NLP(七十一)大模型微调RACE数据集的进一步实验
在文章NLP(七十)使用LLAMA 2模型微调Multiple Choice MRC 中,笔者介绍了RACE数据集,以及如何使用LLAMA 2模型对该数据集进行微调,较以往的BERT系列模型取得了长足进步。
本文将继续上述实验。
实验
我们的实验使用Firefly大模型训练框架,数据集为RACE
middle数据集,训练参数在NLP(七十)使用LLAMA
2模型微调Multiple Choice MRC 中已经给出。
微调方式采用大模型 + qlora, 对数据集进行SFT(Supervised
Fine-Tuning)。针对不同的模型、模型尺寸、学习率、最大长度等参数进行调试(其余参数不变),实验结果如下:
| 模型 | 学习率 | 训练轮数 | 最大长度 | 准确率 |
|---|---|---|---|---|
| LLAMA-2-7B | 1e-4 | 3 | 384 | 0.8691 |
| LLAMA-2-7B | 1e-4 | 3 | 320 | 0.8593 |
| LLAMA-2-7B | 1e-4 | 5 | 384 | 0.8545 |
| LLAMA-2-7B | 1e-4 | 5 | 320 | 0.8538 |
| LLAMA-2-13B | 1e-4 | 3 | 384 | 0.8844 |
| Baichuan-7B | 2e-4 | 3 | 384 | 0.8357 |
| Baichuan-13B-Chat | 1e-4 | 3 | 384 | 0.8726 |
| Baichuan2-13B-Base | 2e-4 | 3 | 384 | 0.8948 |
| XVERSE-13B | 1e-4 | 3 | 384 | 0.8718 |
在上述实验中,LLAMA-2-13B,
Baichuan-13B-Chat, Baichuan2-13B-Base,
XVERSE-13B模型取得了不错的效果,尤其Baichuan2-13B-Base效果最好,accuracy达到了89.48%。
我们对LLAMA-2-13B + Baichuan2-13B-Base + XVERSE-13B进行模型集成(取预测结果中的次数最大值,如果都相同,则以Baichuan2-13B-Base的结果为准),accuracy为90.25%!
使用全量RACE数据中的训练集进行训练,使用LLAMA-2-13B,学习率1e-4,轮数3,最大长度384,测试结果如下:
| 测试集 | 准确率 |
|---|---|
| middle | 0.9283 |
| high | 0.8413 |
| all | 0.8666 |
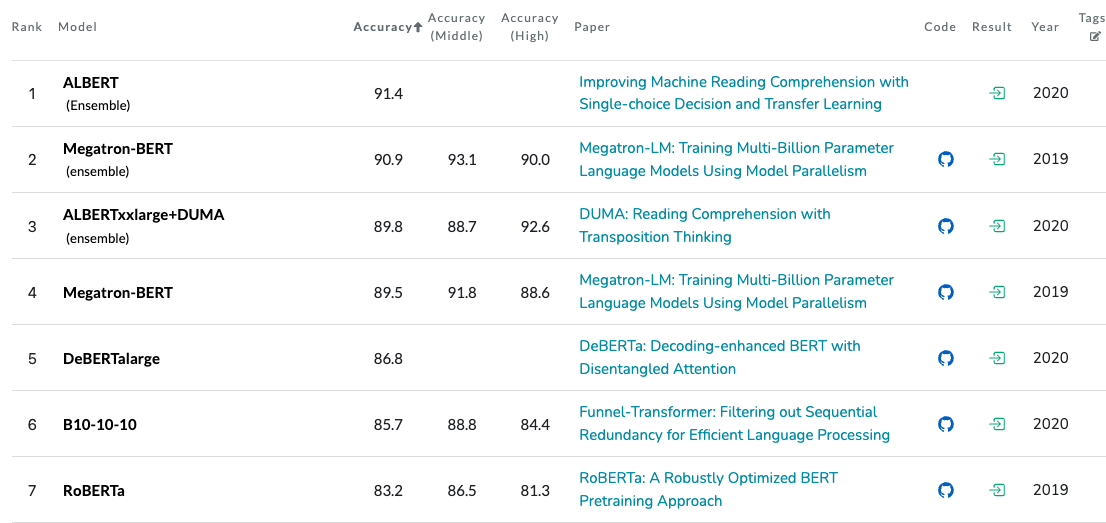
我们再回过头来看看,在以往BERT时代,RACE数据集排行榜:
可视化
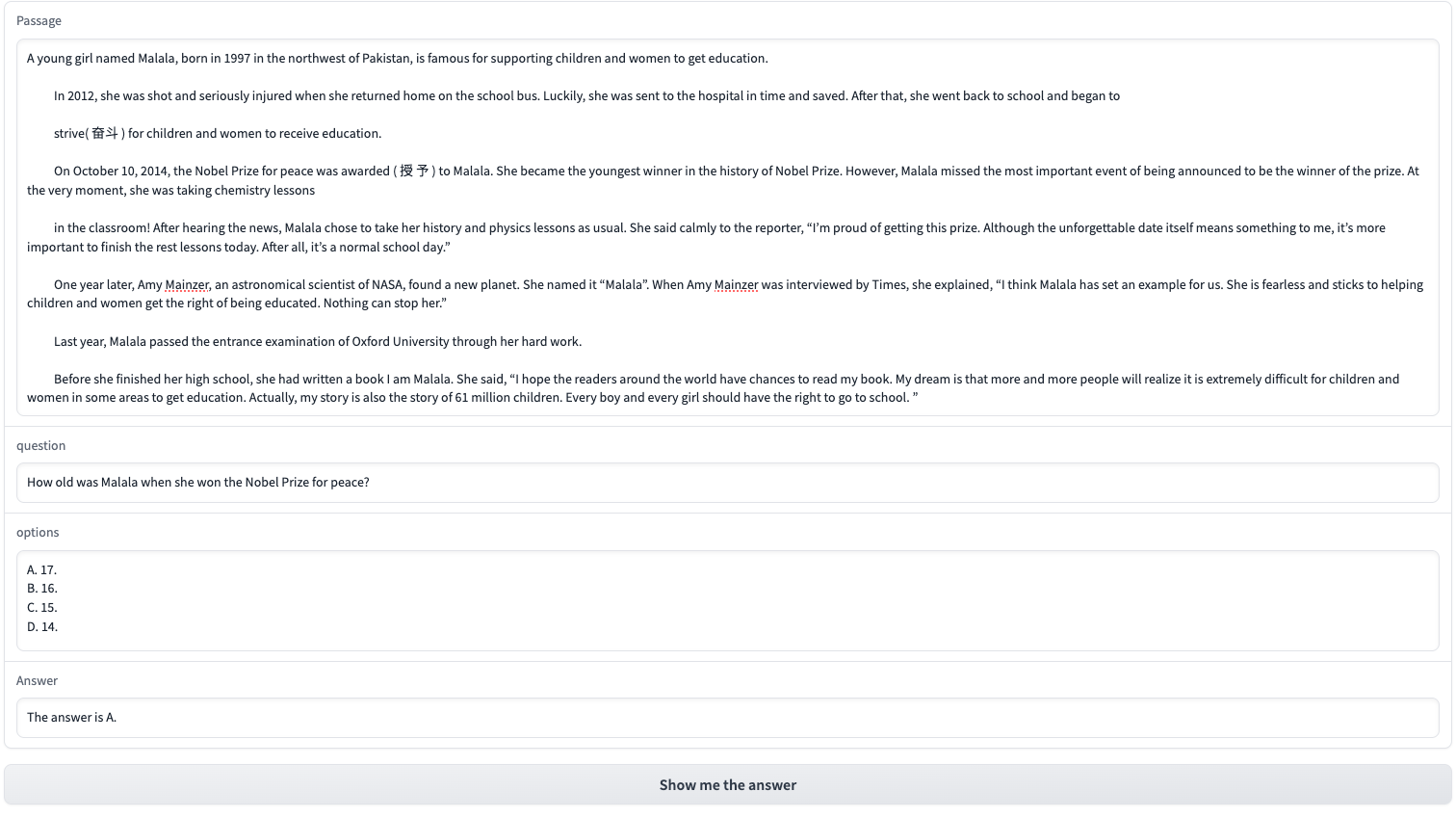
我们使用Gradio模块,对文章、问题、选项进行可视化问答,页面效果:
实现的Python代码可以参考如下:
1 | |
总结
本文并无太多新意,只是在之前文章的基础上进行大量测试,考察不同模型,模型尺寸在SFT上的效果差异,同时也验证了,大模型时代中LLM的强大之处,在效果上几乎横扫以往所有的NLP模型,且将以往的NLP任务做到了统一,这才是LLM的可怕之处!
本文的代码及实验结果已开放至Github,网址为 https://github.com/percent4/llama-2-multiple-choice-mrc .
本人博客网站为 https://percent4.github.io/ ,欢迎大家访问~
推荐阅读
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
