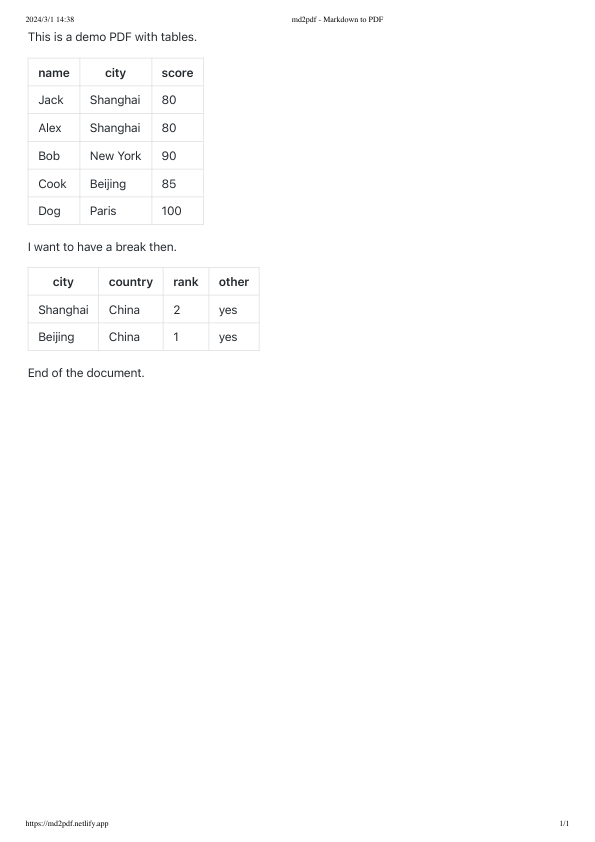
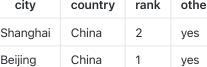
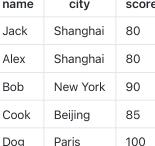
defconvert_pdf_2_img(pdf_file: str, pages: int) -> None: pdf_document = fitz.open(pdf_file) file_name = pdf_file.split('/')[-1].split('.')[0] # Iterate through each page and convert to an image image_list = [] real_pages = min(pages, pdf_document.page_count) for page_number inrange(real_pages): # Get the page page = pdf_document[page_number] # Convert the page to an image pix = page.get_pixmap() # Create a Pillow Image object from the pixmap image = Image.frombytes("RGB", [pix.width, pix.height], pix.samples) # Save the image save_img_path = f"./output/{file_name}_{page_number + 1}.png" image.save(save_img_path) image_list.append(save_img_path)
# Close the PDF file pdf_document.close() return image_list
deftable_detect(image_path): image = Image.open(image_path).convert('RGB') file_name = image_path.split('/')[-1].split('.')[0] inputs = image_processor(images=image, return_tensors="pt") outputs = detect_model(**inputs) # convert outputs (bounding boxes and class logits) to COCO API target_sizes = torch.tensor([image.size[::-1]]) results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[0]
i = 0 output_images = [] for score, label, box inzip(results["scores"], results["labels"], results["boxes"]): box = [round(i, 2) for i in box.tolist()] print( f"Detected {detect_model.config.id2label[label.item()]} with confidence " f"{round(score.item(), 3)} at location {box}" )
region = image.crop(box) # 检测 output_image_path = f'./output/{file_name}_table_{i}.jpg' region.save(output_image_path) output_images.append(output_image_path) i += 1 return output_images
if __name__ == '__main__': test_pdf_file = "./pdf/demo2.pdf" page_image_list = convert_pdf_2_img(pdf_file=test_pdf_file, pages=2) for page_image in page_image_list: table_detect(page_image)
# Full Text of PDF for page_index inrange(num_pages): page = doc.load_page(page_index) text = page.get_text() bg_content_list.append(text)
return''.join(bg_content_list)
# Function to encode the image defencode_image(image_path: str): withopen(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode('utf-8')
payload = {"model": "gpt-4-vision-preview", "messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": f"The full text of PDF file is: {pdf_content}"}, {"role": "user", "content": image_content}], "max_tokens": 300}