import os import re import json import subprocess from rich.progress import track from openai import OpenAI import logging from retry import retry from random import choices
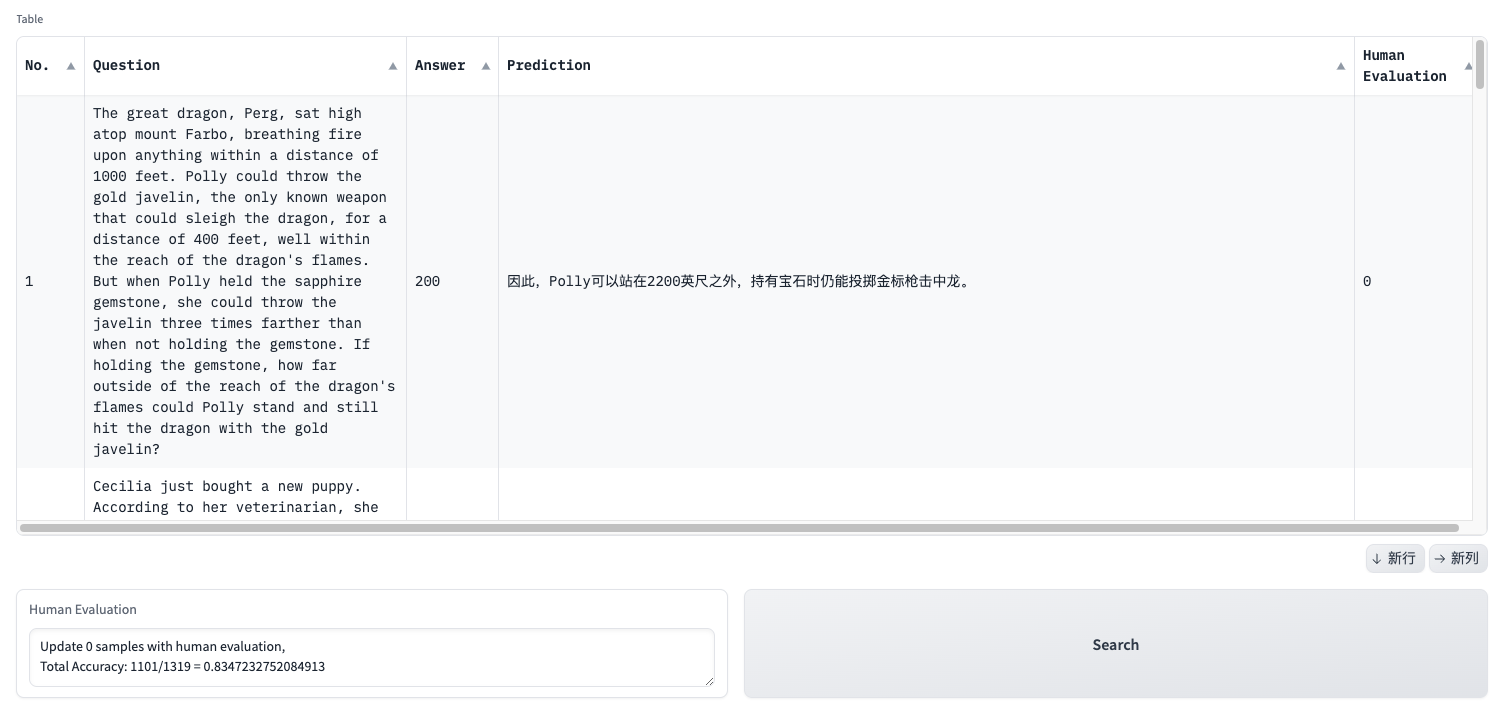
defget_human_eval(df): # get model evaluation withopen("eval_result_yi_15_34b.json", "r") as f: data = f.readlines()
model_true_cnt = 0 for sample in data: sample_dict = json.loads(sample.strip()) if'\\boxed'in sample_dict['pred_answer'] and sample_dict['is_correct']: model_true_cnt += 1 # get human evaluation human_true_cnt = 0 for i, row in df.iterrows(): if row['Human Evaluation']: human_true_cnt += 1 return (f"Update {human_true_cnt} samples with human evaluation, \n" f"Total Accuracy: {model_true_cnt + human_true_cnt}/{len(data)} = {(model_true_cnt + human_true_cnt)/len(data)}")
with gr.Blocks() as demo: with gr.Column(): with gr.Row(): table = gr.DataFrame(label='Table', value=read_samples(), headers=['No.', 'Question', 'Answer', 'Prediction', 'Human Evaluation'], interactive=True, wrap=True) with gr.Row(): output = gr.Textbox(label='Human Evaluation') submit = gr.Button("Search")
import os import re import json import subprocess from rich.progress import track from openai import OpenAI import logging from retry import retry from random import choices
import re def_fix_fracs(string): substrs = string.split("\\frac") new_str = substrs[0] iflen(substrs) > 1: substrs = substrs[1:] for substr in substrs: new_str += "\\frac" if substr[0] == "{": new_str += substr else: try: assertlen(substr) >= 2 except: return string a = substr[0] b = substr[1] if b != "{": iflen(substr) > 2: post_substr = substr[2:] new_str += "{" + a + "}{" + b + "}" + post_substr else: new_str += "{" + a + "}{" + b + "}" else: iflen(substr) > 2: post_substr = substr[2:] new_str += "{" + a + "}" + b + post_substr else: new_str += "{" + a + "}" + b string = new_str return string
def_fix_a_slash_b(string): iflen(string.split("/")) != 2: return string a = string.split("/")[0] b = string.split("/")[1] try: a = int(a) b = int(b) assert string == "{}/{}".format(a, b) new_string = "\\frac{" + str(a) + "}{" + str(b) + "}" return new_string except: return string
def_remove_right_units(string): # "\\text{ " only ever occurs (at least in the val set) when describing units if"\\text{ "in string: splits = string.split("\\text{ ") assertlen(splits) == 2 return splits[0] else: return string
def_fix_sqrt(string): if"\\sqrt"notin string: return string splits = string.split("\\sqrt") new_string = splits[0] for split in splits[1:]: if split[0] != "{": a = split[0] new_substr = "\\sqrt{" + a + "}" + split[1:] else: new_substr = "\\sqrt" + split new_string += new_substr return new_string
# " 0." equivalent to " ." and "{0." equivalent to "{." Alternatively, add "0" if "." is the start of the string string = string.replace(" .", " 0.") string = string.replace("{.", "{0.") # if empty, return empty string iflen(string) == 0: return string if string[0] == ".": string = "0" + string # remove .0, .00, .000 in float number if re.match(r'\d+\.0+$', string): string = string.split('.')[0]
# to consider: get rid of e.g. "k = " or "q = " at beginning iflen(string.split("=")) == 2: iflen(string.split("=")[0]) <= 2: string = string.split("=")[1]
# \frac1b or \frac12 --> \frac{1}{b} and \frac{1}{2}, etc. Even works with \frac1{72} (but not \frac{72}1). Also does a/b --> \\frac{a}{b} string = _fix_fracs(string)
deflast_boxed_only_string(string): idx = string.rfind("\\boxed") if idx < 0: idx = string.rfind("\\fbox") if idx < 0: returnNone
i = idx right_brace_idx = None num_left_braces_open = 0 while i < len(string): if string[i] == "{": num_left_braces_open += 1 if string[i] == "}": num_left_braces_open -= 1 if num_left_braces_open == 0: right_brace_idx = i break i += 1
defget_human_eval(df): # get model evaluation withopen("math_eval_result_update.json", "r") as f: data = f.readlines()
model_true_cnt = 0 for sample in data: sample_dict = json.loads(sample.strip()) if sample_dict["is_correct"]: model_true_cnt += 1 # get human evaluation human_true_cnt = 0 for i, row in df.iterrows(): if row['Human Evaluation']: human_true_cnt += 1 # save human evaluation to json file final_result = [json.loads(line.strip()) for line in data] for i, row in df.iterrows(): if row['Human Evaluation']: final_result[row['No.']]["is_correct"] = True withopen("math_eval_result_final.json", "w") as g: for _ in final_result: g.write(json.dumps(_, ensure_ascii=False) + '\n')
return (f"Update {human_true_cnt} samples with human evaluation, \n" f"Total Accuracy: {model_true_cnt + human_true_cnt}/{len(data)} = {(model_true_cnt + human_true_cnt)/len(data)}")
with gr.Blocks() as demo: with gr.Column(): with gr.Row(): table = gr.DataFrame(label='Table', value=read_samples(), headers=['No.', 'True_Answer_Number', 'Pred_Answer_Number', 'Human Evaluation'], interactive=True, wrap=True ) with gr.Row(): output = gr.Textbox(label='Human Evaluation') submit = gr.Button("Search")
# -*- coding: utf-8 -*- # @file: eval_visualization.py import json import plotly.graph_objects as go from collections import defaultdict from random import shuffle from operator import itemgetter
# 读取数据 withopen("math_eval_result_final.json", "r", encoding="utf-8") as f: data = f.readlines()
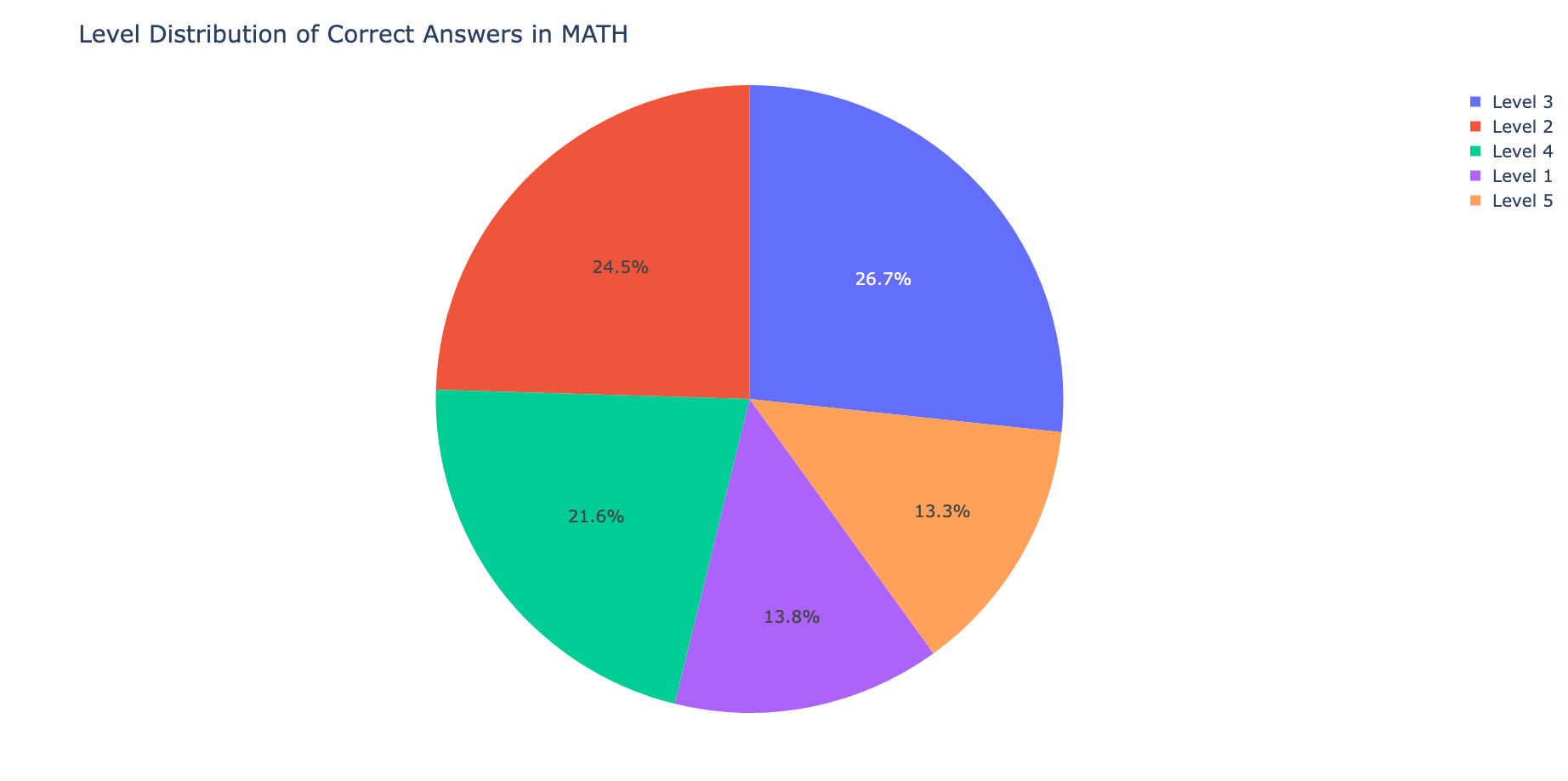
type_dict = defaultdict(int) level_dict = defaultdict(int) for line in data: sample = json.loads(line.strip()) if sample['is_correct']: type_dict[sample['type']] += 1 level_dict[sample['level']] += 1
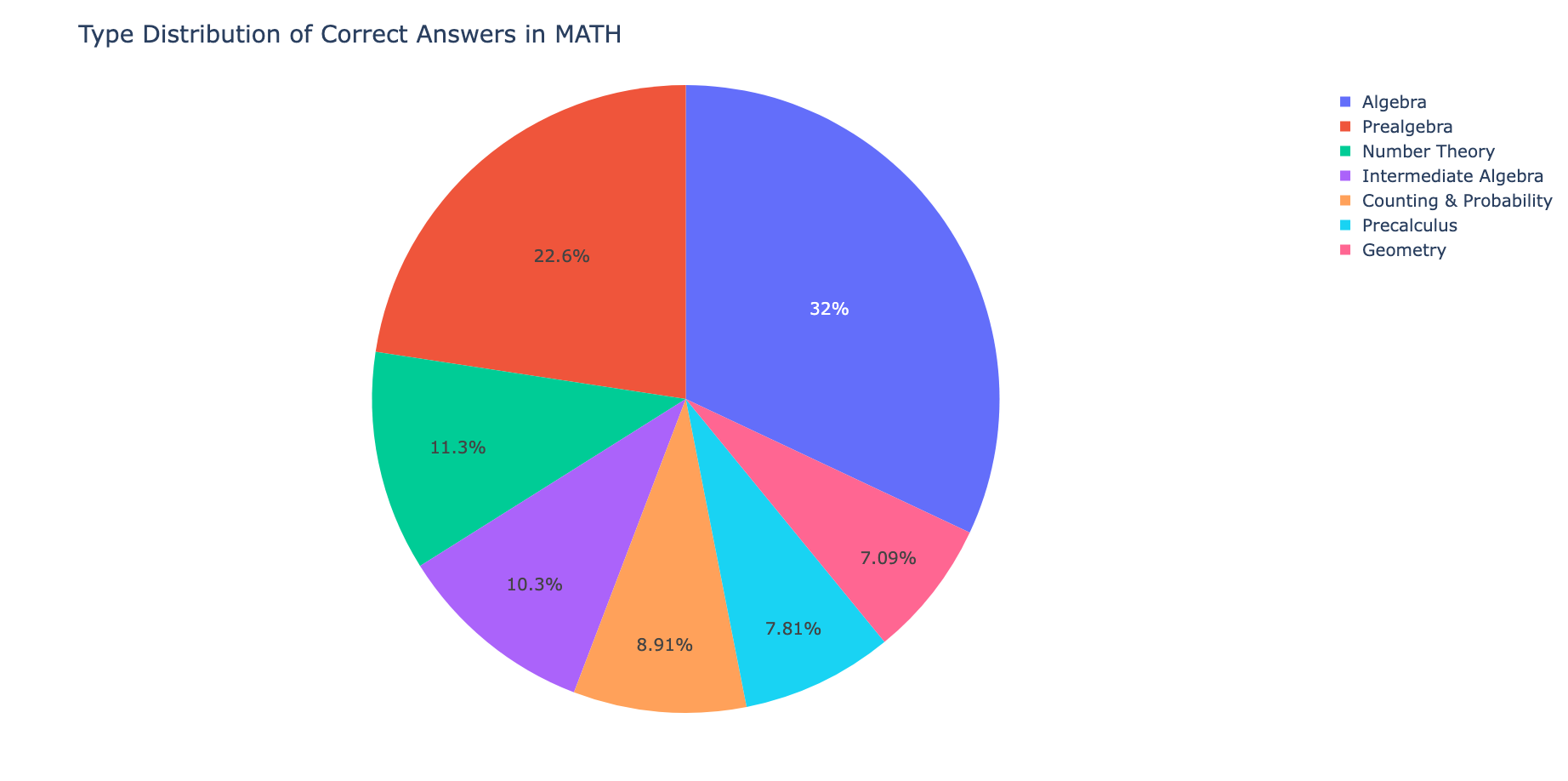
# 绘制类型的饼图 fig1 = go.Figure(data=go.Pie(labels=list(type_dict.keys()), values=list(type_dict.values()))) fig1.update_layout( title="Type Distribution of Correct Answers in MATH", font=dict(size=20) ) # fig1.show() # 绘制Level的饼图 fig2 = go.Figure(data=go.Pie(labels=list(level_dict.keys()), values=list(level_dict.values()))) fig2.update_layout( title="Level Distribution of Correct Answers in MATH", font=dict(size=20) ) # fig2.show()
# 获取每个类型的正确率 type_cnt_dict = defaultdict(int) level_cnt_dict = defaultdict(int) for line in data: sample = json.loads(line.strip()) type_cnt_dict[sample['type'] + '_total'] += 1 level_cnt_dict[sample['level'] + '_total'] += 1 if sample['is_correct']: type_cnt_dict[sample['type'] + '_correct'] += 1 level_cnt_dict[sample['level'] + '_correct'] += 1
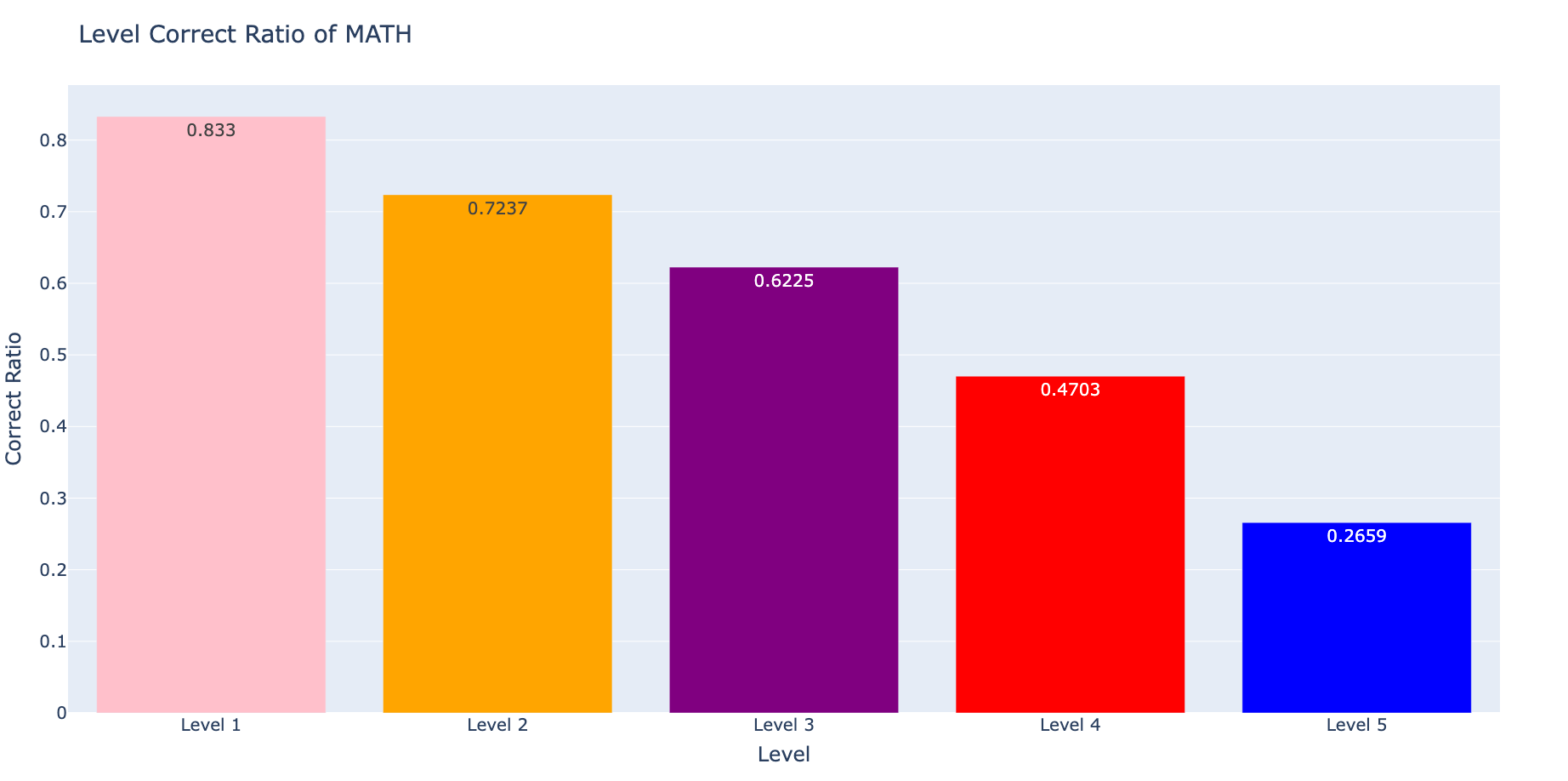
type_correct_ratio = {key: type_cnt_dict[f'{key}_correct']/type_cnt_dict[f'{key}_total'] for key in type_dict.keys()} level_correct_ratio = {key: level_cnt_dict[f'{key}_correct']/level_cnt_dict[f'{key}_total'] for key in level_dict.keys()} sorted_type_correct_ratio = {k: round(v, 4) for k, v insorted(type_correct_ratio.items(), key=itemgetter(1), reverse=True)} sorted_level_correct_ratio = {k: round(v, 4) for k, v insorted(level_correct_ratio.items(), key=itemgetter(1), reverse=True)}