NLP(八十三)RAG框架中的Rerank算法评估
本文将详细介绍RAG框架中的两种Rerank模型的评估实验:bge-reranker和Cohere Rerank。
在文章NLP(八十二)RAG框架中的Retrieve算法评估中,我们在评估Retrieve算法的时候,发现在Ensemble Search阶段之后加入Rerank算法能有效提升检索效果,其中top_3的Hit Rate指标增加约4%。
因此,本文将深入Rerank算法对比,主要对比bge-reranker和Cohere Rerank两种算法,分析它们对于提升检索效果的作用。
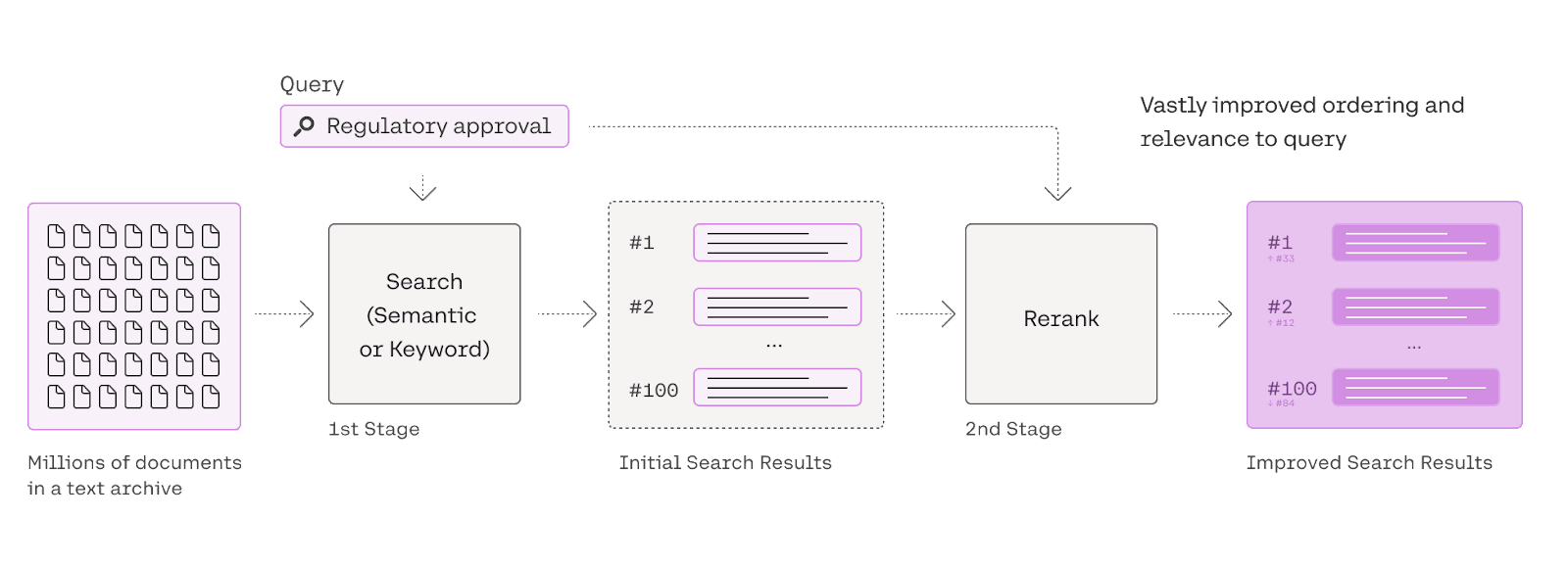
为什么需要重排序?
混合检索通过融合多种检索技术的优势,能够提升检索的召回效果。然而,这种方法在应用不同的检索模式时,必须对结果进行整合和标准化处理。标准化是指将数据调整到一致的标准范围或格式,以便于更有效地进行比较、分析和处理。在完成这些步骤后,这些数据将整合并提供给大型模型进行处理。为了实现这一过程,我们需要引入一个评分系统,即重排序模型(Rerank Model),它有助于进一步优化和精炼检索结果。
Rerank模型通过对候选文档列表进行重新排序,以提高其与用户查询语义的匹配度,从而优化排序结果。该模型的核心在于评估用户问题与每个候选文档之间的关联程度,并基于这种相关性给文档排序,使得与用户问题更为相关的文档排在更前的位置。这种模型的实现通常涉及计算相关性分数,然后按照这些分数从高到低排列文档。市场上已有一些流行的重排序模型,例如
Cohere rerank、bge-reranker
等,它们在不同的应用场景中表现出了优异的性能。
BGE-Reranker模型
Cohere Rerank模型目前闭源,对外提供API,普通账号提供免费使用额度,生产环境最好使用付费服务,因此,本文不再过多介绍,关于这块的文章可参考其官网博客:https://txt.cohere.com/rerank/ .
bge-reranker是BAAI(北京智源人工智能研究院)发布的系列模型之一,包括Embedding、Rerank系列模型等。bge-reranker模型在HuggingFace上开源,有base、large两个版本模型。
借助FlagEmbedding,我们以BAAI/bge-reranker-base模型为例,使用FastAPI封装成HTTP服务,Python代码如下:
1 | |
计算"上海天气"与"北京美食"、"上海气候"的Rerank相关性分数,请求如下:
1 | |
输出如下:
1 | |
评估实验
我们使用NLP(八十二)RAG框架中的Retrieve算法评估中的数据集和评估代码,在ensemble search阶段之后加入BGE-Reranker服务API调用。
其中,bge-reranker-base的评估结果如下:
| retrievers | hit_rate | mrr |
|---|---|---|
| ensemble_bge_base_rerank_top_1_eval | 0.8255 | 0.8255 |
| ensemble_bge_base_rerank_top_2_eval | 0.8785 | 0.8489 |
| ensemble_bge_base_rerank_top_3_eval | 0.9346 | 0.8686 |
| ensemble_bge_base_rerank_top_4_eval | 0.947 | 0.872 |
| ensemble_bge_base_rerank_top_5_eval | 0.9564 | 0.8693 |
bge-reranker-large的评估结果如下:
| retrievers | hit_rate | mrr |
|---|---|---|
| ensemble_bge_large_rerank_top_1_eval | 0.8224 | 0.8224 |
| ensemble_bge_large_rerank_top_2_eval | 0.8847 | 0.8364 |
| ensemble_bge_large_rerank_top_3_eval | 0.9377 | 0.8572 |
| ensemble_bge_large_rerank_top_4_eval | 0.9502 | 0.8564 |
| ensemble_bge_large_rerank_top_5_eval | 0.9626 | 0.8537 |
以Ensemble Search为baseline,分别对三种Rerank模型进行Hit Rate指标统计,柱状图如下:
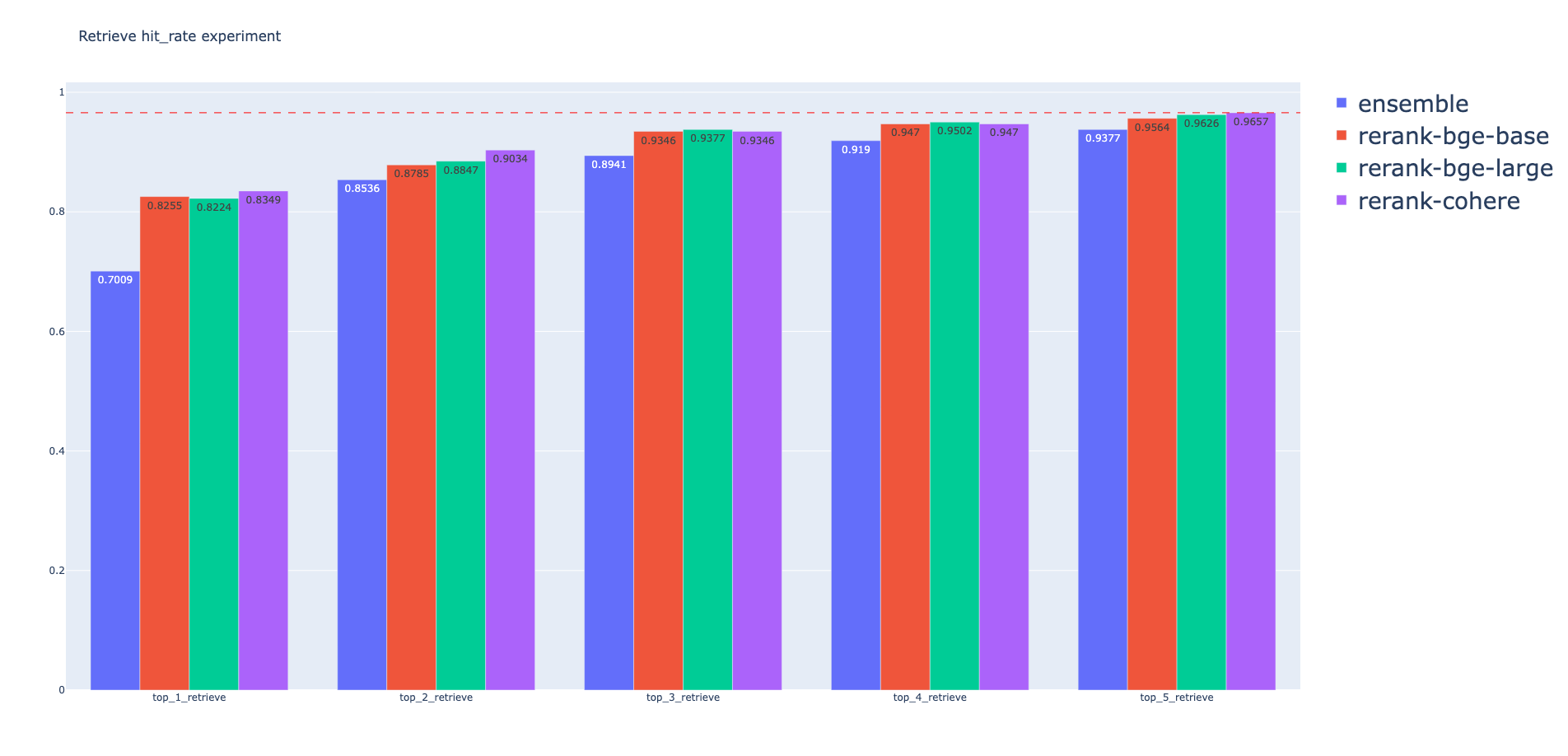
从上述的统计图中可以得到如下结论:
- 在Ensemble Search阶段后加入Rerank模型会有检索效果提升
- 就检索效果而言,Rerank模型的结果为:Cohere > bge-rerank-large > bge-rerank-base,但效果相差不大
总结
本文详细介绍了RAG框架中的两种Rerank模型的评估实验:bge-reranker和Cohere Rerank,算是在之前Retrieve算法评估实验上的延续工作,后续将会有更多工作持续更新。
本文的所有过程及指标结果已开源至Github,网址为:https://github.com/percent4/embedding_rerank_retrieval .
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
