | 蔚来ET9配备了七扇电动遮阳帘。 |
| 3 | 蔚来ET9中的冰箱的最大容积是多少? | 文本中并没有提到蔚来ET9中包含冰箱或相关信息。因此,无法提供关于冰箱最大容积的数据。提到的是前备箱的容积为105L。 如果您有其他问题,请告知! | 蔚来ET9中的冰箱的最大容积达到10升。 |
当然,这只是演示了几个Late Chunking的召回效果比朴素嵌入效果好的例子,并不是说Late Chunking的召回效果就一定会比朴素嵌入效果好。
那么,沃我们在实际场景中该如何选择分块策略呢?
- 对于朴素分块,适合场景为:主题多样,需要检索特定信息;需要展示局部文本片段。
- 对于Late Chunking,适合场景为:主题连贯,需要上下文信息;需要平衡局部细节和全局语义。
读者可以仔细观察上面关于蔚来ET9的文章,测试的三个例子都来自这样的段落:段落中未提及蔚来ET9,而是用指代,但人类不难用上下文得到这些信息。说到来,这是一篇蔚来ET9的文章,主体连贯,因此很适合用Late Chunking,其保留上下文的能力在这种场景下会比朴素分块好。
总结
本文主要介绍了Embedding模型中的Late Chunking(迟分)策略,演示多个中文Late Chunking的例子,并搭建相关Gradio服务,最后再展示其在RAG框架中对于大模型回复质量的提升作用。
上面给出的Python代码均已开源至Github,网址为: https://github.com/percent4/embedding_rerank_retrieval 。
参考文献
- Jina AI官网: https://jina.ai/
- 在 Notebook的例子: https://colab.research.google.com/drive/15vNZb6AsU7byjYoaEtXuNu567JWNzXOz?usp=sharing#scrollTo=abe3d93b9e6609b9
- Jina AI官网关于Late Chunking的介绍: https://jina.ai/news/late-chunking-in-long-context-embedding-models/
- Late Chunking论文: https://arxiv.org/pdf/2409.04701
- 卷起来了!长文本向量模型分块策略大比拼: https://mp.weixin.qq.com/s/tWToc7Lu18nb6TwuZ_bz1g