NLP(七十二)使用知识蒸馏提升模型推理性能
本文将会介绍模型压缩方法——知识蒸馏,通过对训练后的BERT模型在小模型上进行蒸馏,在小模型上提到推理性能的极大提升,同时也不会过多损失模型效果。
在深度学习中, 模型压缩是指利用数据集对已经训练好的深度模型进行精简,进而得到一个轻量且准确率相当的网络,压缩后的网络具有更小的结构和更少的参数,可以有效降低计算和存储开销,便于部署在受限的硬件环境中。
在工业界中,常见的模型压缩方法有知识蒸馏(Knowledge Distillation,KD)、剪枝(Pruning)、量化(Quantization)等。
在文章NLP(六十七)BERT模型训练后动态量化(PTDQ) 和 文章NLP(六十八)使用Optimum进行模型量化 中,笔者已经介绍了模型量化相关的内容,本文将会介绍知识蒸馏(KD)。
那么,什么是知识蒸馏呢?
知识蒸馏介绍
首先,我们先简单地了解下知识蒸馏概念。
通常,大模型可能是一个复杂的网络或多个网络的组合,表现出优越的效果和泛化能力。而小模型由于其较小的规模,其表达能力可能受到限制。为了提高小模型的效果,我们可以借助大模型所学习到的知识来指导小模型的训练。这样,小模型在参数数量明显减少的情况下,也能够达到与大模型相似的效果。这种策略就是知识蒸馏在模型压缩中的实践应用。
Geoffrey Hinton及其团队在论文Distilling the Knowledge in a Neural Network中首次提出了“知识蒸馏”的思想,这是知识蒸馏中的开山之作,分量十足。其核心理念是首先训练一个大型复杂的网络,接着利用这个大网络的输出以及数据的真实标签来训练一个更轻量级的网络。在知识蒸馏的结构中,这个大型网络被称为“Teacher”模型,而轻量级网络则被称为“Student”模型。
现阶段,知识蒸馏已经有了长足的发展,方法繁多。常见的知识蒸馏可分为目标蒸馏和特征蒸馏。
- 目标蒸馏:Student模型只学习Teacher模型的Logits结果知识,一般为Soft Logits
- 特征蒸馏:Student模型学习Teacher网络结构中的中间层特征,利用Teacher模型的信息更加充分,训练难度更大
本文主要介绍目标蒸馏,一般的目标蒸馏模型结构如下图所示:
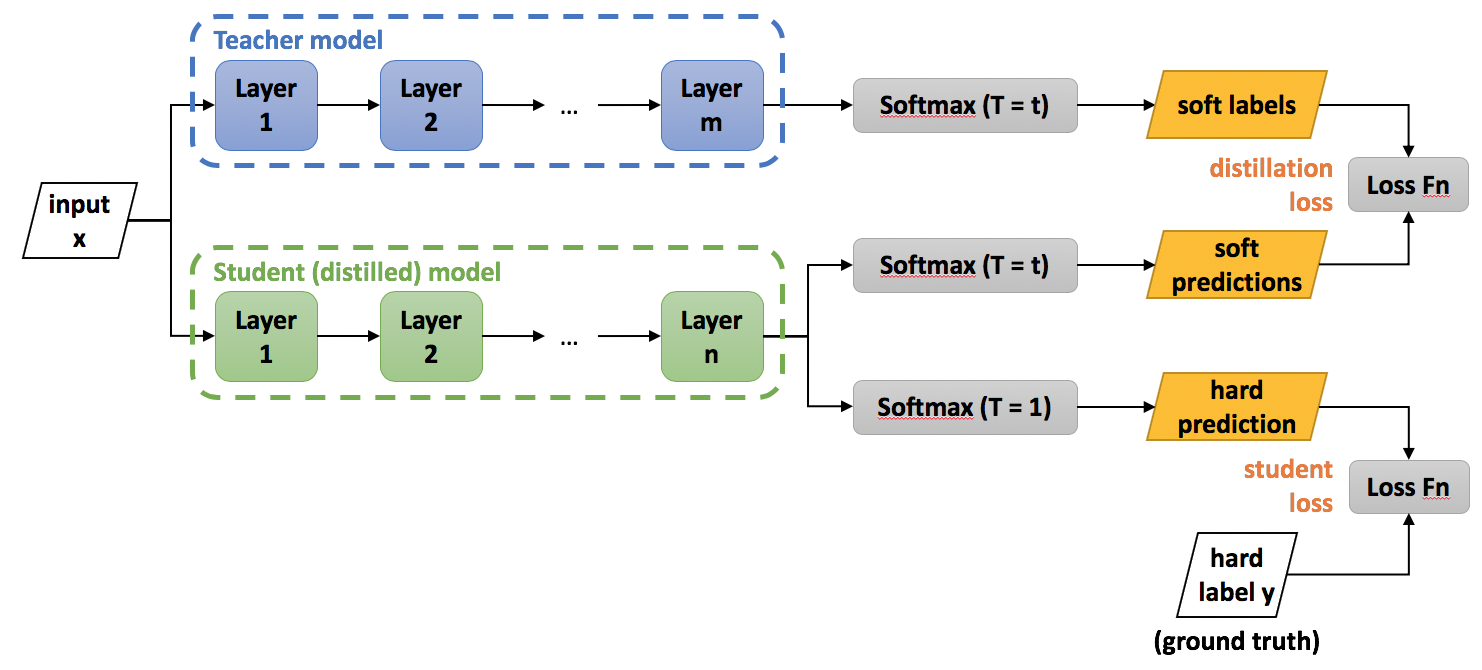
步骤如下:
- 在原有训练数据集中训练好Teacher模型,一般为复杂的(大)模型;
- 借助温度参数(Temperature,T)和Teacher模型的Logits结果,产生Soft Labels;
- 在相同训练集上训练小模型(Student模型),最终loss为两部分loss的权重和:大模型的Soft Labels和小模型的Soft Labels(Predictions)的K-L loss;小模型在数据集上的交叉熵损失
- 使用训练好的小模型做最终的模型推理(Inference)
让我们暂时脱离模型架构,来理解两个重要的概念:Logits和Temperature.
Logits
Logits指的是在分类模型结构中,最后的Softmax函数作用前,在各个标签上的分数z_i,称为Logits。当Softmax函数作用在Logits上,会得到各个标签上的概率值p_i,总和为1。
基于Logits概念,当我们的概率值中只有一个为1,其余为0,则称这些概率值分布为Hard-Target;其它情况为Soft-Target。一般,真实的标签表示方法(通常采用One-Hot表示法)为Hard-Target,只有命中的标签为1,其余标签为0;而模型训练产出的标签结果为Soft-Target,因为不存在概率为1的标签,只有无限接近于1的标签。
通过上述的知识蒸馏模型结构介绍,我们知道,Student模型会利用Teacher模型产生的Soft-Target。那么,Soft-Target有何用处呢?
我们来看个Soft-Target的例子。
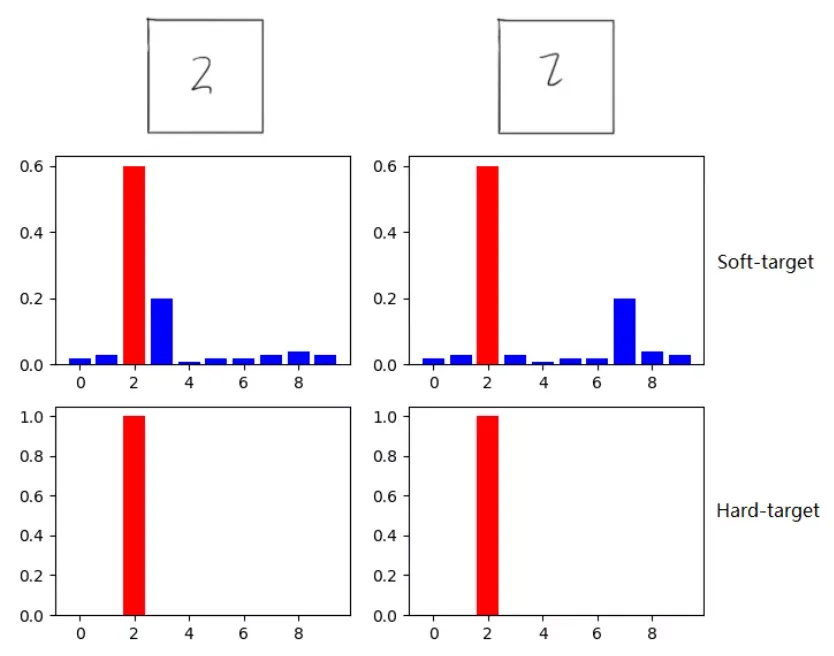
观察上面的两个样本,他们的真实标签均为数字2,因此Hard-Target一致。但我们观察它们的Soft-Target,第一个值的预测结果为2,但在数字3上面的概率值会比其它数字更高,因为从图片中看这个数字2,有点像数字3;同理,第二个值在数字7上的概率比其它数字更高,有点像数字7,这从图片中也能得到反映。
因此,与Hard-Target相比,Soft-Target能够反映样本特征的更多信息,有其合理之处,这就是为什么我们要利用Teacher模型的Soft-Target,它在Hard-Target之外,还能告诉Student模型更多关于样本的特征信息,因此对Student模型有指导意义。
Temperature
那么,Teacher模型的Soft-Target对Student模型有指导意义,还能再加强Soft-Target的作用吗?参数Temperature便应运而生。
对于Softmax函数,我们有如下公式:
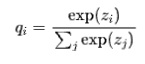
其中,z_i为Logits值,p_i为概率值。我们将温度系数T作用在该公式中,得到:
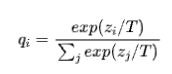
由上述公式,我们可得到:
- 随着T的增大,各个概率值将趋向平滑(当T为无穷大时,概率值相同),其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签
- 随着T的减小,各个概率值将趋向陡峭,分布的熵越小,负标签携带的信息被相对放小,模型训练更少关注负标签
我们来做个小小的实验,以原始Logits分布[-1, 1, 3, 2, 0.5]为例,考察温度T对概率值分布的影响:
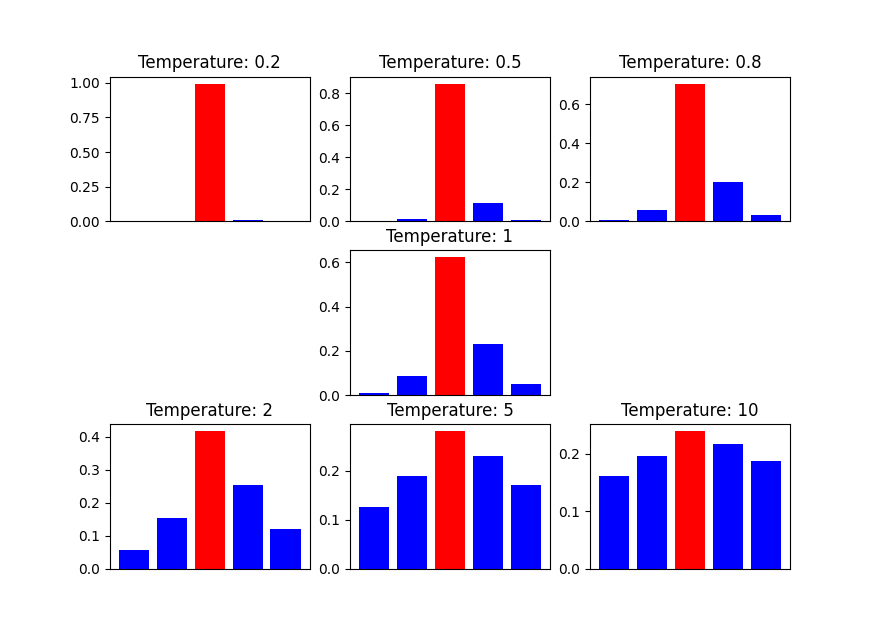
Python实现代码如下:
1 | |
理论介绍
在知识蒸馏介绍章节中,我们已经介绍了知识蒸馏的模型结构图(图1)。同时,还介绍了知识蒸馏的步骤。
- 在原有训练数据集中训练好Teacher模型,一般为复杂的(大)模型;
- 借助温度参数(Temperature,T)和Teacher模型的Logits结果,产生Soft Labels;
- 在相同训练集上训练小模型(Student模型),最终loss为两部分loss的权重和:大模型的Soft Labels和小模型的Soft Labels(Predictions)的K-L loss;小模型在数据集上的交叉熵损失
- 使用训练好的小模型做最终的模型推理(Inference)
第1步为常规的(大)模型训练,第2,3步被称为蒸馏。在2,3步中,最终的输出loss表示如下:
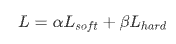
其中,Teacher模型和Student模型的Soft Target如下:
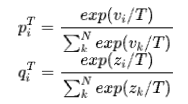
L_soft为Teacher模型和Student模型的Soft Target的KL-Loss, L_hard为Student模型在训练集真实标签上的交叉熵。最终Loss为两部分的权重和。
由于L_soft贡献的梯度大约为L_hard的1/(T2),因此在同时使用Soft-target和Hard-target的时候,需要在L_soft的权重上乘以T2,这样才能保证Soft-target和Hard-target贡献的梯度量基本一致。
实验发现,当L_hard权重较小时,能产生最好的效果,这是一个经验性的结论。
实验代码
在文章PyTorch入门(八)Optuna的使用中,笔者介绍了ckiplab/bert-tiny-chinese模型在Sougou小样本数据集上的分类效果。
在本文中,数据集采用Sougou小样本数据集,Teacher模型采用BERT训练,模型名称为bert_base_sougou_trainer_128/checkpoint-96,Student模型采用ckiplab/bert-tiny-chinese模型。实验过程详细介绍如下:
- 导入模型名称
1 | |
- 验证tokenizer
1 | |
- 加载数据集
1 | |
- 加载tokenizer并对文本进行tokenize
1 | |
- 创造知识蒸馏网络的训练参数和Trainer
1 | |
- 设置训练参数,加载模型
1 | |
- 创造准确率计算指标
1 | |
- Trainer类实例化,进行整理
1 | |
实验结果
在上述的实验代码下,我们分别对单独Student模型训练、蒸馏过程、单独Student模型Optuna参数优化、蒸馏过程Optuna参数优化进行实验,统计在测试集上的Weighted F1值,如下:
| 模型 | Weighted F1 |
|---|---|
| Teacher模型(单独) | 0.9737 |
| Student模型(单独) | 0.9050 |
| 蒸馏 | 0.9050 |
| Student模型(单独,参数优化) | 0.9331 |
| 蒸馏(参数优化) | 0.9454 |
在本地实验中,如果不进行参数优化,则蒸馏的效果不一定会比单独训练Student模型效果来得好;但进行参数优化后,蒸馏效果优于单独训练Student模型,且只比Teacher模型下降了2.8%。
对比蒸馏后的小模型和Teacher模型的平均推理时间,结果如下:
| 基座模型 | 推理时间(ms) | 模型大小 |
|---|---|---|
| bert-base-chinse | 341.5 | ~412MB |
| bert-tiny-chinese(蒸馏后) | 45.55 | ~46MB |
推理速度提升了7.5倍,这比量化策略的提升1.8倍强太多了。
总结
本文篇幅较长,主要介绍了知识蒸馏的基本概念和原理,并通过笔者自己的亲身试验,验证了知识蒸馏的有效性,在稍微降低模型效果的前提下,模型的推理速度获得了极大提升。
本项目已开源至Github,网址为:https://github.com/percent4/dynamic_quantization_on_bert .
推荐阅读
- PyTorch入门(八)Optuna的使用
- NLP(六十七)BERT模型训练后动态量化(PTDQ)
- NLP(六十六)使用HuggingFace中的Trainer进行BERT模型微调
- Task-specific knowledge distillation for BERT using Transformers & Amazon SageMaker

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
