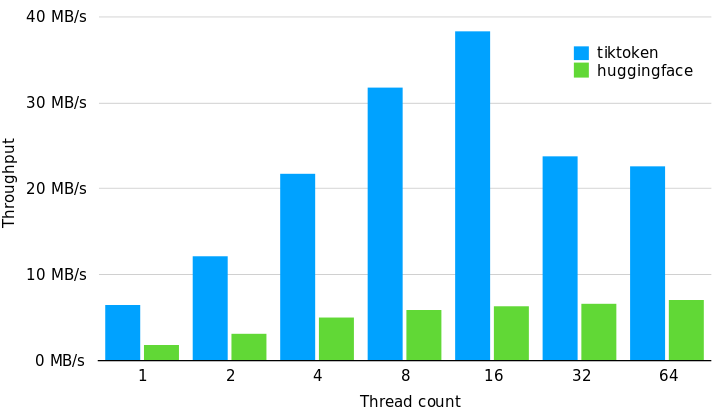
defnum_tokens_from_string(string: str, encoding_name: str) -> int: # Returns the number of tokens in a text string. encoding = tiktoken.get_encoding(encoding_name) num_tokens = len(encoding.encode(string)) return num_tokens
print(num_tokens_from_string('tiktoken is great!', 'cl100k_base')) print(num_tokens_from_string('大模型是什么?', 'cl100k_base'))
defnum_tokens_from_messages(messages): # Returns the number of tokens used by a list of messages. encoding = tiktoken.encoding_for_model("gpt-3.5-turbo") tokens_per_message = 4# every message follows <|start|>{role/name}\n{content}<|end|>\n tokens_per_name = -1# if there's a name, the role is omitted num_tokens = 0 for message in messages: num_tokens += tokens_per_message for key, value in message.items(): num_tokens += len(encoding.encode(value)) if key == "name": num_tokens += tokens_per_name num_tokens += 3# every reply is primed with <|start|>assistant<|message|> return num_tokens
example_messages = [ { "role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English.", }, { "role": "system", "name": "example_user", "content": "New synergies will help drive top-line growth.", }, { "role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue.", }, { "role": "system", "name": "example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage.", }, { "role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better.", }, { "role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable.", }, ]
# example token count from the function defined above print(f"{num_tokens_from_messages(example_messages)} prompt tokens counted by num_tokens_from_messages().") # example token count from the OpenAI API openai.api_key = "" response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=example_messages, temperature=0, max_tokens=1 ) print(f'{response["usage"]["prompt_tokens"]} prompt tokens counted by the OpenAI API.')
输出结果如下:
1 2
127 prompt tokens counted by num_tokens_from_messages(). 127 prompt tokens counted by the OpenAI API.