介绍
openai接口已经支持流式调用,再结合Web框架的流式响应功能,不难完成流式输出功能。
但LangChain对openai接口进行了深度包装,流式输出需要进行回调(callback)。LangChain的流式回调类为StreamingStdOutCallbackHandler,此为终端流式输出,不支持接口流式输出。
如果想要对LangChain的回答进行Web端流式输出,网络上有不少人已给出解决方案,大多数方法为继承BaseCallbackHandler类,进行改造:通常方法是借助队列,将新生成的token送入队列,在回复答案(另起一个新的线程)的同时,进行队列元素的获取,从而实现接口流式输出。
参考其中一种解决方案:https://gist.github.com/python273/563177b3ad5b9f74c0f8f3299ec13850
.
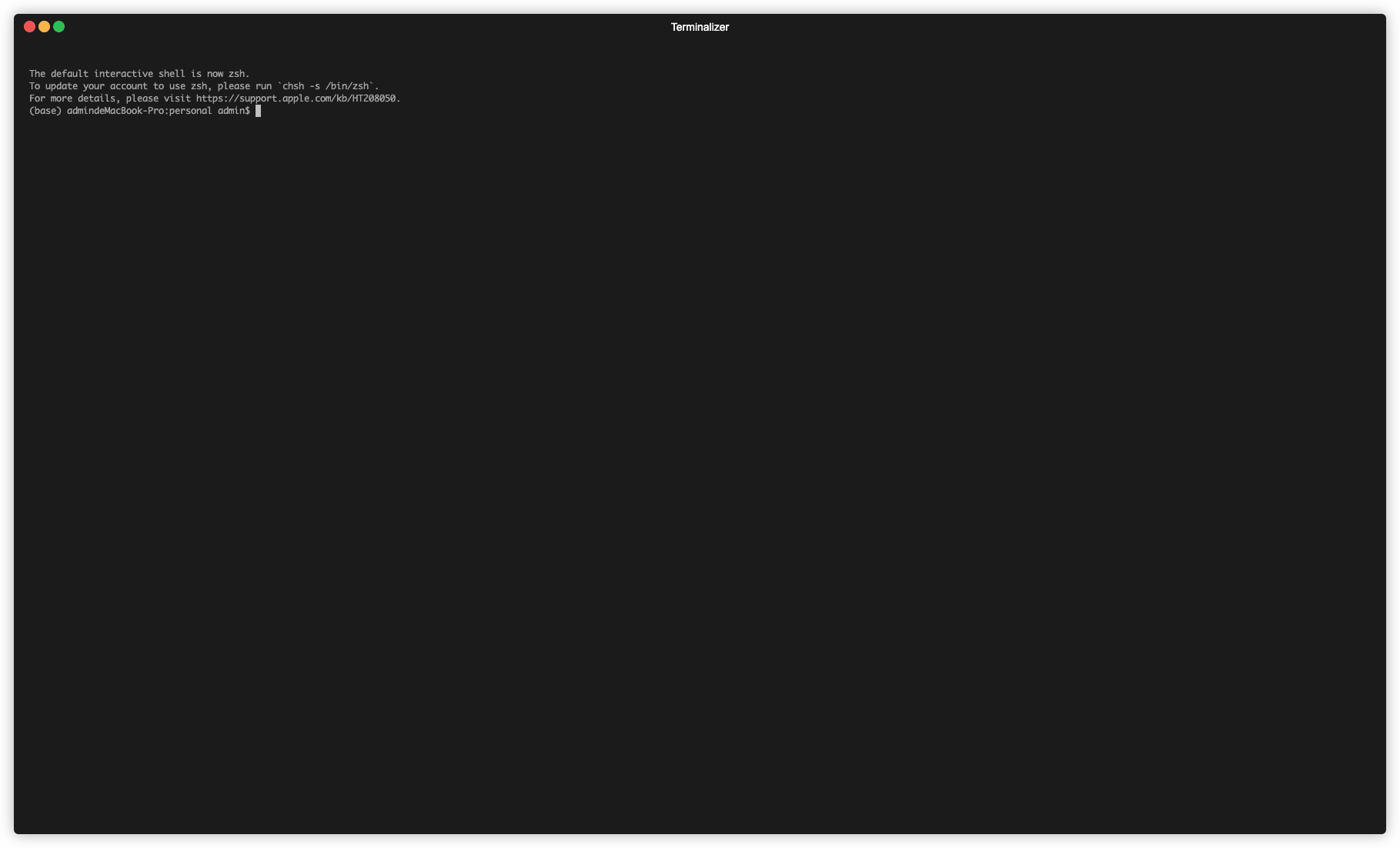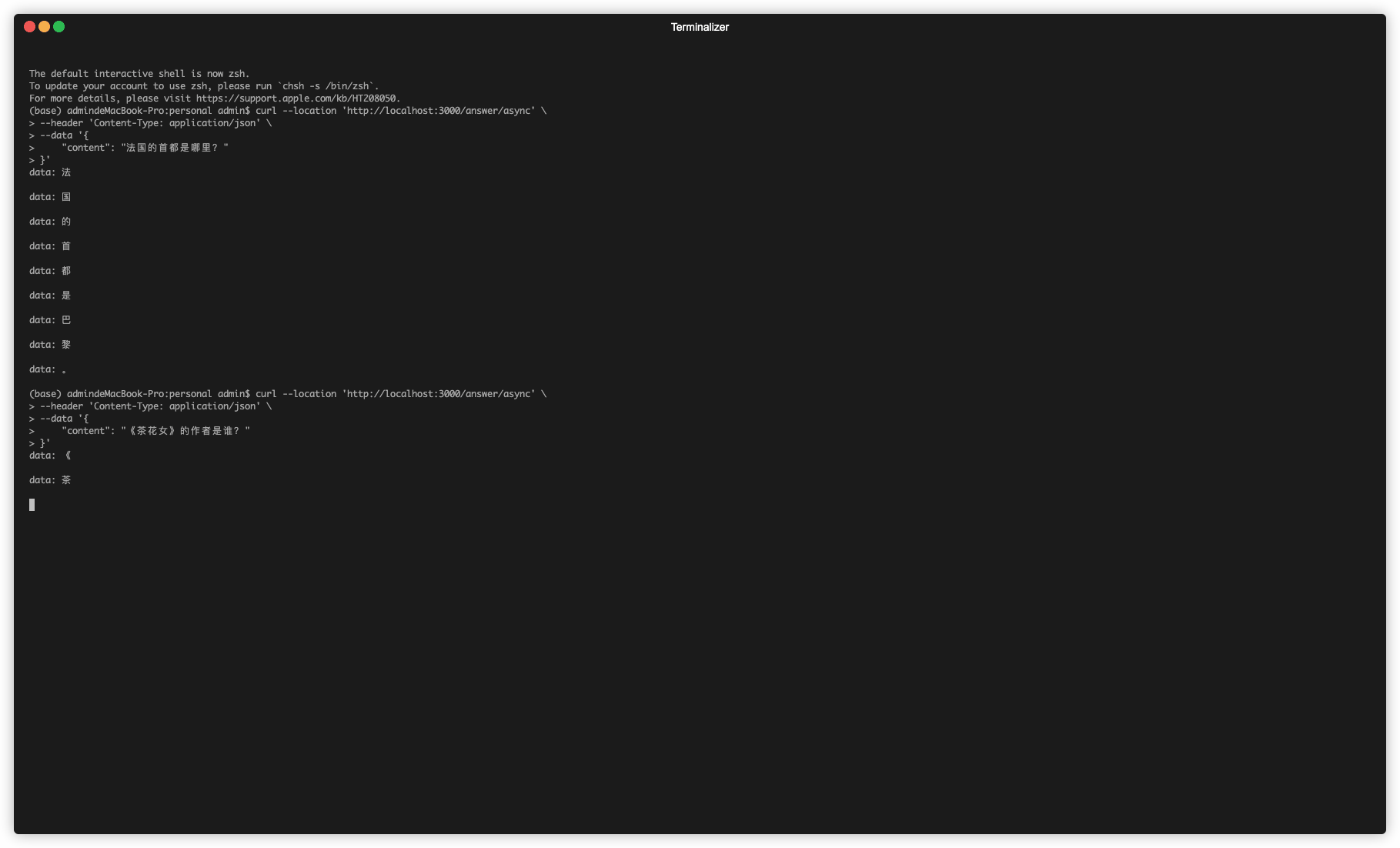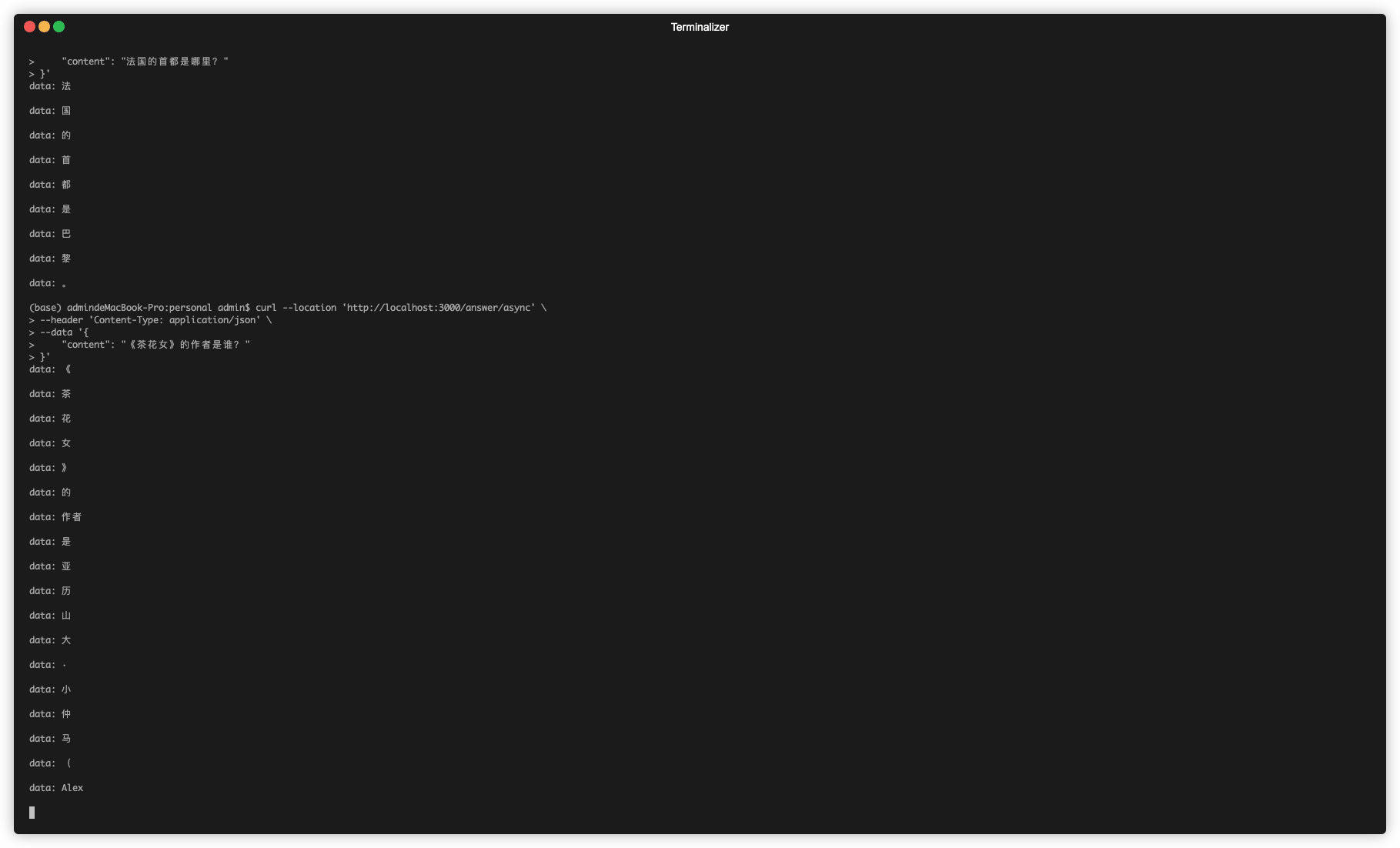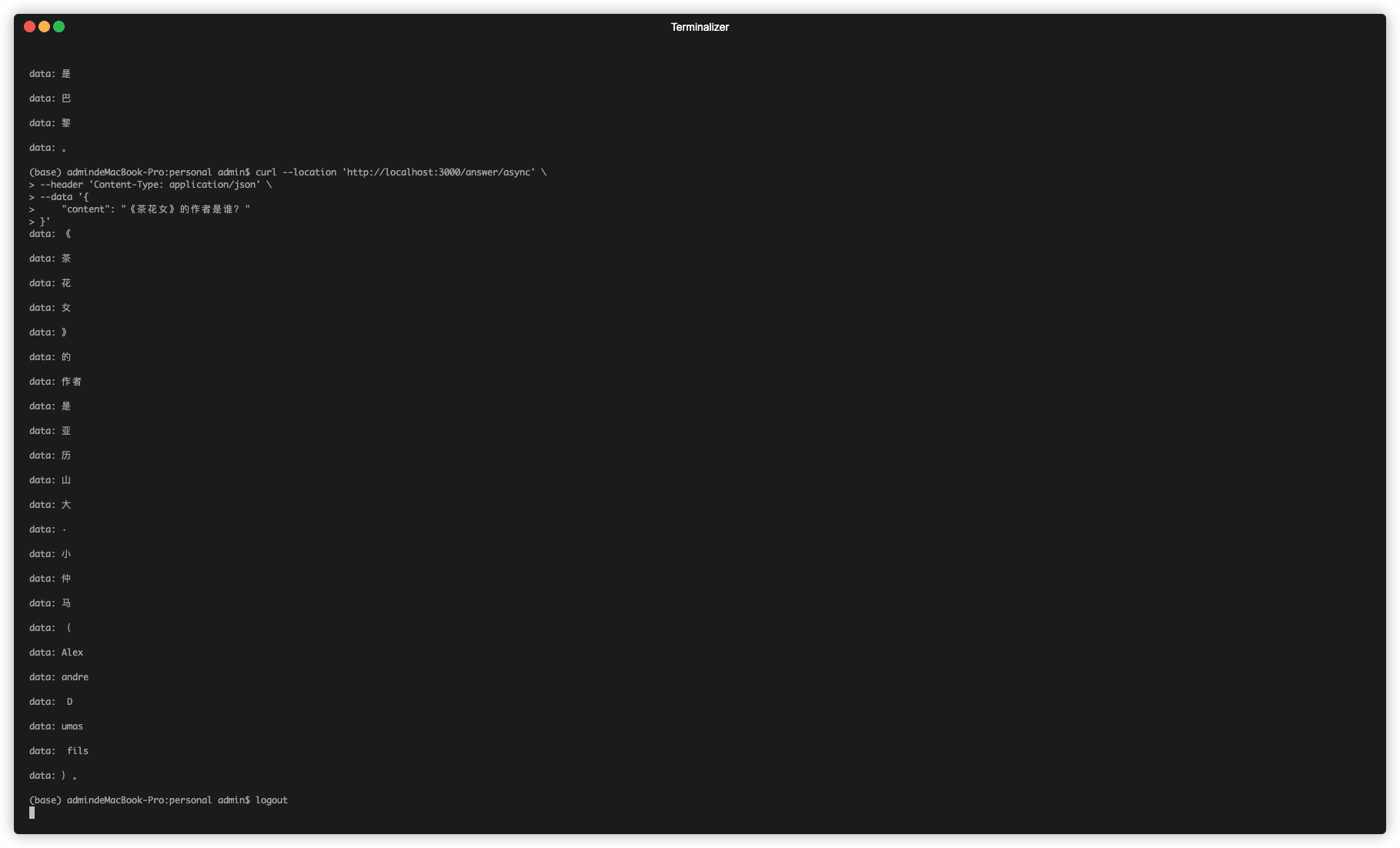
本文的创新之处在于,借助异步Web框架sanic和FastAPI,
和LangChain中的AsyncIteratorCallbackHandler,使用异步方法来实现调用LangChain,实现接口流式输出功能。
Sanic框架框架
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import asynciofrom sanic import Sanicfrom sanic.response import text, json, ResponseStreamfrom langchain.chat_models import ChatOpenAIfrom langchain.schema import HumanMessagefrom langchain.callbacks.streaming_aiter import AsyncIteratorCallbackHandler"benchmark" )@app.route("/" async def index (request ):return text("hello" )@app.route("/test" , methods=["POST" ] async def answer (request ):"content" ]return json({"text" : content})@app.route("/csv" async def test (request ):async def sample_streaming_fn (response ):await response.write("foo," )await response.write("bar" )return ResponseStream(sample_streaming_fn, content_type="text/csv" )@app.route("/answer/async" , methods=["POST" ] async def answer_async (request ):"content" ]async def predict (response ):True ,0 ,"" )async for token in handler.aiter():await response.write(f"data: {token} \n\n" )return ResponseStream(predict, content_type="text/event-stream" )if __name__ == "__main__" :"0.0.0.0" , port=3000 , debug=False , access_log=True )
sanic.gif
FastAPI框架
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import uvicornimport asynciofrom fastapi import FastAPIfrom pydantic import BaseModelfrom fastapi.responses import StreamingResponse, JSONResponsefrom langchain.chat_models import ChatOpenAIfrom langchain.schema import HumanMessagefrom langchain.callbacks.streaming_aiter import AsyncIteratorCallbackHandler"langchain_streaming" )class Item (BaseModel ):str class Question (BaseModel ):str async def fake_video_streamer ():for i in range (10 ):yield b"some fake video bytes\n" @app.get("/" async def main ():return StreamingResponse(fake_video_streamer())@app.post("/test" async def test (item: Item ):return JSONResponse({"content" : item.text})@app.post("/answer/async" async def answer_async (q: Question ):async def predict ():True ,0 ,"sk-xxx" )async for token in handler.aiter():yield f"data: {token} \n\n" return StreamingResponse(predict())if __name__ == "__main__" :"0.0.0.0" , port=8000 , log_level="info" )
欢迎关注我的公众号
NLP奇幻之旅 ,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅 ”,笔者正在努力构建自己的技术社区。