本文将会介绍笔者在2019语言与智能技术竞赛的三元组抽取比赛方面的一次尝试。由于该比赛早已结束,笔者当时也没有参加这个比赛,因此没有测评成绩,我们也只能拿到训练集和验证集。但是,这并不耽误我们在这方面做实验。
比赛介绍
该比赛的网址为:http://lic2019.ccf.org.cn/kg
,该比赛主要是从给定的句子中提取三元组,给定schema约束集合及句子sent,其中schema定义了关系P以及其对应的主体S和客体O的类别,例如(S_TYPE:人物,P:妻子,O_TYPE:人物)、(S_TYPE:公司,P:创始人,O_TYPE:人物)等。比如下面的例子:
1 2 3 4 5 6 7 { "text" : "九玄珠是在纵横中文网连载的一部小说,作者是龙马" , "spo_list" : [ [ "九玄珠" , "连载网站" , "纵横中文网" ] , [ "九玄珠" , "作者" , "龙马" ] ] }
该比赛一共提供了20多万标注质量很高的三元组,其中17万训练集,2万验证集和2万测试集,实体关系(schema)50个。
在具体介绍笔者的思路和实战前,先介绍下本次任务的处理思路:
任务的处理思路
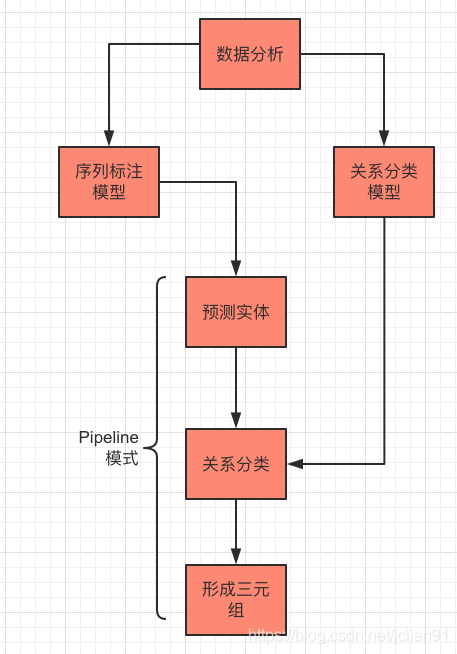
首先是对拿到的数据进行数据分析,包括统计每个句子的长度及三元组数量,每种关系的数量分布情况。接着,对数据单独走序列标注模型和关系分析模型。最后在提取三元组的时候,用Pipeline模型,先用序列标注模型预测句子中的实体,再对实体(加上句子)走关系分类模型,预测实体的关系,最后形成有效的三元组。
接下来笔者将逐一介绍,项目结构图如下:
项目结构图
数据分析
我们能拿到的只有训练集和验证集,没有测试集。我们对训练集做数据分析,训练集数据文件为train_data.json。
数据分析会统计训练集中每个句子的长度及三元组数量,还有关系的分布图,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 import jsonfrom pprint import pprintimport pandas as pdfrom collections import defaultdictimport matplotlib.pyplot as plt18 , 8 ), dpi=100 ) "font.family" ] = 'Arial Unicode MS' def load_data (filename ):with open (filename, 'r' , encoding='utf-8' ) as f:' ' , '' ).replace('\u3000' , '' ).replace('\xa0' , '' ).replace('\u2003' , '' ) for _ in content]for l in content:'text' : l['text' ],'spo_list' : ['subject' ], spo['predicate' ], spo['object' ])for spo in l['spo_list' ]return D'../data/train_data.json' "text" ] for _ in D]len (_["spo_list" ])for _ in D]"text" : text_list, "spo_num" : spo_num} )"text_length" ] = df["text" ].apply(lambda x: len (x))print (df.head())print (df.describe())'spo_num' ].value_counts())list (df['spo_num' ].value_counts().index)'spo_num' ].value_counts().tolist()range (len (num_list))0.6 , color='blue' , label="频数" )0 , 80000 ) "数量" )0.1 for index in x], label_list)"三元组数量" )"三元组频数统计图" )for rect in rects:2 , height+1 , str (height), ha="center" , va="bottom" )'./spo_num_bar_chart.png' )import matplotlib.pyplot as plt18 , 8 ), dpi=100 ) "font.family" ] = 'Arial Unicode MS' int )for spo_dict in D:for spo in spo_dict["spo_list" ]:1 ]] += 1 list (relation_dict.keys())list (relation_dict.values())range (len (num_list))0.6 , color='blue' , label="频数" )0 , 80000 ) "数量" )0.1 for index in x], label_list)45 ) "三元组关系" )"三元组关系频数统计图" )for rect in rects:2 , height+1 , str (height), ha="center" , va="bottom" )'./relation_bar_chart.png' )
输出结果如下:
1 2 3 4 5 6 7 8 9 spo_num text_lengthcount 173108 .000000 173108 .000000 mean 2 .103993 54 .057190 std 1 .569331 31 .498245 min 0 .000000 5 .000000 25 % 1 .000000 32 .000000 50 % 2 .000000 45 .000000 75 % 2 .000000 68 .000000 max 25 .000000 300 .000000
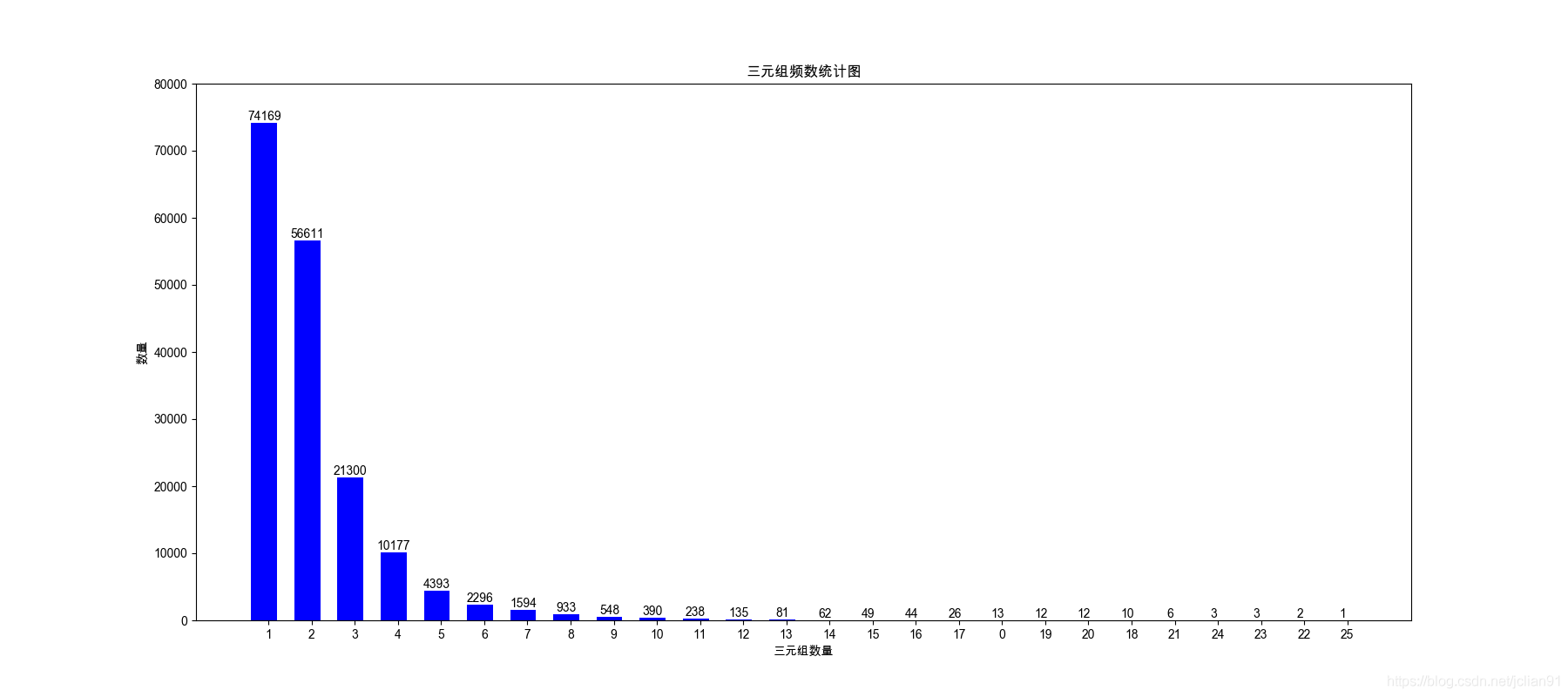
句子的平均长度为54,最大长度为300;每句话中的三元组数量的平均值为2.1,最大值为25。
每句话中的三元组数量的分布图如下:
每句话中的三元组数量分布图
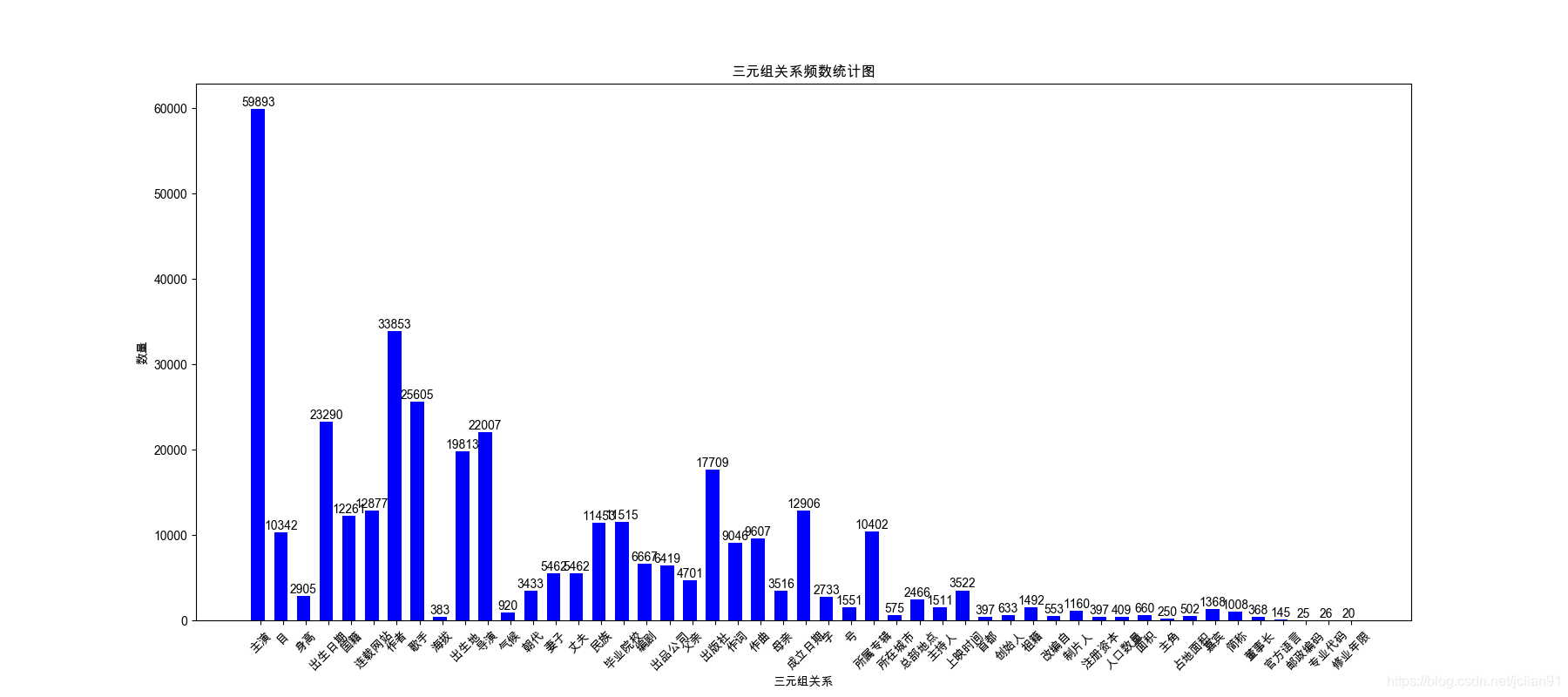
关系数量的分布图如下:
关系数量分布图
序列标注模型
我们将句子中的主体和客体作为实体,分别标注为SUBJ和OBJ,标注体系采用BIO。一个简单的标注例子如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 如 O
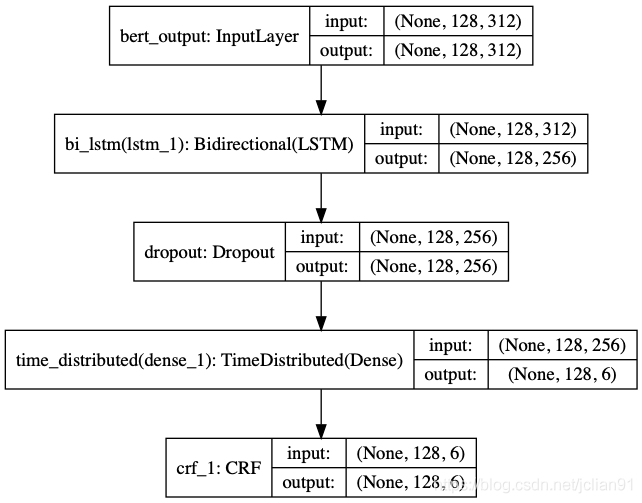
序列标注的模型采用ALBERT+Bi-LSTM+CRF,结构图如下:
序列标注模型结构图
模型方面的代码不再具体给出,有兴趣的同学可以参考文章NLP(二十五)实现ALBERT+Bi-LSTM+CRF模型 ,也可以参考文章最后给出的Github项目网址。
模型设置文本最大长度为128,利用ALBERT做特征提取,在自己的电脑上用CPU训练5个epoch,结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 _________________________________________________________________173109 samples, validate on 21639 samples1 /10 173109 /173109 [==============================] - 422s 2ms/ step - loss: 0.4460 - crf_viterbi_accuracy: 0.8710 - val_loss: 0.1613 - val_crf_viterbi_accuracy: 0.9235 2 /10 173109 /173109 [==============================] - 417s 2ms/ step - loss: 0.1170 - crf_viterbi_accuracy: 0.9496 - val_loss: 0.0885 - val_crf_viterbi_accuracy: 0.9592 3 /10 173109 /173109 [==============================] - 417s 2ms/ step - loss: 0.0758 - crf_viterbi_accuracy: 0.9602 - val_loss: 0.0653 - val_crf_viterbi_accuracy: 0.9638 4 /10 173109 /173109 [==============================] - 415s 2ms/ step - loss: 0.0586 - crf_viterbi_accuracy: 0.9645 - val_loss: 0.0544 - val_crf_viterbi_accuracy: 0.9651 5 /10 173109 /173109 [==============================] - 422s 2ms/ step - loss: 0.0488 - crf_viterbi_accuracy: 0.9663 - val_loss: 0.0464 - val_crf_viterbi_accuracy: 0.9654 6 /10 173109 /173109 [==============================] - 423s 2ms/ step - loss: 0.0399 - crf_viterbi_accuracy: 0.9677 - val_loss: 0.0375 - val_crf_viterbi_accuracy: 0.9660 7 /10 173109 /173109 [==============================] - 415s 2ms/ step - loss: 0.0293 - crf_viterbi_accuracy: 0.9687 - val_loss: 0.0265 - val_crf_viterbi_accuracy: 0.9664 8 /10 173109 /173109 [==============================] - 414s 2ms/ step - loss: 0.0174 - crf_viterbi_accuracy: 0.9695 - val_loss: 0.0149 - val_crf_viterbi_accuracy: 0.9671 9 /10 173109 /173109 [==============================] - 422s 2ms/ step - loss: 0.0049 - crf_viterbi_accuracy: 0.9703 - val_loss: 0.0036 - val_crf_viterbi_accuracy: 0.9670 10 /10 173109 /173109 [==============================] - 429s 2ms/ step - loss: -0.0072 - crf_viterbi_accuracy: 0.9709 - val_loss: -0.0078 - val_crf_viterbi_accuracy: 0.9674 0.9593 0.9026 0.9301 44598 0.9670 0.9238 0.9449 25521 0.9621 0.9104 0.9355 70119 0.9621 0.9104 0.9355 70119
利用seqeval模块做评估,在验证集上的F1值约为93.55%。
关系分类模型
需要对关系做一下说明,因为笔者会对句子(sent)中的主体(S)和客体(O)组合起来,加上句子,形成训练数据。举个例子,在句子历史评价李氏朝鲜的创立并非太祖大王李成桂一人之功﹐其五子李芳远功不可没,三元组为[{"predicate": "父亲", "object_type": "人物", "subject_type": "人物", "object": "李成桂", "subject": "李芳远"}, {"predicate": "国籍", "object_type": "国家", "subject_type": "人物", "object": "朝鲜", "subject": "李成桂"}]},在这句话中主体有李成桂,李芳远,客体有李成桂和朝鲜,关系有父亲(关系类型:2)和国籍(关系类型:22)。按照笔者的思路,这句话应组成4个关系分类样本,如下:
1 2 3 4 2 李芳远$李成桂$历史评价李氏朝鲜的创立并非太祖大王###一人之功﹐其五子###功不可没0 李芳远$朝鲜$历史评价李氏##的创立并非太祖大王李成桂一人之功﹐其五子###功不可没0 李成桂$李成桂$历史评价李氏朝鲜的创立并非太祖大王###一人之功﹐其五子李芳远功不可没22 李成桂$朝鲜$历史评价李氏##的创立并非太祖大王###一人之功﹐其五子李芳远功不可没
因此,就会出现关系0(表示“未知”),这样我们在提取三元组的时候就可以略过这条关系,形成真正有用的三元组。
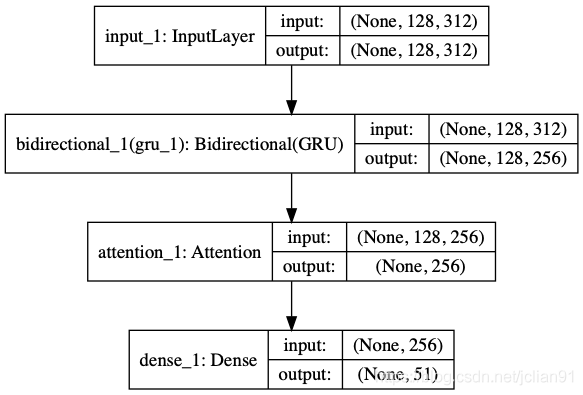
因此,关系一共为51个(加上未知关系:0)。关系分类模型采用ALBERT+Bi-GRU+ATT,结构图如下:
关系分类模型图
模型方面的代码不再具体给出,有兴趣的同学可以参考文章NLP(二十一)人物关系抽取的一次实战 ,也可以参考文章最后给出的Github项目网址。
模型设置文本最大长度为128,利用ALBERT做特征提取,在自己的电脑上用CPU训练30个epoch(实际上,由于有early
stopping机制,训练不到30个eopch),在验证集上的评估结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 Epoch 23 /30 396766 /396766 [============================== ] - 776s 2ms/step - loss: 0.1770 - accuracy: 0.9402 - val_loss: 0.2170 - val_accuracy: 0.9308 Epoch 00023: val_accuracy did not improve from 0.93292 49506 /49506 [============================== ] - 151s 3ms/step 在测试集上的效果: [0.21701653493155634 , 0.930776059627533 ]precision recall f1-score support 未知 0.87 0.76 0.81 5057 祖籍 0.92 0.73 0.82 181 父亲 0.79 0.88 0.83 609 总部地点 0.95 0.95 0.95 310 出生地 0.94 0.95 0.94 2330 目 1.00 1.00 1.00 1271 面积 0.90 0.92 0.91 79 简称 0.97 0.99 0.98 138 上映时间 0.94 0.98 0.96 463 妻子 0.91 0.83 0.87 680 所属专辑 0.97 0.97 0.97 1282 注册资本 1.00 1.00 1.00 63 首都 0.92 0.96 0.94 47 导演 0.92 0.94 0.93 2603 字 0.96 0.97 0.97 339 身高 0.98 0.98 0.98 393 出品公司 0.96 0.96 0.96 851 修业年限 1.00 1.00 1.00 2 出生日期 0.99 0.99 0.99 2892 制片人 0.69 0.88 0.77 127 母亲 0.75 0.88 0.81 425 编剧 0.82 0.80 0.81 771 国籍 0.92 0.92 0.92 1621 海拔 1.00 1.00 1.00 43 连载网站 0.98 1.00 0.99 1658 丈夫 0.84 0.91 0.87 678 朝代 0.85 0.92 0.88 419 民族 0.98 0.99 0.99 1434 号 0.95 0.99 0.97 197 出版社 0.98 0.99 0.99 2272 主持人 0.82 0.86 0.84 200 专业代码 1.00 1.00 1.00 3 歌手 0.89 0.94 0.91 2857 作词 0.85 0.81 0.83 884 主角 0.86 0.77 0.81 39 董事长 0.81 0.74 0.78 47 毕业院校 0.99 0.99 0.99 1433 占地面积 0.89 0.89 0.89 61 官方语言 1.00 1.00 1.00 15 邮政编码 1.00 1.00 1.00 4 人口数量 1.00 1.00 1.00 45 所在城市 0.90 0.94 0.92 77 作者 0.97 0.97 0.97 4359 成立日期 0.99 0.99 0.99 1608 作曲 0.78 0.77 0.78 849 气候 1.00 1.00 1.00 103 嘉宾 0.76 0.72 0.74 158 主演 0.94 0.97 0.95 7383 改编自 0.95 0.82 0.88 71 创始人 0.86 0.87 0.86 75 accuracy 0.93 49506 macro avg 0.92 0.92 0.92 49506 weighted avg 0.93 0.93 0.93 49506
三元组提取
最后一部分,也是本次比赛的最终目标,就是三元组提取。
三元组提取采用Pipeline模式,先用序列标注模型预测句子中的实体,然后再用关系分类模型判断实体关系的类别,过滤掉关系为未知的情形,就是我们想要提取的三元组了。
三元组提取的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 import os, re, json, tracebackimport jsonimport numpy as npfrom keras_contrib.layers import CRFfrom keras_contrib.losses import crf_lossfrom keras_contrib.metrics import crf_accuracy, crf_viterbi_accuracyfrom keras.models import load_modelfrom collections import defaultdictfrom pprint import pprintfrom text_classification.att import Attentionfrom albert_zh.extract_feature import BertVectorwith open ("../sequence_labeling/ccks2019_label2id.json" , "r" , encoding="utf-8" ) as h:for k, v in label_id_dict.items()}"NONE" , max_seq_len=128 )lambda text: bert_model.encode([text])["encodes" ][0 ]'CRF' : CRF, 'crf_loss' : crf_loss, 'crf_viterbi_accuracy' : crf_viterbi_accuracy}"../sequence_labeling/ccks2019_ner.h5" , custom_objects=custom_objects)'../text_classification/models/per-rel-08-0.9234.h5' "Attention" : Attention})with open ("../data/relation2id.json" , "r" , encoding="utf-8" ) as g:for k, v in relation_id_dict.items()}def get_entity (sent, tags_list ):list )0 for char, tag in zip (sent, tags_list):if 'B-' in tag:1 '-' )[-1 ]while j < min (len (sent), len (tags_list)) and 'I-%s' % entity_type in tags_list[j]:1 1 return dict (entity_dict)class TripleExtract (object ):def __init__ (self, text ):" " , "" ) def get_entity (self ):2 )for _ in y[0 ] if _]return get_entity(self.text, y)def relation_classify (self ):list (set (entities.get("SUBJ" , [])))list (set (entities.get("OBJ" , [])))for subj in subjects:for obj in objs:'$' .join([subj, obj, self.text.replace(subj, '#' *len (subj)).replace(obj, "#" *len (obj))])"encodes" ][0 ]0 ])if relation != "未知" :return spo_listdef extractor (self ):return self.relation_classify()
运行三元组提取脚本,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from pprint import pprintfrom triple_extract.triple_extractor import TripleExtract"真人版的《花木兰》由新西兰导演妮基·卡罗执导,由刘亦菲、甄子丹、郑佩佩、巩俐、李连杰等加盟,几乎是全亚洲阵容。" print ("原文: %s" % text)print ("实体: " , end ='' )print ("三元组: " , end ='' )
我们在网上找几条样本进行测试,测试的结果如下:
原文:
真人版的《花木兰》由新西兰导演妮基·卡罗执导,由刘亦菲、甄子丹、郑佩佩、巩俐、李连杰等加盟,几乎是全亚洲阵容。
实体: {'OBJ': ['妮基·卡罗', '刘亦菲', '甄子丹', '郑佩佩', '巩俐',
'李连杰'], 'SUBJ': ['花木兰']} 三元组: [['花木兰', '主演', '刘亦菲'],
['花木兰', '导演', '妮基·卡罗'], ['花木兰', '主演', '甄子丹'],
['花木兰', '主演', '李连杰'], ['花木兰', '主演', '郑佩佩'], ['花木兰',
'主演', '巩俐']]
原文:
《冒险小王子》作者周艺文先生,教育、文学领域的专家学者以及来自全国各地的出版业从业者参加了此次沙龙,并围绕儿童文学创作这一话题做了精彩的分享与交流。
实体: {'OBJ': ['周艺文'], 'SUBJ': ['冒险小王子']} 三元组:
[['冒险小王子', '作者', '周艺文']]
原文:
宋应星是江西奉新人,公元1587年生,经历过明朝腐败至灭亡的最后时期。
实体: {'OBJ': ['江西奉新', '1587年'], 'SUBJ': ['宋应星']} 三元组:
[['宋应星', '出生地', '江西奉新'], ['宋应星', '出生日期', '1587年']]
原文: 韩愈,字退之,河阳(今河南孟县)人。 实体: {'OBJ': ['退之',
'河阳'], 'SUBJ': ['韩愈']} 三元组: [['韩愈', '出生地', '河阳'],
['韩愈', '字', '退之']]
原文:
公开资料显示,李强,男,汉族,出生于1971年12月,北京市人,北京市委党校在职研究生学历,教育学学士学位,1996年11月入党,1993年7月参加工作。
实体: {'OBJ': ['汉族', '1971年12月', '北京市', '北京市委党校'], 'SUBJ':
['李强']} 三元组: [['李强', '民族', '汉族'], ['李强', '出生地',
'北京市'], ['李强', '毕业院校', '北京市委党校'], ['李强', '出生日期',
'1971年12月']]
原文:
杨牧,本名王靖献,早期笔名叶珊,1940年生于台湾花莲,著名诗人、作家。
实体: {'OBJ': ['1940年', '台湾花莲'], 'SUBJ': ['杨牧']} 三元组:
[['杨牧', '出生地', '台湾花莲'], ['杨牧', '出生日期', '1940年']]
原文: 杨广是隋文帝杨坚的第二个儿子。 实体: {'OBJ': ['杨坚'],
'SUBJ': ['杨广']} 三元组: [['杨广', '父亲', '杨坚']]
原文:
此次权益变动后,何金明与妻子宋琦、其子何浩不再拥有对上市公司的控制权。
实体: {'OBJ': ['何金明'], 'SUBJ': ['宋琦', '何浩']} 三元组: [['何浩',
'父亲', '何金明'], ['宋琦', '丈夫', '何金明']]
原文:
线上直播发布会中,谭维维首次演绎了新歌《章存仙》,这首歌由钱雷作曲、尹约作词,尹约也在直播现场透过手机镜头跟网友互动聊天。
实体: {'OBJ': ['谭维维', '钱雷', '尹约', '尹约'], 'SUBJ': ['章存仙']}
三元组: [['章存仙', '作曲', '钱雷'], ['章存仙', '作词', '尹约'],
['章存仙', '歌手', '谭维维']]
原文: “土木之变”后,造就了明代杰出的民族英雄于谦。 实体: {'OBJ':
['明代'], 'SUBJ': ['于谦']} 三元组: [['于谦', '朝代', '明代']]
原文:
另外,哈尔滨历史博物馆也是全国面积最小的国有博物馆,该场馆面积只有50平方米,可称之“微缩博物馆”。
实体: {'OBJ': ['50平方米'], 'SUBJ': ['哈尔滨历史博物馆']} 三元组:
[['哈尔滨历史博物馆', '占地面积', '50平方米']]
原文: 孙杨的妈妈叫杨明,孙杨的名字后面一个字也是来源于她的名字。
实体: {'OBJ': ['杨明', '孙杨'], 'SUBJ': ['孙杨']} 三元组: [['孙杨',
'母亲', '杨明']]
原文:
企查查显示,达鑫电子成立于1998年6月,法定代表人张高圳,注册资本772.33万美元,股东仅新加坡达鑫控股有限公司一名。
实体: {'OBJ': ['1998年6月'], 'SUBJ': ['达鑫电子']} 三元组:
[['达鑫电子', '成立日期', '1998年6月']]
总结
本文标题为限定领域的三元组抽取的一次尝试,之所以取名为限定领域,是因为该任务的实体关系是确定,一共为50种关系。
当然,上述方法还存在着诸多不足,参考苏建林的文章基于DGCNN和概率图的轻量级信息抽取模型 ,我们发现不足之处如下:
主体和客体的标注策略有问题,因为句子中有时候主体和客体会重叠在一起;
新引入了一类关系:未知,是否有办法避免引入;
其他(暂时未想到)
从比赛的角度将,本文的办法效果未知,应该会比联合模型的效果差一些。但是,这是作为笔者自己的模型,算法是一种尝试,之所以采用这种方法,是因为笔者一开始是从开放领域的三元组抽取入手的,而这种方法方便扩展至开放领域。关于开放领域的三元组抽取,笔者稍后就会写文章介绍,敬请期待。
本文的源代码已经公开至Github,网址为: https://github.com/percent4/ccks_triple_extract
。
参考网址
NLP(二十五)实现ALBERT+Bi-LSTM+CRF模型:https://blog.csdn.net/jclian91/article/details/104826655
NLP(二十一)人物关系抽取的一次实战:
https://blog.csdn.net/jclian91/article/details/104380371
基于DGCNN和概率图的轻量级信息抽取模型:https://spaces.ac.cn/archives/6671
欢迎关注我的公众号
NLP奇幻之旅 ,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅 ”,笔者正在努力构建自己的技术社区。