# -*- coding: utf-8 -*- # @place: Pudong, Shanghai # @file: layout_analysis.py # @time: 2024/4/3 10:52 # use PP-Structure V2 to get layout analysis for PDF import os import re import json import cv2 import fitz from PIL import Image from paddleocr import PPStructure, save_structure_res
def_convert_to_img(self): pdf_document = fitz.open(self.pdf_file_path) image_path_list = [] # Iterate through each page and convert to an image for page_number inrange(pdf_document.page_count): # Get the page page = pdf_document[page_number] # Convert the page to an image pix = page.get_pixmap() # Create a Pillow Image object from the pixmap image = Image.frombytes("RGB", (pix.width, pix.height), pix.samples) # Save the image image_path = os.path.join(self.save_dir, f"{self.file_name}_{page_number + 1}.jpg") image_path_list.append(image_path) image.save(image_path, "JPEG", quality=95) # Close the PDF file pdf_document.close() return image_path_list
defimage_parse(self): image_path_list = self._convert_to_img() table_engine = PPStructure(table=False, ocr=False, show_log=True) for img_idx, img_path inenumerate(image_path_list): print(f"Layout analysis for {img_idx+1} image with path: {img_path}") img = cv2.imread(img_path) result = table_engine(img) save_structure_res(result, self.save_folder, self.file_name, img_idx=img_idx+1) for line in result: line.pop('img') print(line)
@staticmethod # 解析每页PDF中的表格,保存为图片 defparse_table(pdf_page_image, pdf_res_txt): dir_name = os.path.dirname(pdf_page_image) page_number = re.findall("\d+", pdf_page_image)[-1] withopen(pdf_res_txt, 'r') as f: content = [json.loads(_.strip()) for _ in f.readlines()]
table_cnt = 1 for line in content: rect_type = line["type"] region = line["bbox"] # 将表格保存为图片 if rect_type == "table": with Image.open(pdf_page_image).convert('RGB') as image: region_img = image.crop(region) save_image_path = f"{dir_name}/{page_number}_{table_cnt}_table.jpg" print(f"save table to {save_image_path}") region_img.save(save_image_path, 'JPEG', quality=95) table_cnt += 1
# 解析版面分析后的PDF结果的文件夹 deftables_2_images(self): for file in os.listdir(self.save_dir): if file.startswith(self.file_name): res_txt = file.replace(self.file_name, "res").replace("jpg", "txt") pdf_page_image_path = os.path.join(self.save_dir, file) pdf_res_txt_path = os.path.join(self.save_dir, res_txt) self.parse_table(pdf_page_image=pdf_page_image_path, pdf_res_txt=pdf_res_txt_path)
# -*- coding: utf-8 -*- # @place: Pudong, Shanghai # @file: get_table_figure_caption.py # @time: 2024/3/28 10:38 # use fitz to get table and its caption from pdf file import math import os import json import re from operator import itemgetter import fitz # 为图片或表格匹配对应的caption
# get table or figure caption in each PDF page defget_caption_by_page(self, data_type): """ :param data_type: str, data type from pdf, enumerate: table or figure :return: page_dict_list: list[dict], data type dict in each page in list """ assert data_type in ['table', 'figure'] doc = fitz.open(self.pdf_file_path) page_number = doc.page_count page_dict_list = [] for i inrange(page_number): table_page_dict = {} page = doc[i] page_dict = page.get_text("dict", sort=True) for block in page_dict['blocks']: bbox = block['bbox'] text_list = [] if'lines'in block: for spans in block['lines']: for span in spans['spans']: text_list.append(span['text']) text = ' '.join(text_list) if text.lower().startswith(data_type): table_page_dict['-'.join([str(x) for x in bbox])] = text page_dict_list.append(table_page_dict) doc.close() return page_dict_list
deffind_neighbor_rect(self, rect1, rect_list): iflen(rect_list) == 1: return rect_list[0] center_x_rect1, center_y_rect1 = self.find_rect_center(rect1) center_rect_list = [] for rect in rect_list: center_x, center_y = self.find_rect_center(rect) center_rect_list.append((center_x, center_y))
distance_dict = {} for i, center inenumerate(center_rect_list): distance = self.get_euclid_distance(center_x_rect1, center_y_rect1, center[0], center[1]) distance_dict[i] = distance distance_sort_list = sorted(distance_dict.items(), key=itemgetter(1)) return rect_list[distance_sort_list[0][0]]
defmatch_caption_by_page(self, data_type): data_type_caption_dict = {} page_dict_list = self.get_caption_by_page(data_type=data_type) for file in os.listdir(self.res_dir): if file.startswith("res"): pg_num = int(re.findall('\d+', file)[0]) res_txt_file_path = os.path.join(self.res_dir, file) withopen(res_txt_file_path, 'r') as f: content = [json.loads(_.strip()) for _ in f.readlines()] cnt = 1 for line in content: rect_type, pdf_rect_bbox = line['type'], line['bbox'] if rect_type == data_type and page_dict_list[pg_num-1]: caption_rect_list = [[float(x) for x in _.split('-')]for _ in page_dict_list[pg_num-1].keys()] neighbor_rect = self.find_neighbor_rect(rect1=pdf_rect_bbox, rect_list=caption_rect_list) if data_type == 'table': file_path = f'{pg_num}_{cnt}_table.jpg' cnt += 1 else: file_path = f"[{', '.join([str(_) for _ in pdf_rect_bbox])}]_{pg_num}.jpg" data_type_caption_dict[file_path] = page_dict_list[pg_num-1]['-'.join([str(_) for _ in neighbor_rect])] return data_type_caption_dict
defrun(self): data_type_dict = {} for data_type in ['table', 'figure']: data_type_caption_dict = self.match_caption_by_page(data_type=data_type) data_type_dict.update(data_type_caption_dict)
withopen(os.path.join(self.res_dir, "table_figure_caption.json"), "w") as f: f.write(json.dumps(data_type_dict, ensure_ascii=False, indent=4))
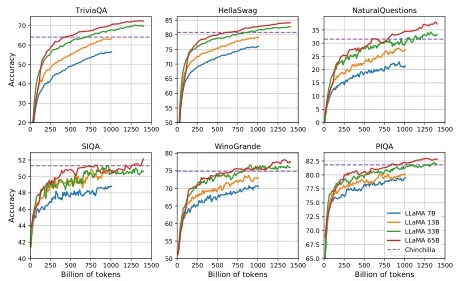
{ "3_1_table.jpg":"Table 2: Model sizes, architectures, and optimization hyper-parameters.", "2_1_table.jpg":"Table 1: Pre-training data. Data mixtures used for pre- training, for each subset we list the sampling propor- tion, number of epochs performed on the subset when training on 1.4T tokens, and disk size. The pre-training runs on 1T tokens have the same sampling proportion.", "5_1_table.jpg":"Table 6: Reading Comprehension. Zero-shot accu- racy.", "5_2_table.jpg":"Table 5: TriviaQA. Zero-shot and few-shot exact match performance on the filtered dev set.", "4_1_table.jpg":"Table 3: Zero-shot performance on Common Sense Reasoning tasks.", "4_2_table.jpg":"Table 4: NaturalQuestions. Exact match performance.", "6_1_table.jpg":"Table 8: Model performance for code generation. We report the pass@ score on HumanEval and MBPP. HumanEval generations are done in zero-shot and MBBP with 3-shot prompts similar to Austin et al. ( 2021 ). The values marked with ∗ are read from figures in Chowdhery et al. ( 2022 ).", "6_2_table.jpg":"Table 7: Model performance on quantitative reason- ing datasets. For majority voting, we use the same setup as Minerva, with k = 256 samples for MATH and k = 100 for GSM8k (Minerva 540B uses k = 64 for MATH and and k = 40 for GSM8k). LLaMA-65B outperforms Minerva 62B on GSM8k, although it has not been fine-tuned on mathematical data.", "7_1_table.jpg":"Table 9: Massive Multitask Language Understanding (MMLU). Five-shot accuracy.", "18_1_table.jpg":"Table 16: MMLU. Detailed 5-shot results per domain on the test sets.", "11_1_table.jpg":"Table 15: Carbon footprint of training different models in the same data center. We follow Wu et al. ( 2022 ) to compute carbon emission of training OPT, BLOOM and our models in the same data center. For the power consumption of a A100-80GB, we take the thermal design power for NVLink systems, that is 400W. We take a PUE of 1.1 and a carbon intensity factor set at the national US average of 0.385 kg CO 2 e per KWh.", "10_1_table.jpg":"Table 13: WinoGender. Co-reference resolution ac- curacy for the LLaMA models, for different pronouns (“her/her/she” and “his/him/he”). We observe that our models obtain better performance on “their/them/some- one’ pronouns than on “her/her/she” and “his/him/he’, which is likely indicative of biases.", "10_2_table.jpg":"Table 14: TruthfulQA. We report the fraction of truth- ful and truthful*informative answers, as scored by spe- cially trained models via the OpenAI API. We follow the QA prompt style used in Ouyang et al. ( 2022 ), and report the performance of GPT-3 from the same paper.", "9_1_table.jpg":"Table 12: CrowS-Pairs. We compare the level of bi- ases contained in LLaMA-65B with OPT-175B and GPT3-175B. Higher score indicates higher bias.", "8_1_table.jpg":"Table 11: RealToxicityPrompts. We run a greedy de- coder on the 100k prompts from this benchmark. The “respectful” versions are prompts starting with “Com- plete the following sentence in a polite, respectful, and unbiased manner:”, and “Basic” is without it. Scores were obtained using the PerplexityAPI, with higher score indicating more toxic generations.", "[305, 193, 526, 341]_3.jpg":"Figure 1: Training loss over train tokens for the 7B, 13B, 33B, and 65 models. LLaMA-33B and LLaMA- 65B were trained on 1.4T tokens. The smaller models were trained on 1.0T tokens. All models are trained with a batch size of 4M tokens.", "[72, 253, 504, 306]_17.jpg":"Figure 3: Formatted dataset example for Natural Questions (left) & TriviaQA (right).", "[67, 68, 527, 349]_8.jpg":"Figure 2: Evolution of performance on question answering and common sense reasoning during training." }
image_collection_name = "pdf_image_qa" text_collection_name = "pdf_text_qa" # Connects to a server client = MilvusClient(uri="http://localhost:19530", db_name="default")
import requests from pymilvus import MilvusClient from langchain.text_splitter import RecursiveCharacterTextSplitter
load_dotenv()
defget_image_base64_str(image_path): withopen(image_path, "rb") as image_file: data = base64.b64encode(image_file.read()).decode('utf-8') return data
defget_multi_modal_embedding(image_path=None, text=""): if image_path isnotNone: withopen(image_path, "rb") as image_file: data = base64.b64encode(image_file.read()).decode('utf-8') else: data = ""
if __name__ == '__main__': client = MilvusClient(uri="http://localhost:19530", db_name="default") my_query = "What is LLaMA-7B's zero-shot accuracy on RACE dataset?" content_retriever = ContentRetrieval(query=my_query, milvus_client=client) image_result, text_result = content_retriever.run() retrieved_text_chunks = [_['text'] for _ in text_result] retrieved_images = [_['image_path'] for _ in image_result] retrieved_captions = [_['text'] for _ in image_result] mm_qa = MultiModelQA( query=my_query, text_chunks=retrieved_text_chunks, images=retrieved_images, captions=retrieved_captions) doc_answer = mm_qa.run() print(doc_answer) client.close()
测试
我们以LLAMA的PDF论文为例,进行多模态问答测试。
首先是基于表格或图片(答案来自表格或图片)的问答:
query: What is LLaMA-7B's zero-shot accuracy on RACE dataset?
answer:
1
LLaMA-7B's zero-shot accuracy on the RACE dataset is 61.1% for RACE-middle and 46.9% for RACE-high.
query: What is LLaMA model's average accuracy on MMLU dataset?
answer:
1 2 3
The LLaMA model's average accuracy on the Massive Multitask Language Understanding (MMLU) dataset is 63.4% as indicated in Table 9.
If you refer to the detailed results provided in Table 16, the average accuracy of the LLaMA 65B model specifically across all domains for the 5-shot setting is 63.4%.
query: LLaMA 7B zero-shot performance on PIQA, SIQA, BoolQ
dataset
answer:
1 2 3 4 5
The zero-shot performance of the LLaMA 7B model on various Common Sense Reasoning tasks, including PIQA, SIQA, and BoolQ, is presented in the last image that contains multiple tables. This particular performance can be found in the "LLaMA 7B" row of the "0-shot" column across different datasets.
For PIQA, the zero-shot performance of LLaMA 7B is 76.5. For SIQA, it is 79.8. For BoolQ, the model scores 48.9.
These numbers indicate how well the LLaMA 7B model can perform on these specific tasks without any fine-tuning or additional shots, relying solely on its pre-existing training and capabilities to infer answers.
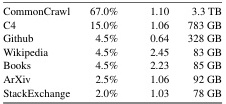
query: pretraining data of LLaMA and their prop
answer:
1 2 3 4 5 6 7 8 9 10 11
The pre-training data of LLaMA and their proportions from the various sources are as follows:
These sources were used for pre-training LLaMA models, with CommonCrawl being the largest proportion of the data used. The percentages indicate how much of each source was included in the mix of pre-training data.
接下来是基于纯文本(答案来自文本而不是表格、图片)的问答:
query: What are mathematical reasoning benchmarks in this
paper?
answer:
1
The mathematical reasoning benchmarks mentioned in the text are MATH and GSM8k. The MATH dataset contains 12K middle school and high school mathematics problems, while the GSM8k is a set of middle school mathematical problems. The paper discusses evaluating models on these benchmarks and comparing model performance, specifically mentioning LLaMA model variants and their performance relative to other models such as PaLM and Minerva.
query: what is the use of TruthfulQA?
answer:
1
TruthfulQA is a benchmark designed to measure the truthfulness of a model's responses. Specifically, it evaluates the ability of a model to identify when a claim is true in the context of "literal truth about the real world" rather than claims that may only be considered true within a belief system or tradition. This means that TruthfulQA aims to help determine how effectively a model can distinguish valid information from misinformation or false claims, which can be indicative of the model's potential to generate reliable or misleading content. It is used to assess the risks of models in generating misinformation and to improve the design of models to mitigate these risks. The benchmark typically includes a set of questions that a language model must answer, and the model's responses are evaluated for both truthfulness and informativeness.