NLP(一百零二)ReRank模型微调实践
本文将会介绍如何使用
Sentence Transformers框架来对ReRrank模型进行微调,并比较模型微调前后的效果。
在文章NLP(八十三)RAG框架中的Rerank算法评估中,笔者详细介绍了RAG框架中的两种ReRank模型的评估实验:bge-reranker和Cohere Rerank。
在文章NLP(一百零一)Embedding模型微调实践中,笔者介绍了如何使用Sentence Transformers和AutoTrain框架对开源的Embedding模型bge-base-zh-v1.5进行微调,并验证Embedding模型微调后的效果。
本文将会在此基础上,重点介绍如何使用Sentence Transformers框架来对ReRrank模型进行微调,并比较模型微调前后的效果,在这里,笔者选择的ReRank模型为bge-reranker-base和bge-reranker-large。
数据合成
在文章NLP(一百零一)Embedding模型微调实践中,笔者介绍了如何生成Embedding模型微调数据,本文将在此基础上合成ReRank模型微调的训练数据集和验证数据集。
对于训练数据集和验证数据集,我们选取query和passage文本对,如果query与passage匹配,则该文本对的标签(label)为1,反之则标签为0。对于已有的Embedding微调训练数据,我们对每个query,选取一个匹配的passage和四个不匹配的passage,保存为csv格式文件。
ReRank微调模型的数据合成脚本如下:
1 | |
模型微调
基于Sentence Transformers框架官网官网给出的ReRank模型微调脚本,笔者略作调整,使之适应实验数据集。
一般,ReRank模型微调采用Cross-Encoder框架,如下图:
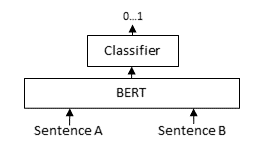
在我们的数据集中,label为0和1,此时采用Cross-Encoder框架进行训练,生成的数值应当为0-1之间的实数。
模型微调脚本也比较简单,Python代码如下:
1 | |
笔者分别对bge-reranker-base和bge-reranker-large模型进行微调,得到训练后的ReRank模型为ft-bge-reranker-base和ft-bge-reranker-large。
评估实验
让我们继续文章NLP(八十三)RAG框架中的Rerank算法评估中的Retrieve算法的评估实验。
我们选用Ensemble Retrieve方式,其中关键词召回使用BM25,向量召回使用OpenAI Embedding模型。在Ensemble召回基础上,再使用ReRank模型进行精排,得到最终的召回结果。
之前,我们的文章中,对Cohere ReRank, bge-reranker-base和bge-reranker-large这三种ReRank模型进行了评估实验,在本文中,笔者再加入刚才已微调后的ReRank模型:ft-bge-reranker-base和ft-bge-reranker-large。
在这里,不再给出具体的评估代码,有兴趣的读者可以参考Github项目: embedding_rerank_retrieval .
让我们来看看模型微调前后的评估结果,这里我们使用的评估指标为Hit Rate和MRR。
bge-rerank-base:
| retrievers | hit_rate | mrr |
|---|---|---|
| ensemble_bge_base_rerank_top_1_eval | 0.8255 | 0.8255 |
| ensemble_bge_base_rerank_top_2_eval | 0.8785 | 0.8489 |
| ensemble_bge_base_rerank_top_3_eval | 0.9346 | 0.8686 |
| ensemble_bge_base_rerank_top_4_eval | 0.947 | 0.872 |
| ensemble_bge_base_rerank_top_5_eval | 0.9564 | 0.8693 |
bge-rerank-large:
| retrievers | hit_rate | mrr |
|---|---|---|
| ensemble_bge_large_rerank_top_1_eval | 0.8224 | 0.8224 |
| ensemble_bge_large_rerank_top_2_eval | 0.8847 | 0.8364 |
| ensemble_bge_large_rerank_top_3_eval | 0.9377 | 0.8572 |
| ensemble_bge_large_rerank_top_4_eval | 0.9502 | 0.8564 |
| ensemble_bge_large_rerank_top_5_eval | 0.9626 | 0.8537 |
ft-bge-rerank-base:
| retrievers | hit_rate | mrr |
|---|---|---|
| ensemble_ft_bge_base_rerank_top_1_eval | 0.8474 | 0.8474 |
| ensemble_ft_bge_base_rerank_top_2_eval | 0.9003 | 0.8816 |
| ensemble_ft_bge_base_rerank_top_3_eval | 0.9408 | 0.9102 |
| ensemble_ft_bge_base_rerank_top_4_eval | 0.9533 | 0.9180 |
| ensemble_ft_bge_base_rerank_top_5_eval | 0.9657 | 0.9240 |
ft-bge-rerank-large:
| retrievers | hit_rate | mrr |
|---|---|---|
| ensemble_ft_bge_large_rerank_top_1_eval | 0.8474 | 0.8474 |
| ensemble_ft_bge_large_rerank_top_2_eval | 0.9003 | 0.8769 |
| ensemble_ft_bge_large_rerank_top_3_eval | 0.9439 | 0.9024 |
| ensemble_ft_bge_large_rerank_top_4_eval | 0.9564 | 0.9029 |
| ensemble_ft_bge_large_rerank_top_5_eval | 0.9688 | 0.9028 |
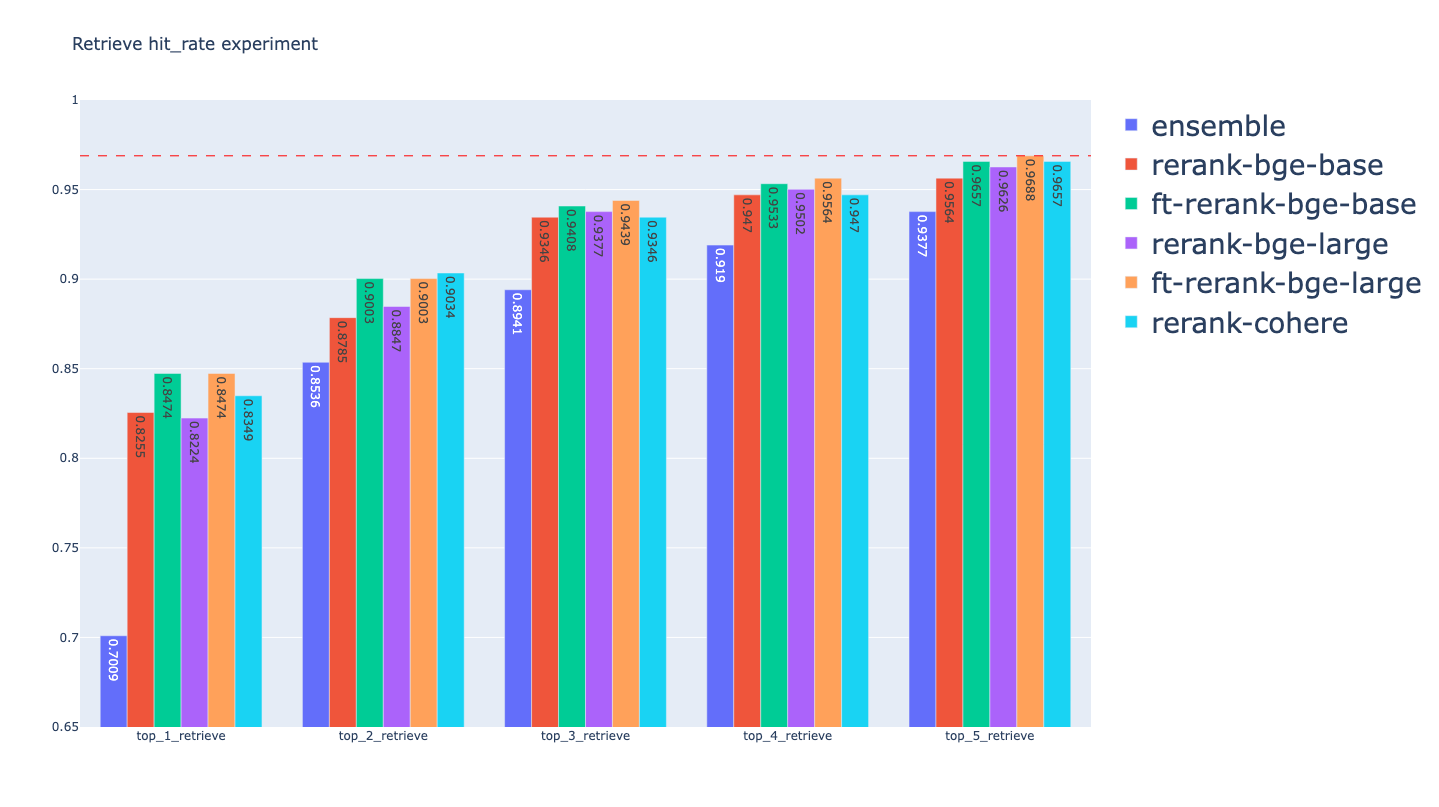
综上,我们可以看到:
- 微调后的ReRank模型的召回指标优于未微调模型
- 微调后的ReRank模型的召回指标优于或者持平Cohere ReRank模型
- 就本次评估实验结果而言,在召回指标上的效果:ft_bge_large_rerank > ft-bge-rerank-base > Cohere ReRank > bge-rerank-large > bge-rerank-base
总结
本文使用Sentence Transformers框架来对ReRrank模型进行微调,并比较模型微调前后的效果,发现微调后的ReRank模型表现优于未微调的ReRank模型。
本文所使用的Python均已开源,其中微调代码的Github网址为:https://github.com/percent4/embedding_model_exp,Retrieve算法评估实验的Github网址为: https://github.com/percent4/embedding_rerank_retrieval .
参考文献
- NLP(八十三)RAG框架中的Rerank算法评估
- NLP(一百零一)Embedding模型微调实践
- Training Examples » MS MARCO: https://sbert.net/examples/training/ms_marco/cross_encoder_README.html
- train_cross-encoder_scratch.py: https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/ms_marco/train_cross-encoder_scratch.py