在之前的系列文章中,笔者介绍了如何使用keras-bert来调用BERT模型,实现文本多分类,文本多标签分类以及序列标注任务,文章如下:
在本文中,笔者将介绍如何使用keras-bert来调用BERT模型使用完形填空及简单的文本纠错功能。
完形填空
首先,我们来了解下什么是完形填空。所谓完形填空,指的是将句子中缺失的单词(或字)补充成正确的单词(或字)。举个简单的例子:
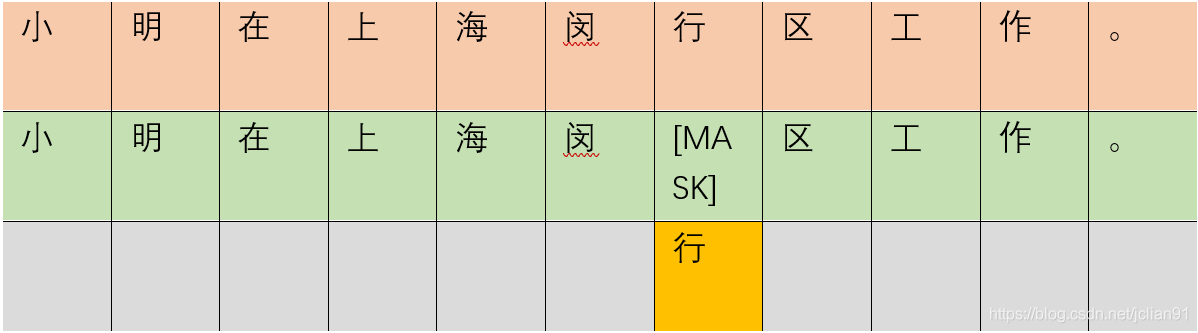 完形填空的例子
完形填空的例子
在上图中,第一行是原始句子,第二行是需要完形填空的句子,在这里我们把闵行区的行字缺失掉,即MASK掉,第三行为补充的汉字:行。
在BERT模型中,它的任务是由两个自监督任务组成,即MLM和NSP。我们需要了解下MLM。
MLM的全称是Masked Language
Model,所谓MLM是指在训练的时候随即从输入预料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。
在BERT的实验中,15%的WordPiece
Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,80%的时候会直接替换为[Mask],10%的时候将其替换为其它任意单词,10%的时候会保留原始Token。
基于BERT模型的这个特性,我们尝试着利用keras-bert来调用它解决完形填空问题。实现完形填空的代码(cloze_predict.py)如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
import numpy as np
from keras_bert import Tokenizer
from keras_bert import load_trained_model_from_checkpoint
dict_path = './chinese_L-12_H-768_A-12/vocab.txt'
token_dict = {}
with open(dict_path, 'r', encoding='utf-8') as reader:
for line in reader:
token = line.strip()
token_dict[token] = len(token_dict)
id_token_dict = {v: k for k, v in token_dict.items()}
class OurTokenizer(Tokenizer):
def _tokenize(self, text):
R = []
for c in text:
if c in self._token_dict:
R.append(c)
else:
R.append('[UNK]')
return R
tokenizer = OurTokenizer(token_dict)
model_path = "./chinese_L-12_H-768_A-12/"
bert_model = load_trained_model_from_checkpoint(
model_path + "bert_config.json",
model_path + "bert_model.ckpt",
training=True
)
def get_mask_character(start_string, mask_num, end_string):
string = list(start_string) + ['MASK'] * mask_num + list(end_string)
token_ids, segment_ids = tokenizer.encode(string, max_len=512)
for i in range(mask_num):
token_ids[len(start_string)+i+1] = tokenizer._token_dict['[MASK]']
masks = [0] * 512
for i in range(mask_num):
masks[len(start_string)+i+1] = 1
predicts = bert_model.predict([np.array([token_ids]), np.array([segment_ids]), np.array([masks])])[0]
pred_indice = predicts[0][len(start_string)+1:len(start_string)+mask_num+1].argmax(axis=1).tolist()
return [id_token_dict[_] for _ in pred_indice]
if __name__ == '__main__':
start_str1 = "白云山,位于"
end_str1 = "广州市白云区,为南粤名山之一,自古就有“羊城第一秀”之称。"
pred_chars = get_mask_character(start_str1, 3, end_str1)
print(pred_chars)
start_str2 = "首先,从"
end_str2 = "看,腾讯和阿里市值已经有2500亿,而百度才500多亿,是BAT体量中最小的一家公司。"
pred_chars = get_mask_character(start_str2, 2, end_str2)
print(pred_chars)
start_str3 = "特斯拉CEO埃隆·马斯克的个人净资产升至1850亿美元,超越亚马逊CEO贝索斯荣登"
end_str3 = "第一大富豪。"
pred_chars = get_mask_character(start_str3, 2, end_str3)
print(pred_chars)
start_str4 = "我在上海闵"
end_str4 = "区工作。"
pred_chars = get_mask_character(start_str4, 1, end_str4)
print(pred_chars)
|
注意keras-bert来调用BERT时,如果需要开启MLM和NSP任务时,需要将training设置为True,然后再调用MLM模型对文本中MASK掉的部分进行预测。运行脚本的输出结果如下:
1
2
3
4
| ['广', '东', '省']
['市', '值']
['全', '球']
['行']
|
简单的文本纠错功能
基于上述的完形填空,我们还可以完成简单的文本纠错功能,前提是我们已经知道文本的哪个字是错误的,并且进行一对一纠错,即把这个字纠正为正确的字,并不会将其去掉或者添加其它字。我们的思路是这样的:在知道文本中的哪个字是错误的之后,将其MASK掉,转化为完形填空任务,从而预测出MASK掉的字作为纠正后的字。
实现简单的文本纠错功能的Python代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
from cloze_predict import get_mask_character
sentence = "我要去埃及金子塔玩。"
sentence = "白云山,位于广东省广州市白云区,为南粤名山之一,自古就有“羊城第一秀”只称。"
sentence = "请把这个快递送到上海市闵航区。"
sentence = "少先队员因该为老人让坐"
sentence = "随然今天很热"
sentence = "我生病了,咳数了好几天"
sentence = "一群罗威纳犬宝宝打架,场面感忍。"
wrong_char_index = sentence.index("忍")
for i in range(len(sentence)):
if i == wrong_char_index:
start_string = sentence[:i]
end_string = sentence[i+1:]
pred_char = get_mask_character(start_string, 1, end_string)
print("wrong char: {}, correct char: {}".format(sentence[i], pred_char[0]))
|
输出结果为:
1
| wrong char: 忍, correct char: 人
|
这种文本纠错方式利用了BERT的MLM模型来实现的,有一定的效果,但不能作为文本纠错的完美实现方式,只是作为文本纠错的一种实现方式,实际上,现实中的文本纠错是由多种模型组成的复杂策略实现的,还得考虑效果和运行效率等因素。另外,真正的文本纠错还应当能指出文本中哪个字错了并对其纠错,本文只考虑了后一步,而没有指出文本中哪个字错了,只能算文本纠错的一次尝试。
总结
本文给出的脚本已上传至Github,网址为:https://github.com/percent4/keras_bert_cloze
,上面有更多的例子,欢迎大家参考~
感谢大家的阅读~
2021.1.24于上海浦东
欢迎关注我的公众号
NLP奇幻之旅,原创技术文章第一时间推送。

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
