NLP(八十一)智能文档问答助手项目改进
本文将介绍笔者自己的项目:智能文档问答助手项目的几个改进。
本文将介绍笔者自己开源的项目:智能文档问答助手项目的几个改进点。
不熟悉这个项目的读者可以参考下面两篇文章及Github项目地址:
- NLP(六十一)使用Baichuan-13B-Chat模型构建智能文档
- NLP(六十九)智能文档助手升级
- llm_4_doc_qa: https://github.com/percent4/llm_4_doc_qa
本次改进点如下:
- 文件上传页面支持自定义输入文本
- 上传文件数据分析
- 在RAG架构中加入Rerank模块
- 加入ChatGPT系列模型
- 对问答结果加入模型评估
下面将详细介绍上述改进点。
自定义输入文本
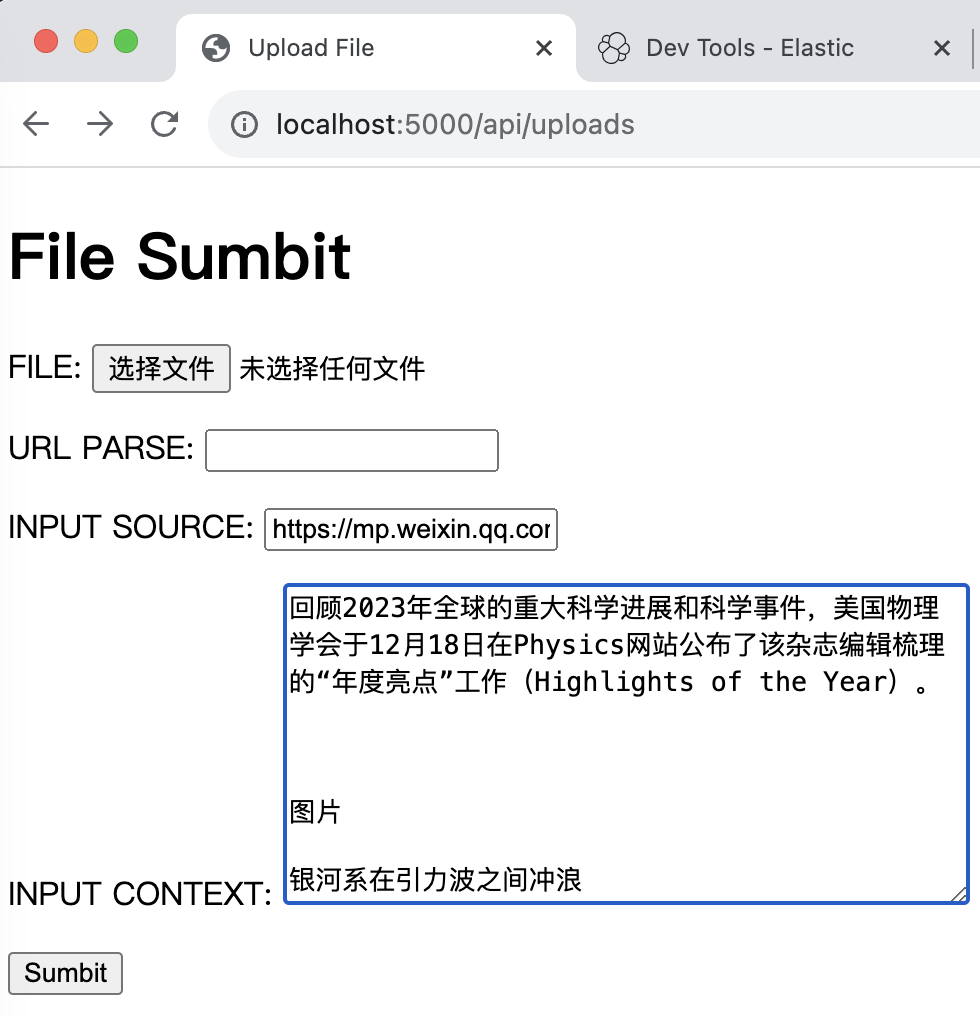
本项目中api/uploads接口用于文件上传,一共是三种形式:
- 用户直接上传文件,文件格式暂时只支持txt, docx, pdf;
- 用户输入网页网址,后端调用LangChain中的selenium和unstructed模块进行网页解析;
- 本次新增:支持用户自定义输入文本,必须填写文本来源和内容。
数据分析
为支持在Kibana中对上传文件内容进行数据分析,ElasticSearch中的mapping配置修改如下:
1 | |
其中, insert_time用于记录文本插入时间,source用于记录文件类型,共五种:
- txt: txt文件
- docx: docx文件
- pdf: pdf文件
- url: 用户输入的网址
- string: 用户自定义输入
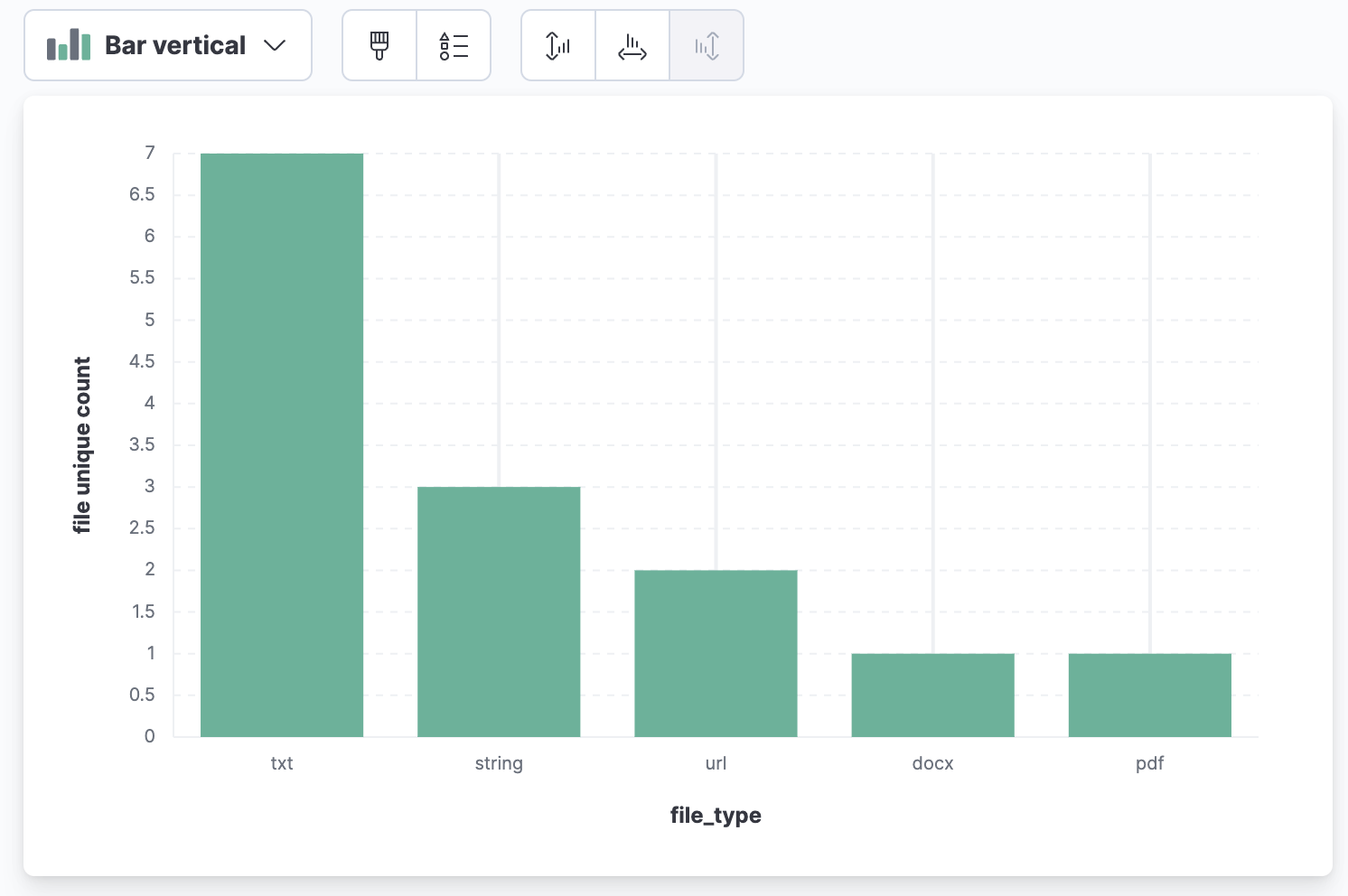
在Kibana中使用可视化功能进行数据分析,首先统计每种文件类型的chunk(对文本内容进行划分,每个单位记为一个chunk)数据表格及柱状图、饼图:
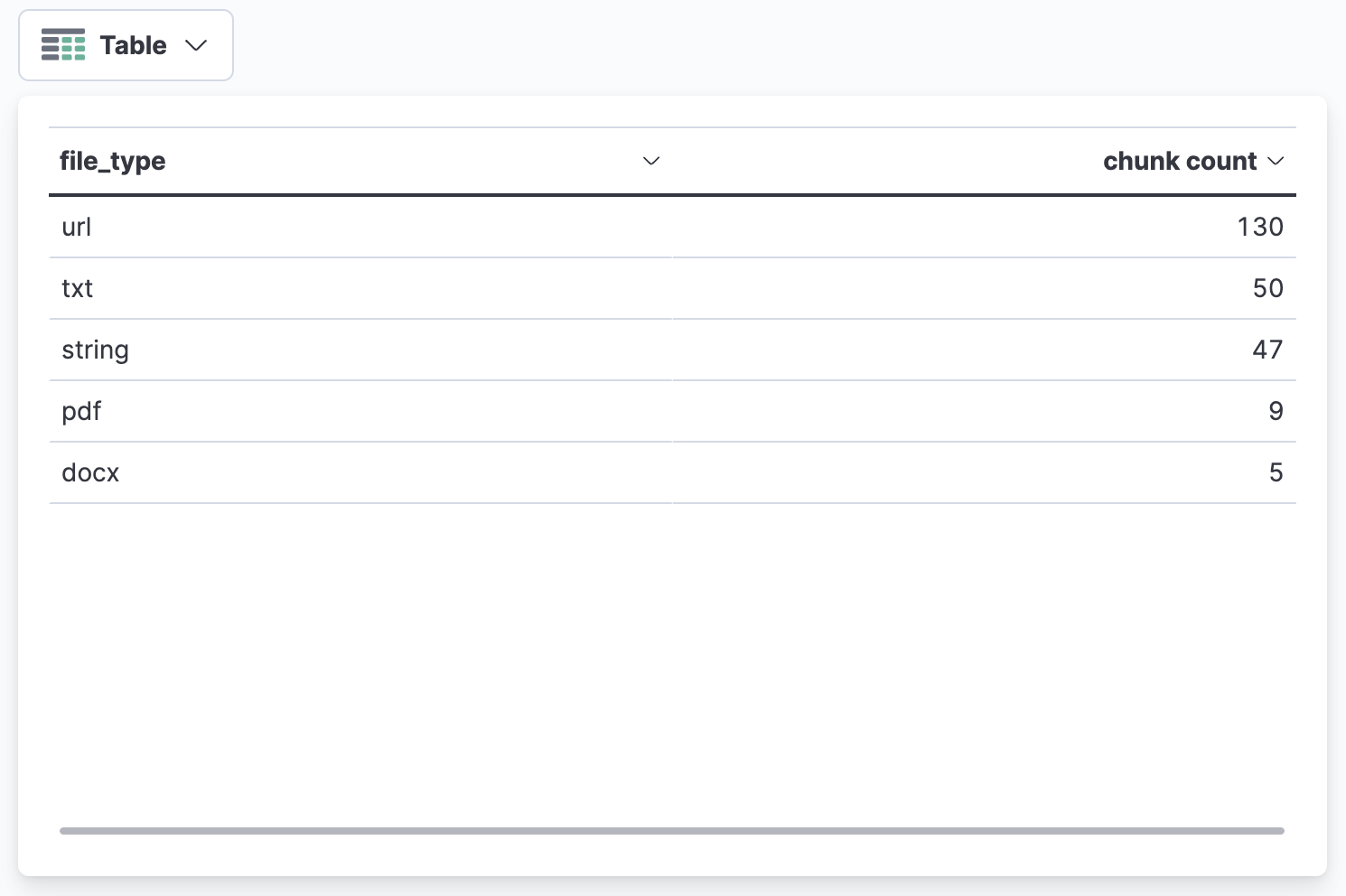
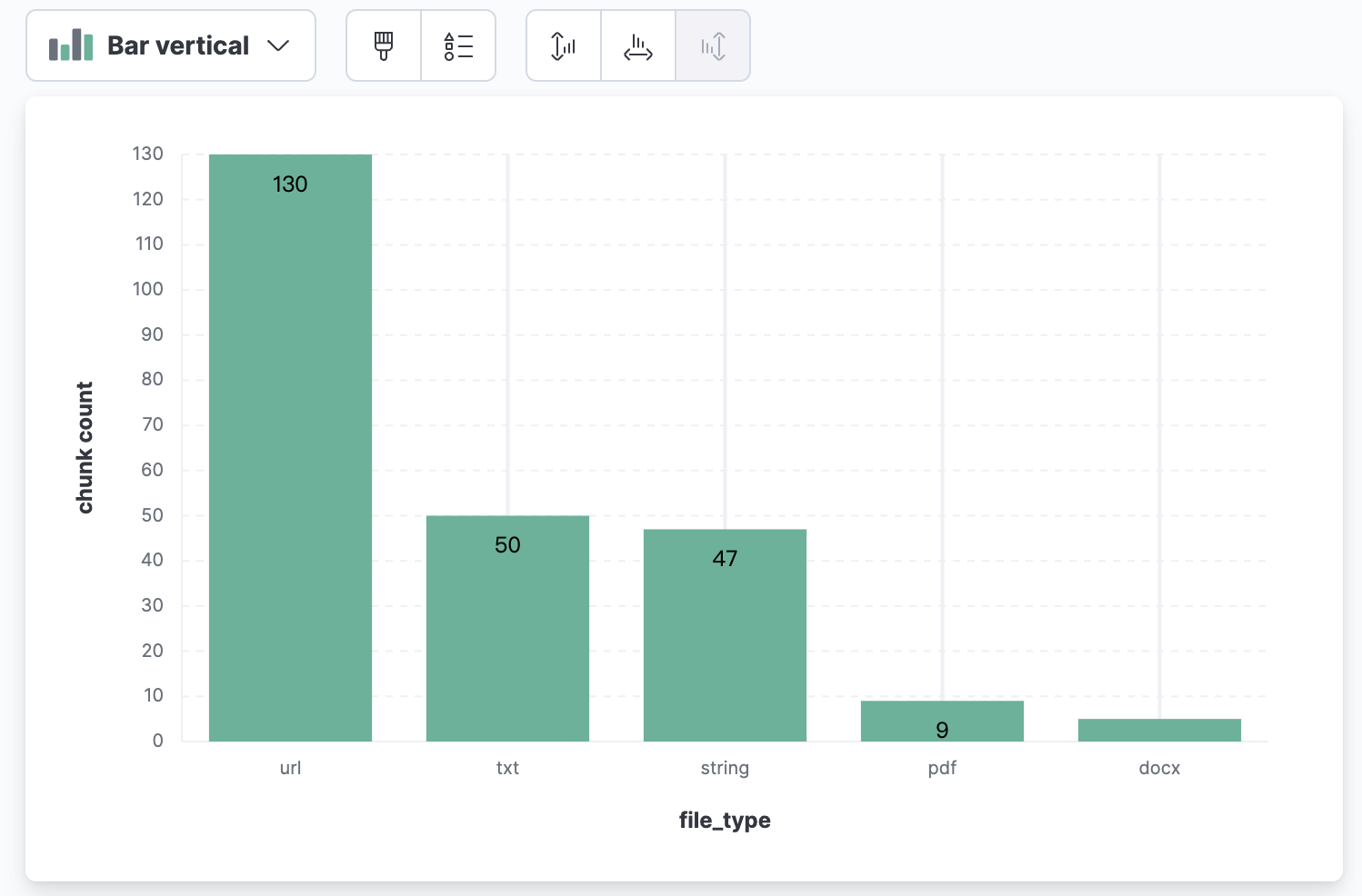
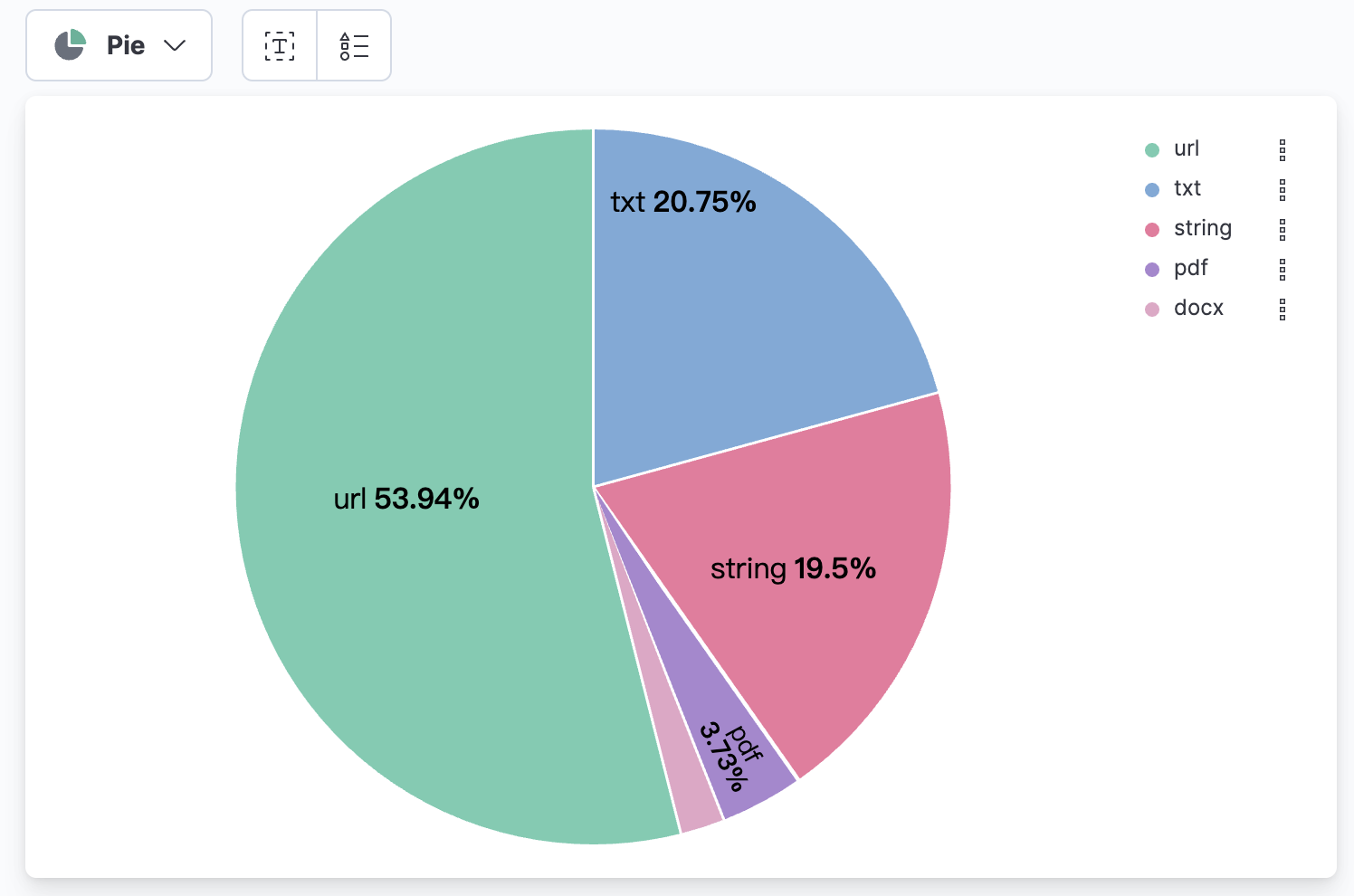
每个文件类型的文件数量(使用source.keyword字段进行统计):
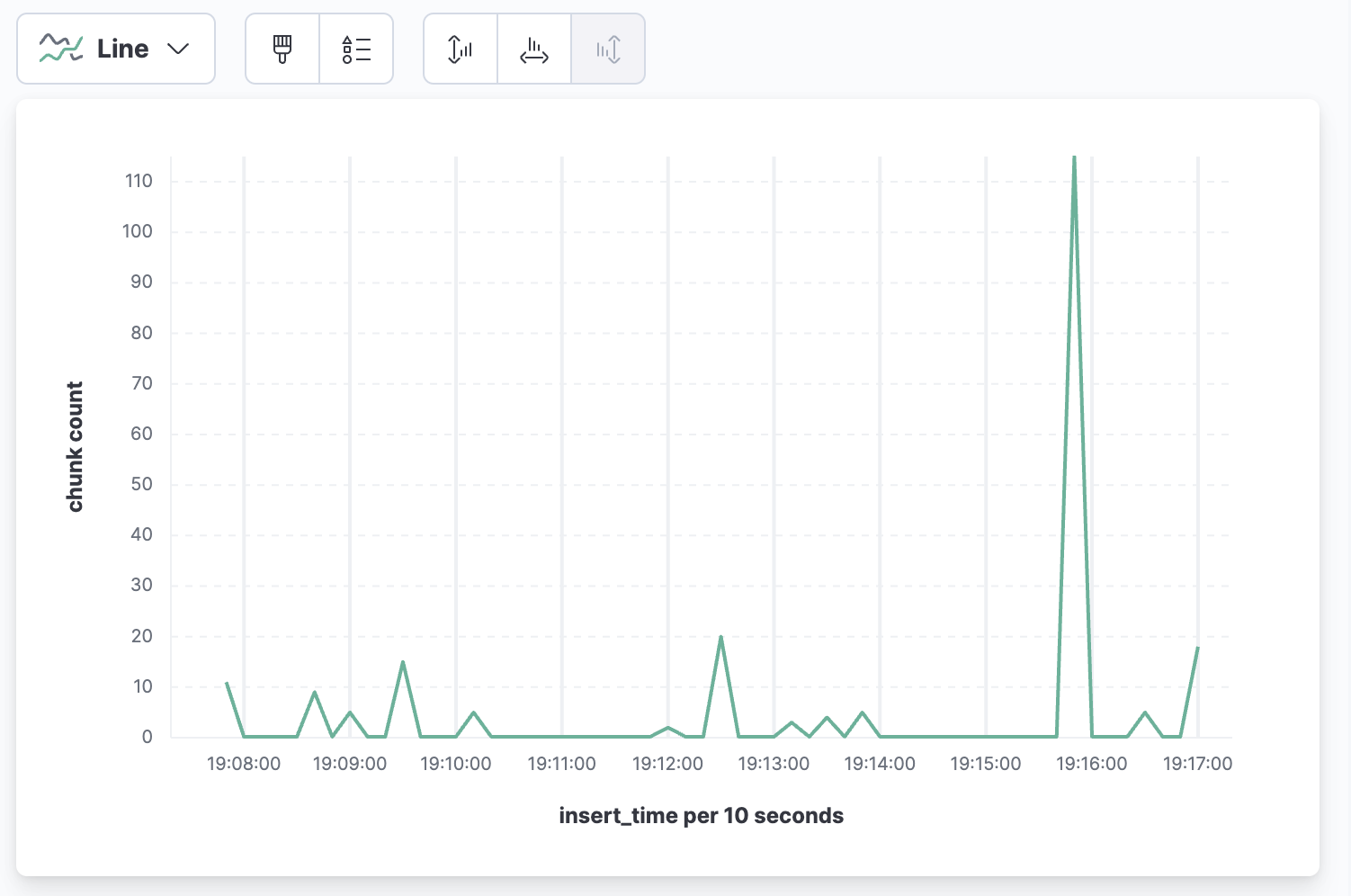
文件插入时间与chunk数量的折线图(可用于记录不同时间段,插入的chunk数量统计):
P.S.
Kibana的可视化功能还是相当丰富的,值得一学,后续笔者也会写文章专门介绍Kibana中的可视化功能。
Rerank模块
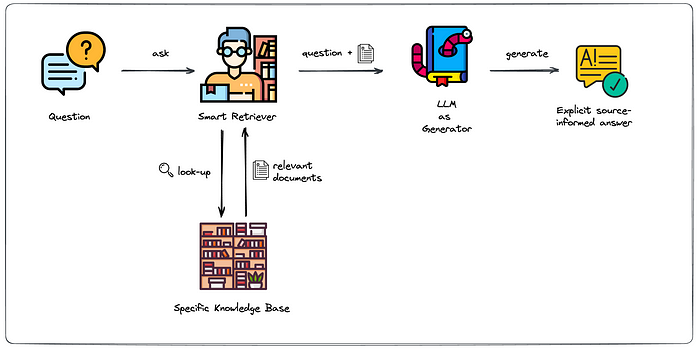
本项目采用RAG框架进行文档问答,一般步骤为:
- 文档划分(Document Split)
- 向量嵌入(Embedding)
- 文档获取(Retrieve)
- Prompt工程(Prompt Engineering)
- 大模型问答(LLM)
大致的流程图参考如下:
但在实际使用过程中,召回阶段(Retrieve)的文档相关性及排序结果不是很好,因此需要加入Rerank阶段,即重排或精排阶段。
本次加入的Rerank模型为Cohere官方网站给出的Rerank模型,在效果评估中效果最好,优于BGE模型。
以下为Cohere Rerank模型的示例代码:
输入query:
电子科技大学的官网?使用Rerank前的召回文档排序(ES+Milvus, 按相似度排序):
院校&专业高考备考高一/高二家长助考新东方网主站中学高考高考资讯焦点新闻电子科技大学:2022年全国招生总计划5030人 招生专业上有“三变化”新东方编辑整理 |2023-03-13 15:04 分享至 复制链接1.请使用微信扫码2.打开网页后点击屏幕右上角分享按钮
拉斯哥大学交流学习的机会,也可以申请3+2、4+1等海外联合培养模式。师资主要由电子科技大学与格拉斯哥大学的优秀老师进行授课。毕业时所颁发的毕业证与学位证与“电子科技大学”招生名称的证书完全一致,同时还能获得格拉斯哥大学的学位证书。由于是首年进行招生,这个项目可能会成为今年填报志愿的价值洼地。
其次是深造情况,近十年学校深造率不断提升,最近两届毕业生深造率继续保持高位超过70%,位居全国所有高校的第4位。国内深造学生到双一流高校及研究院所深造的比例超过了99%,在出国(境)深造的学生中,去往世界前100位的大学就读占比超过70%。所以同样的,我们在深造方面,也是不仅深造率高,同样深造的质量也是非常高的。九、学校咨询方式或联系方式。1.信息平台微信公众号:电子科大本科招生(uestc_zs)官网:http://www.zs.uestc.edu.cn/
二、2022年学校招生计划如何安排?有无增减?今年电子科技大学的招生总规模与往年相比,维持相对的稳定。2022年,我们在全国招生总计划是5030人,其中“电子科技大学”将面向全国招生3300余人,“电子科技大学(沙河校区)”将面向部分省份招生1700余人。电子科技大学将继续采用“电子科技大学”、“电子科技大学(沙河校区)”两个名称进行招生,考生在填报志愿时应分别填报,录取时分别录取,对应着不同的录取分数线。
Python代码如下:
1 | |
使用Rerank后的召回文档排序:
1 | |
可以看到,召回阶段的文档相关性及排序结果不佳,但经过Rerank阶段后,文档相关性及排序结果得到很大改善。后续可以专门做实验来验证下,虽然网络上已经有不少公开实验结果了。
加入ChatGPT系列模型
之前的项目只支持国产中文大模型,如Baichuan, LLAMA-Chinese, InterLM等,本次新增ChatGPT-3.5和GPT-4模型,Embedding模型新增text-embedding-ada-002。
在笔者的使用测试中,Openai的ChatGPT-3.5和GPT-4模型问答效果优于之前的国产中文大模型。
模型评估(Evaluation)
在文章NLP(八十)大模型评估(Evaluation)中,笔者介绍了如何使用LangChain框架及GPT-4模型来进行模型评估。
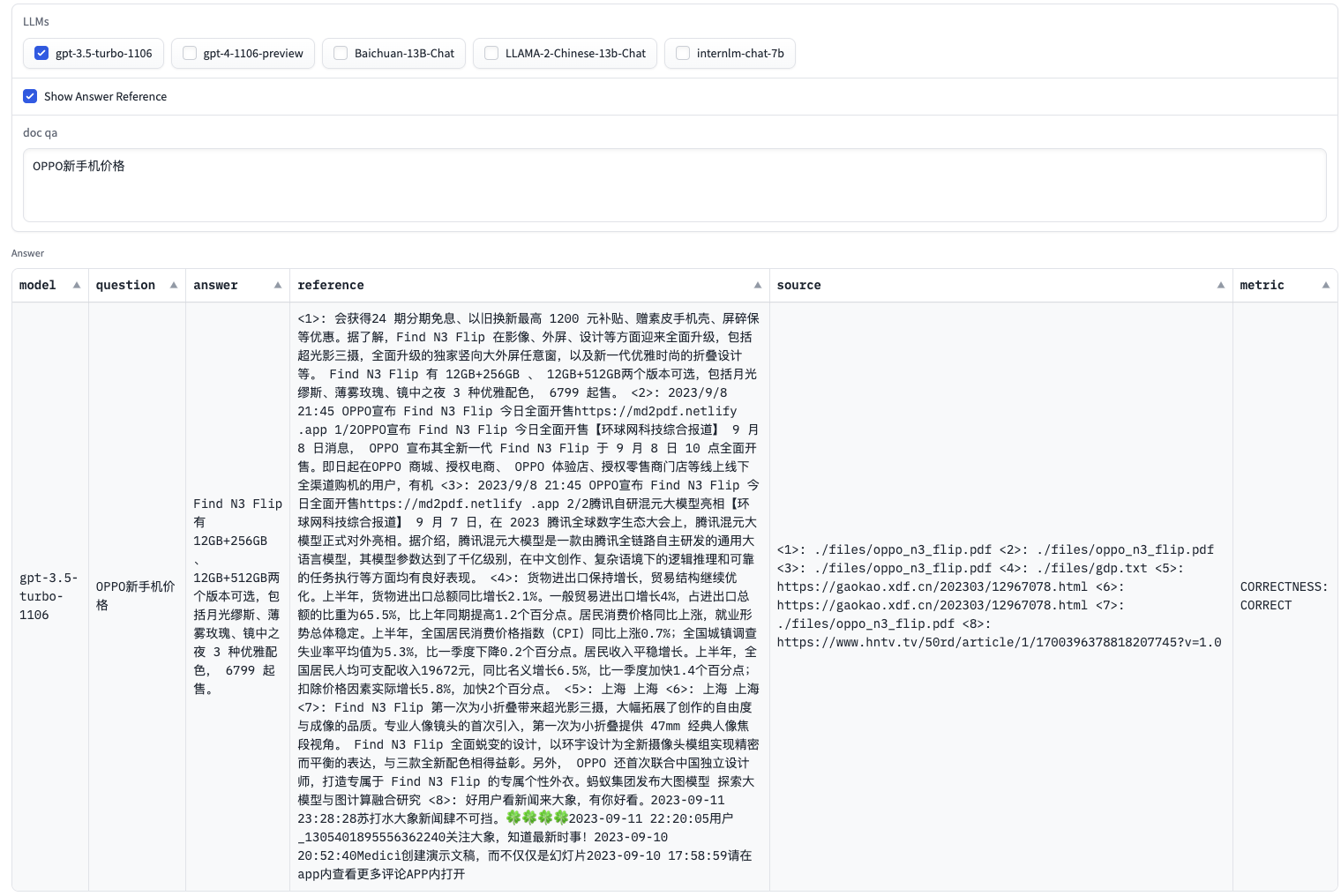
因此,在本次的更新中,在可视化页面中加入了GPT-4模型评估,如下图:
总结
智能文档问答助手项目是笔者在RAG研究方向中的一次开源实战,会注重实际体验效果,但更关注算法层面的实现。
因此,笔者会持续更新,也会更多地加入RAG框架上的优化点,欢迎大家关注~
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
