NLP(五十四)在Keras中使用英文Roberta模型实现文本分类
英文Roberta模型是2019年Facebook在论文RoBERTa: A Robustly
Optimized BERT Pretraining
Approach中新提出的预训练模型,其目的是改进BERT模型存在的一些问题,当时也刷新了一众NLP任务的榜单,达到SOTA效果,其模型和代码已开源,放在Github中的fairseq项目中。众所周知,英文Roberta模型使用Torch框架训练的,因此,其torch版本模型最为常见。
当然,torch模型也是可以转化为tensorflow模型的。本文将会介绍如何将原始torch版本的英文Roberta模型转化为tensorflow版本模型,并且Keras中使用tensorflow版本模型实现英语文本分类。
项目结构如下图所示:
模型转化
本项目首先会将原始torch版本的英文Roberta模型转化为tensorflow版本模型,该部分代码主要参考Github项目keras_roberta。
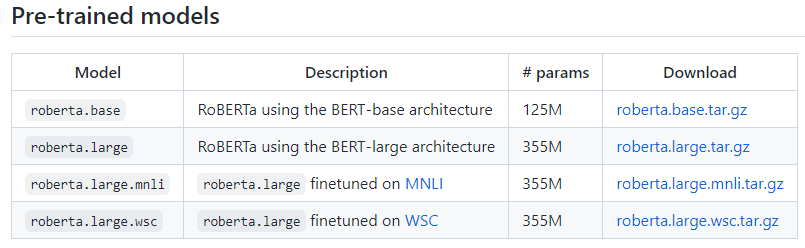
首先需下载Facebook发布在fairseq项目中的roberta
base模型,其访问网址为: https://github.com/pytorch/fairseq/blob/main/examples/roberta/README.md。
运行convert_roberta_to_tf.py脚本,将torch模型转化为tensorflow模型。具体代码不在此给出,可以参考文章后续给出的Github项目地址。
在模型的tokenizer方面,将RobertaTokenizer改为GPT2Tokenizer,因为RobertaTokenizer是继承自GPT2Tokenizer的,两者相似性很高。测试原始torch模型和tensorflow模型的表现,代码如下(tf_roberta_demo.py):
1 | |
输出结果如下:
1 | |
可以看到,两者在tokenize时的token_ids是一致的。
英语文本分类
接着我们需要看下转化为的tensorflow版本的Roberta模型在英语文本分类数据集上的效果了。
这里我们使用的是GLUE数据集中的SST-2。SST-2(The
Stanford Sentiment
Treebank,斯坦福情感树库),单句子分类任务,包含电影评论中的句子和它们情感的人类注释。这项任务是给定句子的情感,类别分为两类正面情感(positive,样本标签对应为1)和负面情感(negative,样本标签对应为0),并且只用句子级别的标签。也就是,本任务也是一个二分类任务,针对句子级别,分为正面和负面情感。关于该数据集的具体介绍可参考网址:https://nlp.stanford.edu/sentiment/index.html。
SST-2数据集中训练集样本数量为67349,验证集样本数量为872,测试集样本数量为1820,数据存储格式为tsv,读取数据的代码如下:(utils/load_data.py)
1 | |
在tokenizer部分,我们采用GTP2Tokenizer,该部分代码如下(utils/roberta_tokenizer.py):
1 | |
创建模型如下(model_train.py):
1 | |
模型参数如下:
1 | |
模型训练完后,在验证数据集上的准确率(accuracy)为0.9415,F1值为0.9415,取得了不错效果。
模型预测
我们对新样本进行模型预测(model_predict.py),预测结果如下:
Awesome movie for everyone to watch. Animation was flawless. label: 1, prob: 0.9999607
I almost balled my eyes out 5 times. Almost. Beautiful movie, very inspiring. label: 1, prob: 0.9999519
Not even worth it. It's a movie that's too stupid for adults, and too crappy for everyone. Skip if you're not 13, or even if you are. label: 0, prob: 0.9999864
总结
本文介绍了如何将原始torch版本的英文Roberta模型转化为tensorflow版本模型,并且Keras中使用tensorflow版本模型实现英语文本分类。
本项目代码已放至Github,网址为:https://github.com/percent4/keras_roberta_text_classificaiton。
感谢阅读,如有任何问题,欢迎大家交流~
参考网址
fairseq: https://github.com/pytorch/fairseqGLUE tasks: https://gluebenchmark.com/tasksSST-2: https://nlp.stanford.edu/sentiment/index.htmlkeras_roberta: https://github.com/midori1/keras_robertaRoberta paper: https://arxiv.org/pdf/1907.11692.pdf

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
