本文将会介绍一个在深度学习领域很好用的开源标注平台工具Label
Studio,并演示在该平台上进行常见的NLP和CV任务的标注。
引言
Label Studio是最近开源领域很火的一个标注平台,它能轻松胜任各种深度学习领域常见的标注任务,包括NLP,
CV,语音处理,时间序列分析等方向,它提供了对用户极其友好的使用界面,提供的标注任务覆盖场景广泛,功能强大,使得繁杂的标注任务能够事倍功半。
Label Studio的官网为https://labelstud.io/ ,其开源网址为https://github.com/HumanSignal/label-studio/
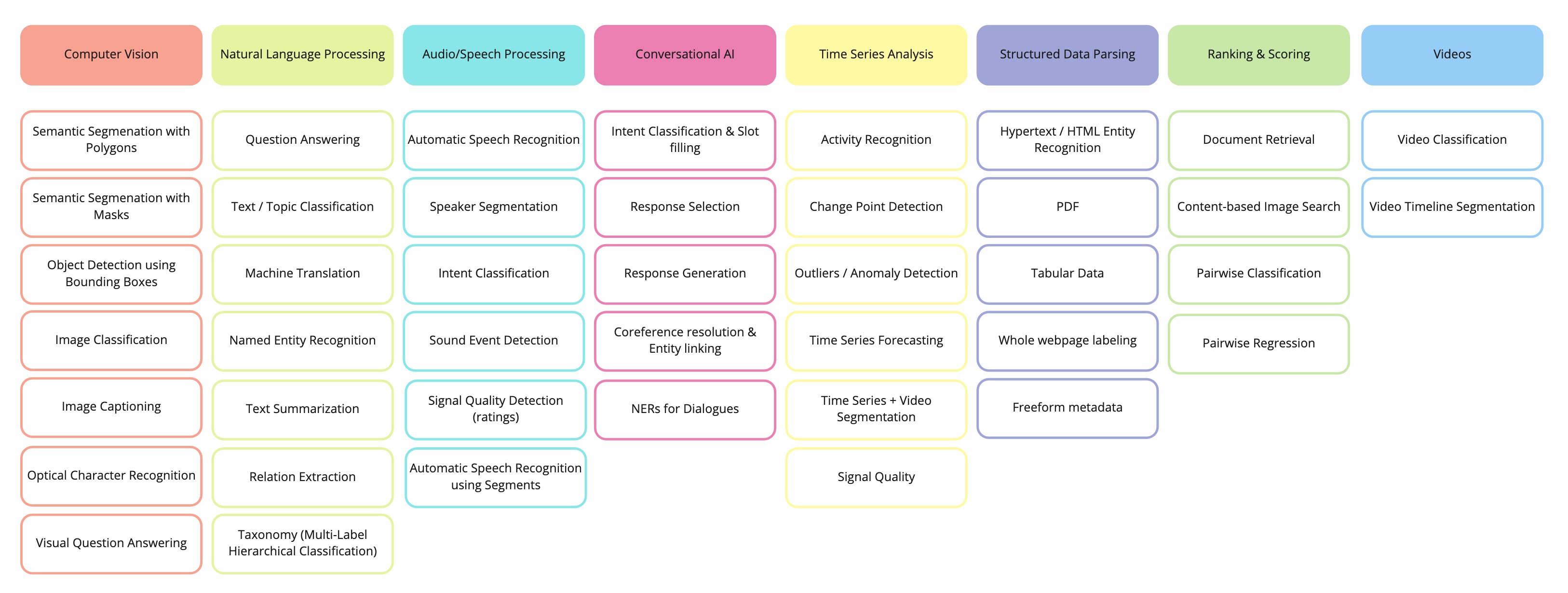
,它提供的标注任务如下:
Label Studio提供的标注任务
接下来,笔者将会演示如何使用Label Studio来完成常见的NLP和CV方向的标注任务,以下面四个任务为例:
文本分类
命名实体识别(NER)
物体检测
光学字符识别(OCR)
在本文中,我们使用Docker在本地启动Label Studio的服务,命令如下:
1 docker run -itd -p 8180:8080 -v $(pwd )/my-ls-data:/label-studio/data heartexlabs/label-studio:latest
在浏览器中输入网址 http://localhost:8180 ,即可访问该标注平台。
文本分类
文本分类任务是NLP方向最为常见的任务,它的主要目标是给指定的文本进行分类,常见的分类形式有多分类和多标签分类。以简单的多分类为例,它会提供多个类别,为每个指定的文本打上最符合的单个标签。
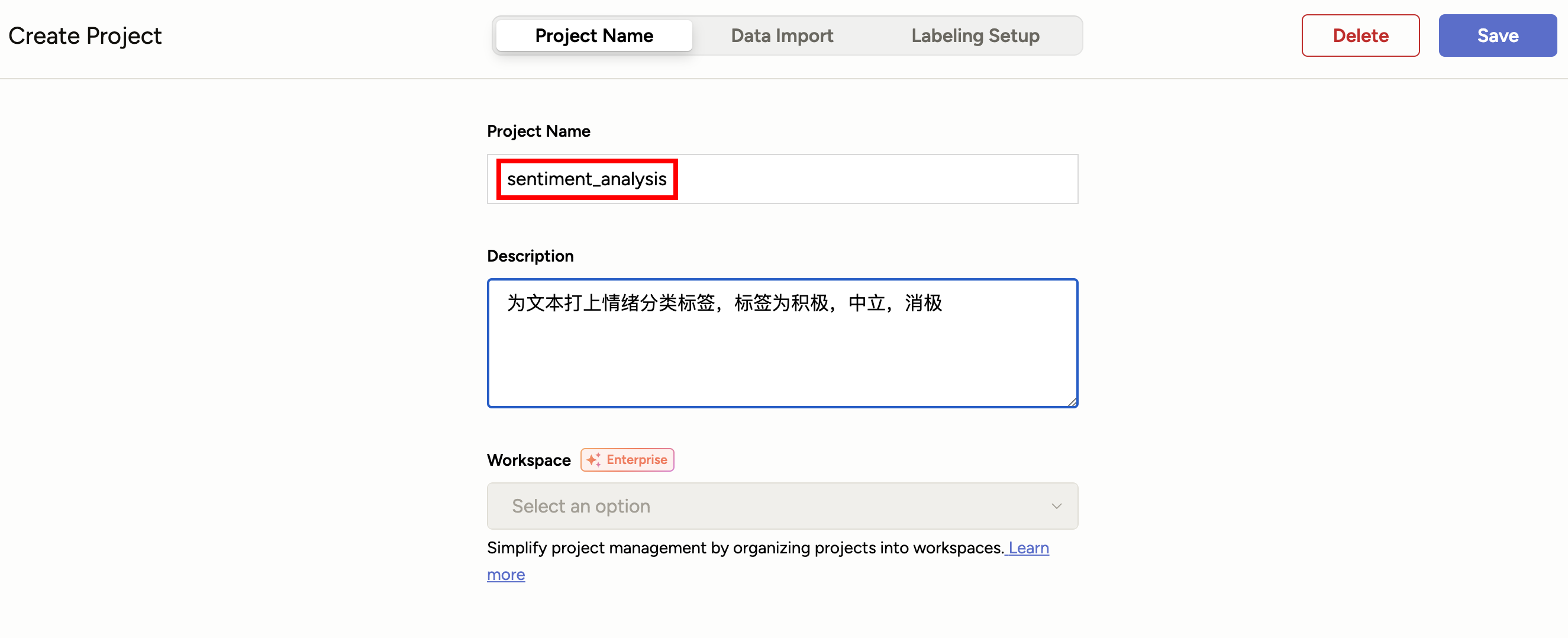
我们假设以下任务:对文本进行分类,标签为积极,中立,消极中的一个,标签为情绪方面的三个类别。
在Label Studio页面中,创建一个名为"sentiment_analysis"的文本标注任务,如下:
创建任务
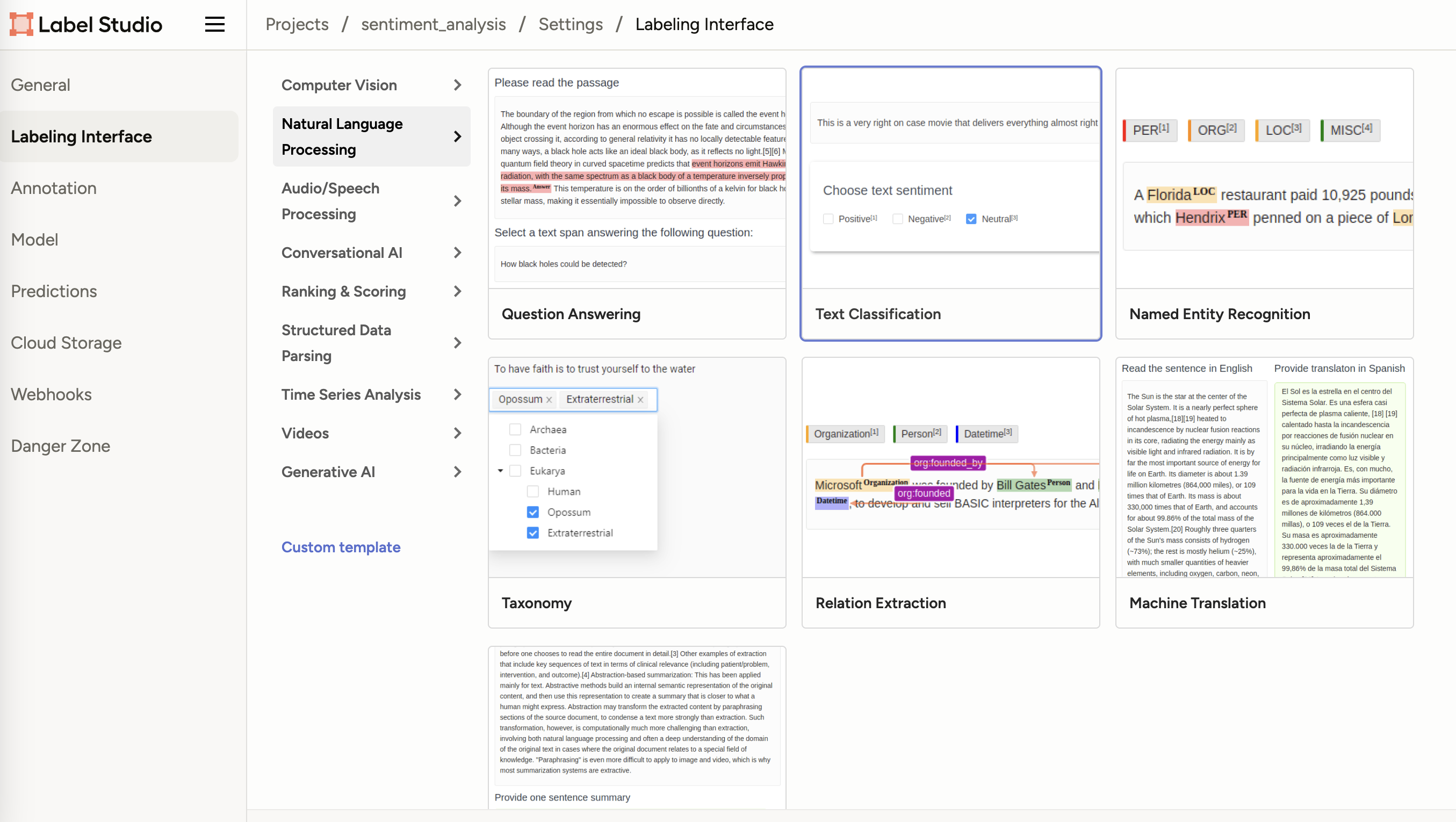
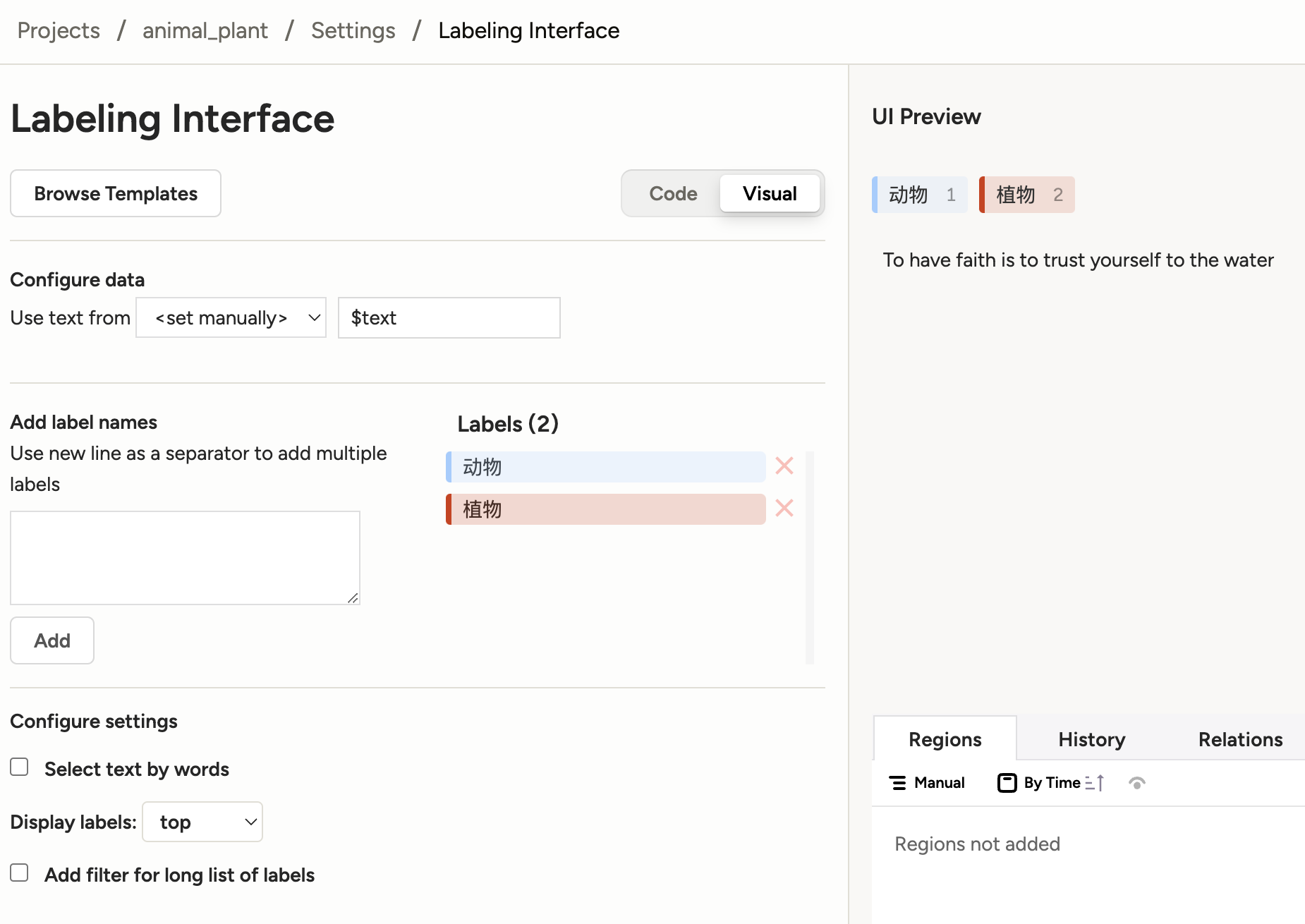
创立好任务后,在Settings选项中进行任务设置。在Labeling
Interface中,选择Natural Language Processing中的Text
Classification。
选择文本分类任务
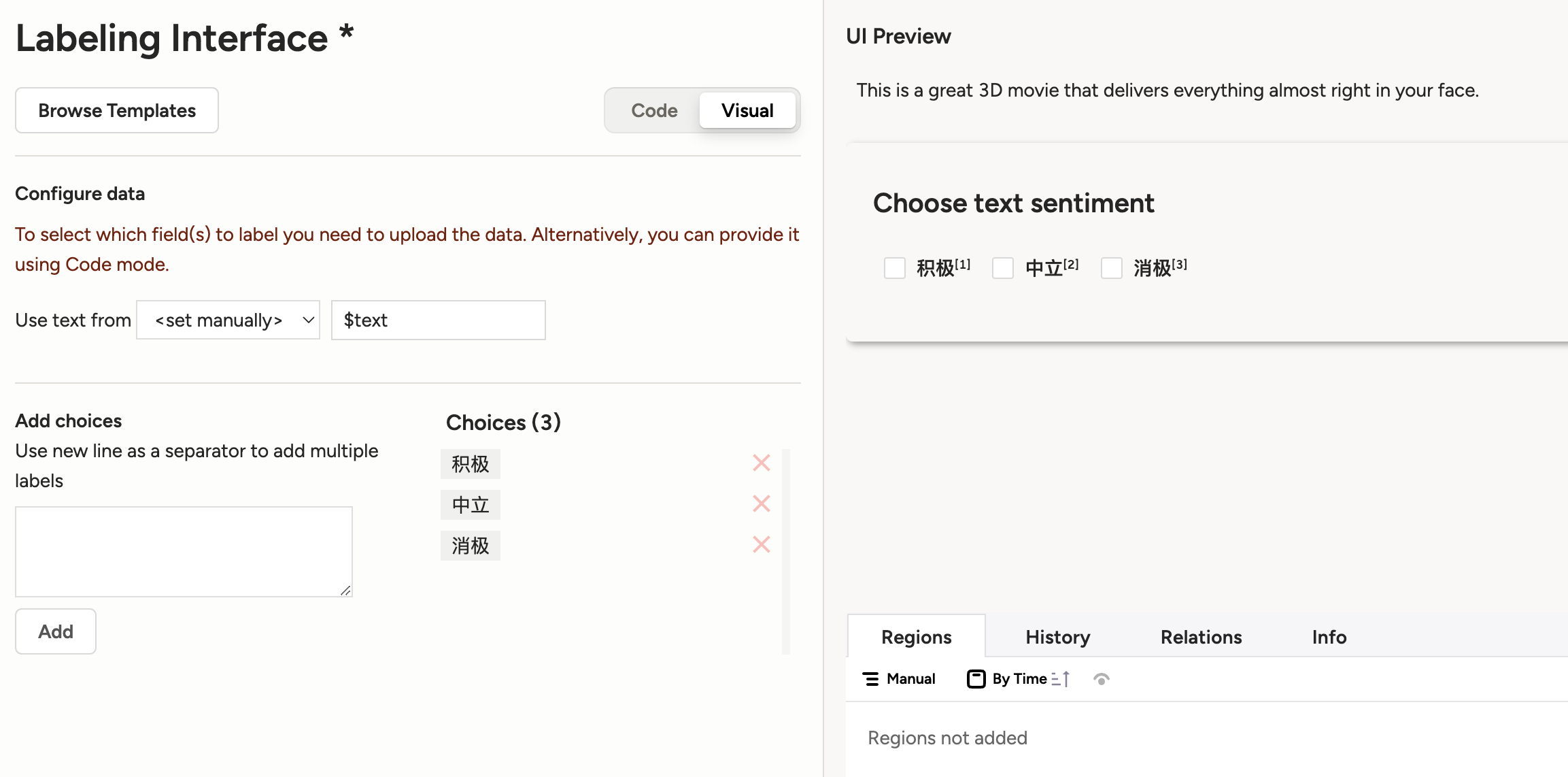
设置文本分类的标签,删除原来模板中的标签,添加新的三个标签:积极,中立和消极。
添加文本分类标签
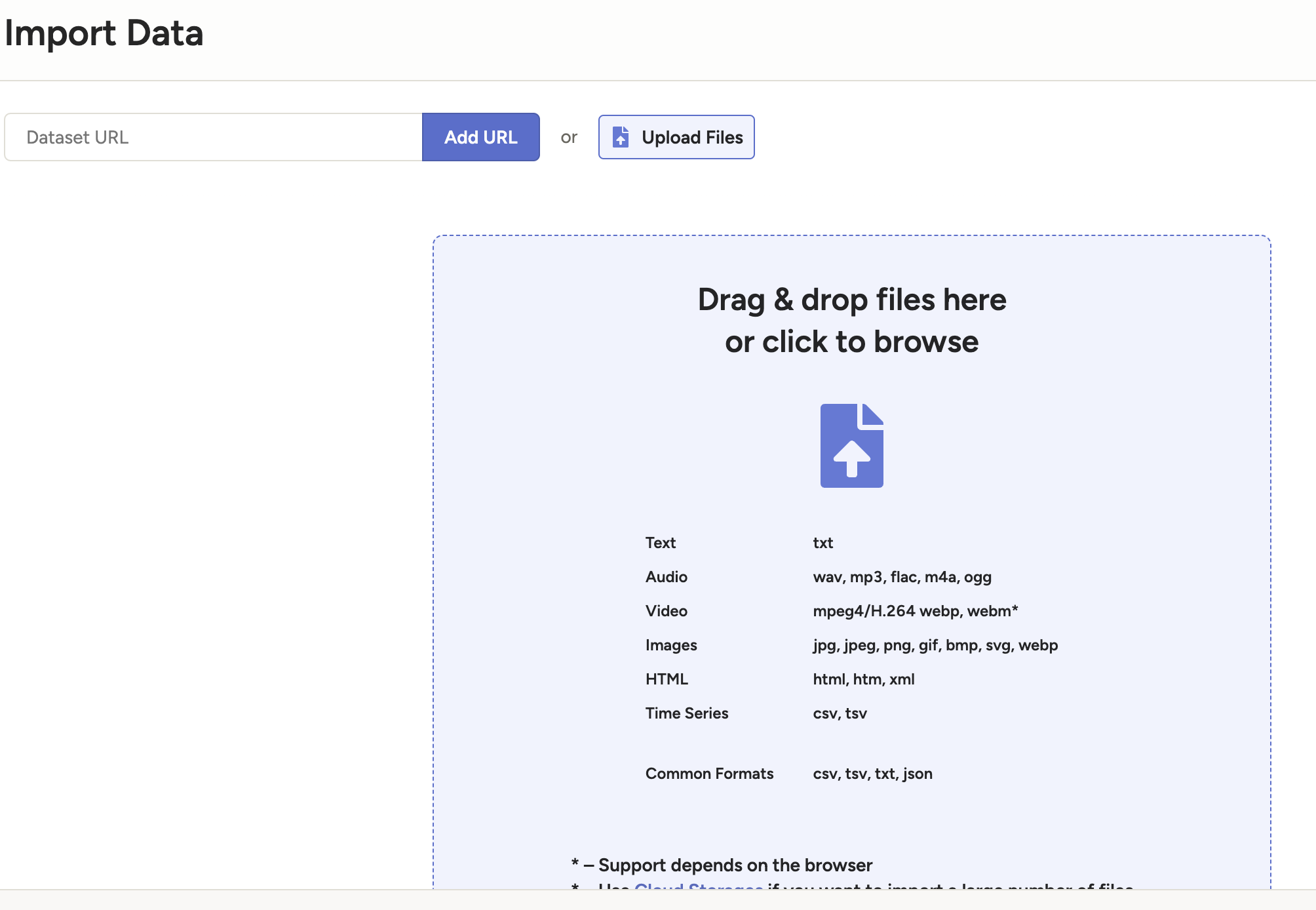
导入数据,选择上传文件为本地的sample.txt,内容如下:
1 2 3 今天的工作进展顺利,团队合作非常愉快,大家都充满了干劲,任务比预期完成得更好。
上传文件页面
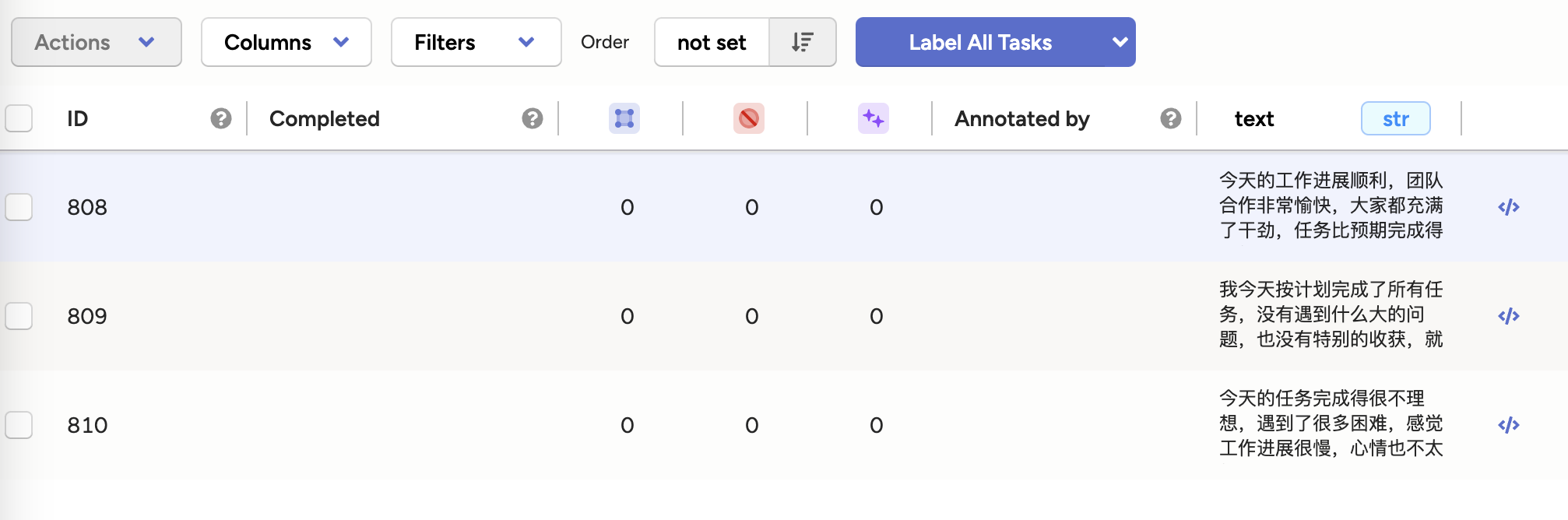
导入标注样本
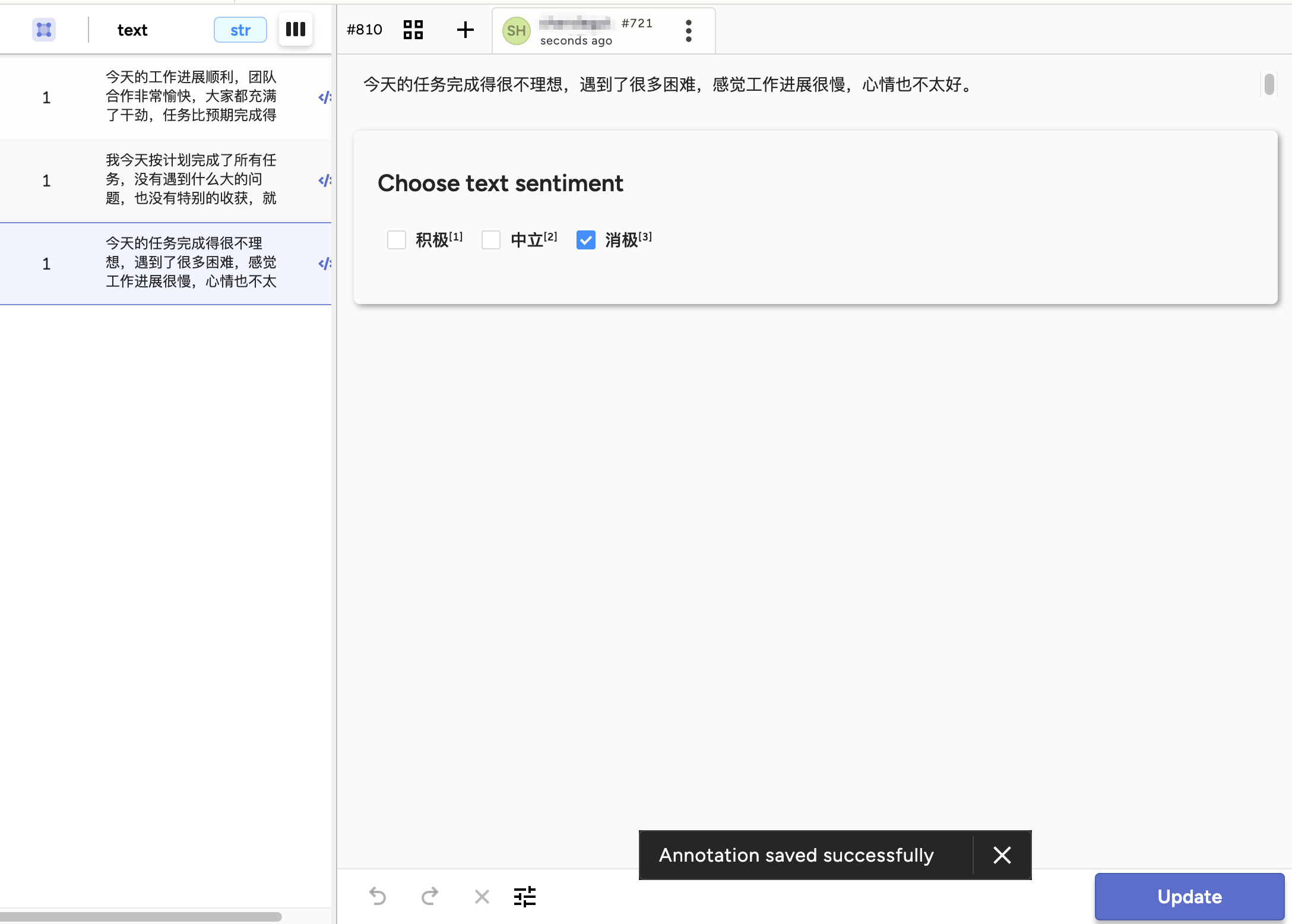
导入标注样本后,在Label Studio界面上进行分类选择,并保存。
cls_6.png
在这个标注平台上,可以多人标注,显示标注进度,标注完任务还可以导出标注数据,使用起来非常便捷。
以第一条标注结果为例,其结果如下(JSON格式):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 { "id" : 808 , "annotations" : [ { "id" : 719 , "completed_by" : 1 , "result" : [ { "value" : { "choices" : [ "积极" ] } , "id" : "FF4IB_vady" , "from_name" : "sentiment" , "to_name" : "text" , "type" : "choices" , "origin" : "manual" } ] , "was_cancelled" : false , "ground_truth" : false , "created_at" : "2024-09-12T14:38:33.519756Z" , "updated_at" : "2024-09-12T14:38:33.519782Z" , "draft_created_at" : null , "lead_time" : 121.935 , "prediction" : { } , "result_count" : 0 , "unique_id" : "1c12f3b0-b6b4-4043-a16c-28f38ce73742" , "import_id" : null , "last_action" : null , "task" : 808 , "project" : 3 , "updated_by" : 1 , "parent_prediction" : null , "parent_annotation" : null , "last_created_by" : null } ] , "file_upload" : "1532c82d-sample.txt" , "drafts" : [ ] , "predictions" : [ ] , "data" : { "text" : "今天的工作进展顺利,团队合作非常愉快,大家都充满了干劲,任务比预期完成得更好。" } , "meta" : { } , "created_at" : "2024-09-12T14:36:10.549023Z" , "updated_at" : "2024-09-12T14:38:33.632261Z" , "inner_id" : 1 , "total_annotations" : 1 , "cancelled_annotations" : 0 , "total_predictions" : 0 , "comment_count" : 0 , "unresolved_comment_count" : 0 , "last_comment_updated_at" : null , "project" : 3 , "updated_by" : 1 , "comment_authors" : [ ] }
接下来的任务,我们会适当地忽略一些细节,大致的标注流程与文本分类任务类似,只关注其中的不同之处。
命名实体识别(NER)
命名实体识别(NER)是自然语言处理(NLP)中的一种关键任务,旨在从文本中识别并分类特定类型的实体。例如,它可以识别人名、地点、组织、日期、时间等信息。NER的目标是将这些实体从普通文本中提取出来,并进行分类标注,如将“苹果”识别为公司或水果,将“北京”识别为地名。NER在信息抽取、问答系统、文本摘要等应用中具有广泛的用途。
我们假设以下的命名实体识别任务:从文本中提取中动物和植物。
创建animal_plant实体标注任务,实体类型为动物和植物,如下:
标注实体的类型
导入样本为:
1 2 3 在森林里,我看见了一只狐狸静静地躺在一片松树下,四周是茂密的蕨类植物,显得十分宁静。
实体标注的界面如下:
标注实体
导出标注任务的最后一个样本数据为(JSON格式):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 { "id" : 813 , "annotations" : [ { "id" : 724 , "completed_by" : 1 , "result" : [ { "value" : { "start" : 6 , "end" : 8 , "text" : "海鸥" , "labels" : [ "动物" ] } , "id" : "hmDYRW2UCg" , "from_name" : "label" , "to_name" : "text" , "type" : "labels" , "origin" : "manual" } , { "value" : { "start" : 22 , "end" : 25 , "text" : "椰子树" , "labels" : [ "植物" ] } , "id" : "HFUmECuzWg" , "from_name" : "label" , "to_name" : "text" , "type" : "labels" , "origin" : "manual" } ] , "was_cancelled" : false , "ground_truth" : false , "created_at" : "2024-09-12T14:59:58.069480Z" , "updated_at" : "2024-09-12T14:59:58.069495Z" , "draft_created_at" : "2024-09-12T14:59:57.958694Z" , "lead_time" : 8.796 , "prediction" : { } , "result_count" : 0 , "unique_id" : "a6bed574-01cf-4c3a-a682-94f0c0e05293" , "import_id" : null , "last_action" : null , "task" : 813 , "project" : 4 , "updated_by" : 1 , "parent_prediction" : null , "parent_annotation" : null , "last_created_by" : null } ] , "file_upload" : "6b429a86-sample2.txt" , "drafts" : [ ] , "predictions" : [ ] , "data" : { "text" : "在海边,几只海鸥在天空中盘旋,而沙滩边长满了椰子树,随着海风轻轻摇摆。" } , "meta" : { } , "created_at" : "2024-09-12T14:57:29.191529Z" , "updated_at" : "2024-09-12T14:59:58.172231Z" , "inner_id" : 3 , "total_annotations" : 1 , "cancelled_annotations" : 0 , "total_predictions" : 0 , "comment_count" : 0 , "unresolved_comment_count" : 0 , "last_comment_updated_at" : null , "project" : 4 , "updated_by" : 1 , "comment_authors" : [ ] }
物体检测
物体检测是计算机视觉(CV)领域的一项重要任务,旨在识别图像或视频中的特定物体,并给出这些物体在图像中的位置(通常以边界框的形式表示)。不同于简单的图像分类,物体检测不仅需要识别物体的类别,还要定位物体的位置。常用的物体检测算法包括YOLO、Faster
R-CNN等,广泛应用于自动驾驶、视频监控、机器人视觉等领域。
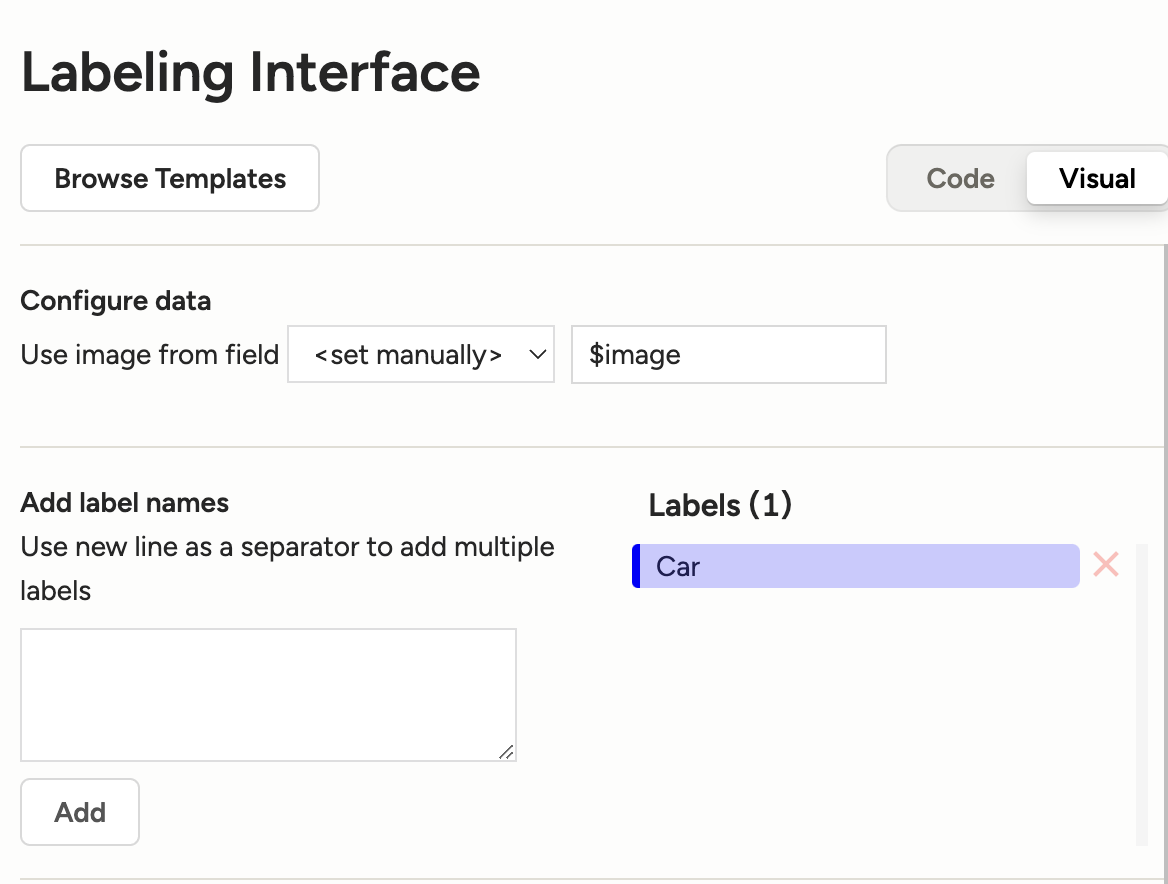
我们假设以下的物体检测任务:从图片中提取中汽车车牌所在的矩形区域,只有一个标签代表汽车车牌。
创建的标签为Car,如下:
标签类型
对导入样本进行标注:
标签标注
导出数据如下(COCO格式,包含在下载压缩文件中的result.json文件中):
images中的数据为:
1 2 3 4 5 6 7 8 9 10 [ , { "width" : 600 , "height" : 350 , "id" : 3 , "file_name" : "images\/653acba4-3.jpg" } , ]
annotations中的数据为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 [ , { "id" : 2 , "image_id" : 2 , "category_id" : 0 , "segmentation" : [ ] , "bbox" : [ 18.87222222222222 , 218.12777777777777 , 57.49444444444444 , 21.50555555555556 ] , "ignore" : 0 , "iscrowd" : 0 , "area" : 1236.4499691358026 } , { "id" : 3 , "image_id" : 2 , "category_id" : 0 , "segmentation" : [ ] , "bbox" : [ 303.7111111111111 , 199.69444444444446 , 89.97222222222213 , 29.844444444444438 ] , "ignore" : 0 , "iscrowd" : 0 , "area" : 2685.1709876543177 } ]
光学字符识别(OCR)
光学字符识别(OCR,Optical Character
Recognition)是一项将图像中的文字内容转换为可编辑文本的技术。它通过分析图像中的字符形状,识别字母、数字及其他符号,进而生成对应的文本数据。OCR通常应用于扫描文档、识别发票、身份证件、手写笔记等内容的数字化处理。常见的OCR系统基于机器学习和深度学习技术,能够识别印刷体、手写体,甚至是多语言字符。其应用广泛,包括文档管理、自动化数据录入、语言翻译等多个领域。
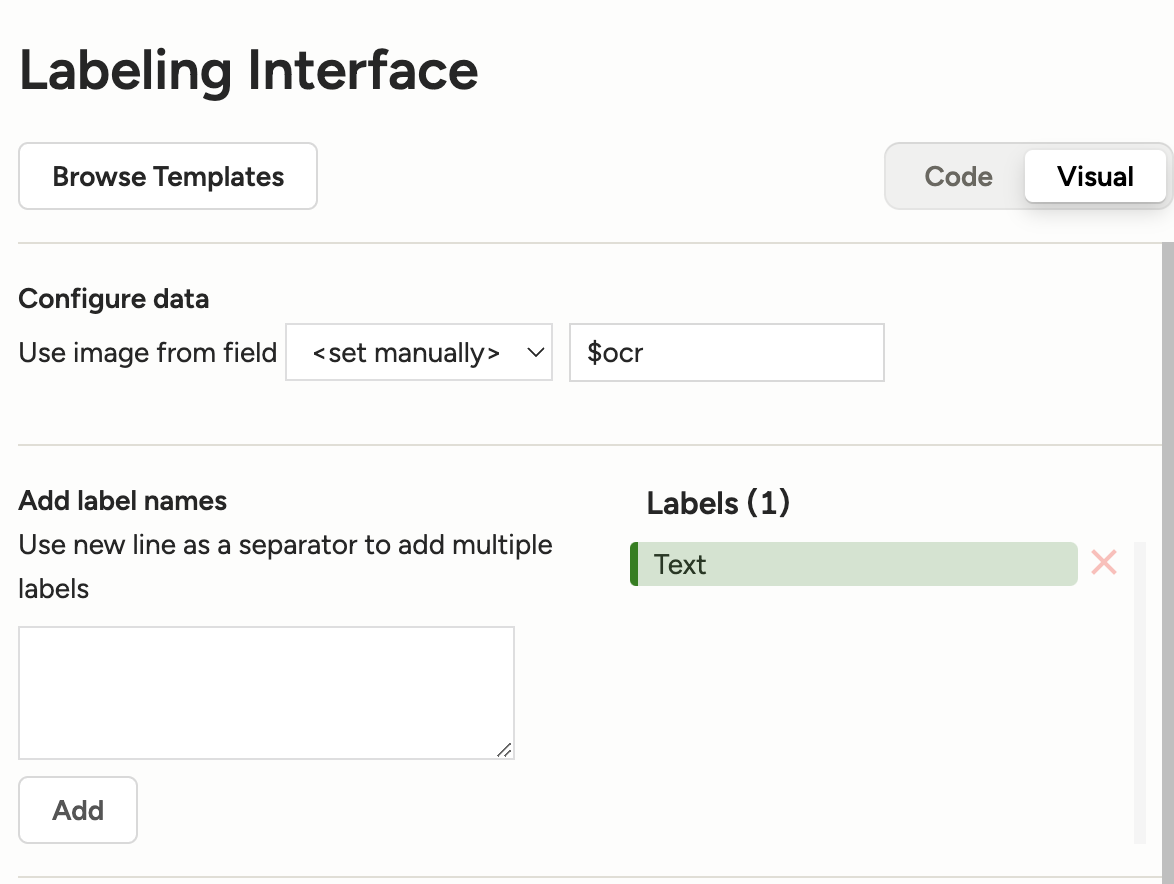
我们假设以下的OCR任务:识别图片中的汽车车牌号码。
创建标签为Text,如下图:
创建标签
标注界面如下:
文本区域及文字标注
总结
本文介绍了开源标注平台Label
Studio,演示了如何进行文本分类、命名实体识别(NER)、物体检测和光学字符识别(OCR)任务的标注。Label
Studio界面友好,支持多种标注任务,并可通过导入数据与多用户协作完成标注,最后支持标注结果导出,极大提高了标注工作的效率。
笔者之前的工作为NLP方向,现在从事大模型训练及应用方向,对CV领域接触不多,后续将会在CV领域尝试更多的模型与探究。