NLP(三十四)使用keras-bert实现序列标注任务
对于不同的NLP任务,使用BERT等预训练模型进行微调无疑是使用它们的最佳方式。在网上已经有不少的项目,或者使用TensorFlow,或者使用Keras,或者使用PyTorch对BERT进行微调。本系列文章将致力于应用keras-bert对BERT进行微调,完成基础的NLP任务,比如文本多分类、文本多标签分类以及序列标注等。
keras-bert是Python的第三方模块,它方便我们使用Keras来调用BERT,借助几行代码就可以轻松地完成模型构建,能依据不同的文本任务进行模型训练,获得不错的效果。
本文将介绍如何keras-bert实现序列标注任务。
项目结构
本项目结构如下:
所使用的Python第三方模块如下:
1 | |
代码分析
在util.py脚本中,我们设置了训练集和测试集的路径以及模型参数,代码如下:
1 | |
数据集的格式为BIO标注序列,每个样本用空行隔开,每行为一个字符加标签,example数据集(人民日报实体识别数据集)格式示例如下:
1 | |
load_data.py为数据读取脚本,代码如下:
1 | |
以example.train为例,运行上述脚本,会生成标签文件example_label2id.json,如下:
1 | |
model.py为模型结构脚本,代码如下:
1 | |
模型为BERT+BiLSTM+CRF,其中对BERT进行微调,模型结构(以example数据集为例)如下:
1 | |
数据集介绍
本文将会对三个实体识别的数据集进行测试,以下是三个数据集的简单介绍。
- 人民日报命名实体识别数据集(example.train 28046条数据和example.test 4636条数据),共3种标签:地点(LOC), 人名(PER), 组织机构(ORG)
- 时间识别数据集(time.train 1700条数据和time.test 300条数据),共1种标签:TIME
- CLUENER细粒度实体识别数据集(cluener.train 10748条数据和cluener.test 1343条数据),共10种标签:地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene)
模型训练
模型训练的脚本model_train.py的代码如下:
1 | |
模型使用的预训练模型为BERT中文预训练文件:chinese_L-12_H-768_A-12。
分别对上述三个数据集进行模型训练,结果汇总如下:
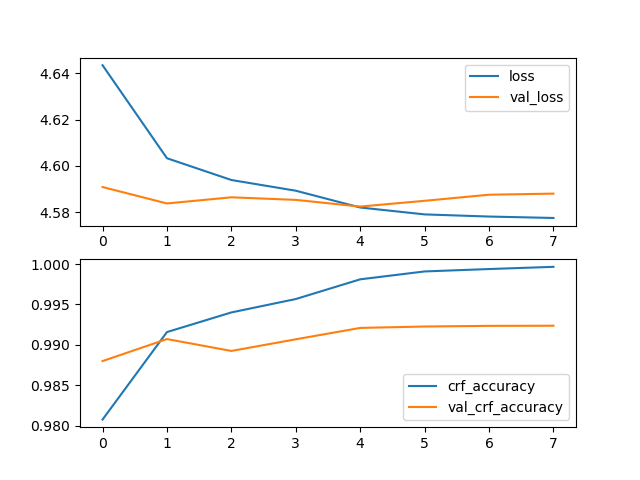
人民日报命名实体识别数据集
模型参数:MAX_SEQ_LEN=128, BATCH_SIZE=32, EPOCH=10
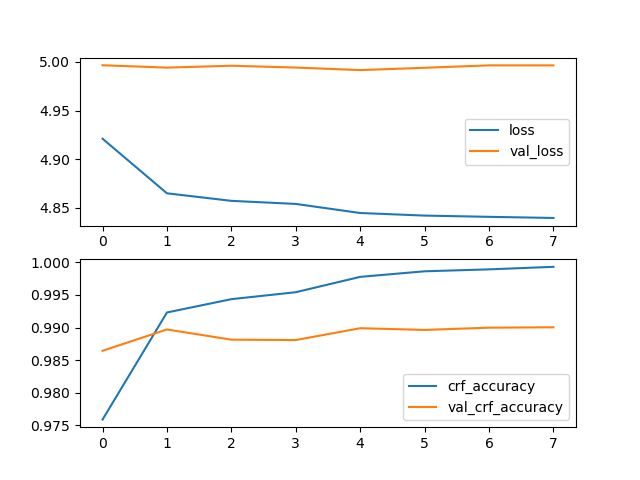
时间识别数据集
模型参数:MAX_SEQ_LEN=256, BATCH_SIZE=8, EPOCH=10
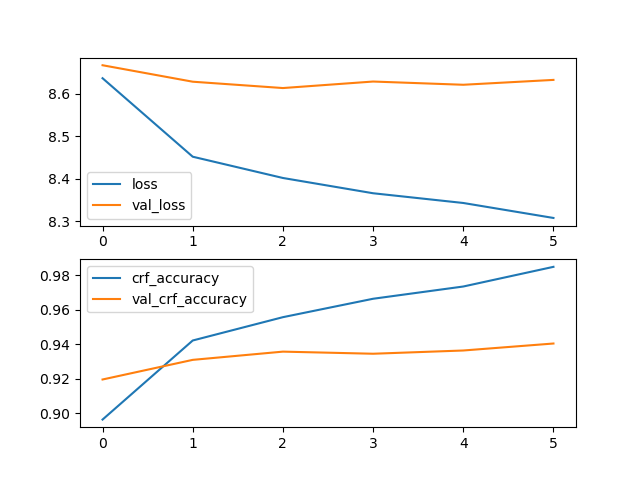
CLUENER细粒度实体识别数据集
模型参数:MAX_SEQ_LEN=128, BATCH_SIZE=32, EPOCH=10
模型评估
模型评估脚本model_evaluate.py脚本的代码如下:
1 | |
分别对上述三个数据集进行模型评估(模型参数同上),结果汇总如下:
- 人民日报命名实体识别数据集
1 | |
- 时间识别数据集
1 | |
- CLUENER细粒度实体识别数据集
1 | |
可以看到,BERT+BiLSTM+CRF(对BERT进行微调)的模型效果是相当不错的,在某种程序上是可以作为baseline的。
模型预测
模型预测脚本model_predict.py的脚本代码如下:
1 | |
在新样本上进行预测,输出的效果也很不错,示例预测结果如下:
- 人民日报命名实体识别数据集
1 | |
1 | |
1 | |
- 时间识别数据集
1 | |
1 | |
1 | |
- CLUENER细粒度实体识别数据集
1 | |
1 | |
1 | |
总结
本项目已经开源,Github地址为:https://github.com/percent4/keras_bert_sequence_labeling 。
后续将会继续介绍如何使用keras-bert实现文本多分类和文本多标签分类,欢迎大家关注~
最后,还想感谢一下所有致力于开源项目的同仁们,感谢你们的努力,感谢你们的付出,感谢你们的铺路。
2020年12月26日于上海浦东
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
