NLP(八十五)多模态模型Yi-VL-34B初步使用
本文将会介绍笔者在使用多模态模型Yi-VL-34B中所遇到的坑以及具体的使用体验。
2024年1月22日,零一万物Yi系列模型家族迎来新成员:Yi
Vision
Language(Yi-VL)多模态语言大模型正式面向全球开源。据悉,Yi-VL模型基于Yi语言模型开发,包括
Yi-VL-34B和Yi-VL-6B两个版本。
凭借卓越的图文理解和对话生成能力,Yi-VL模型在英文数据集MMMU和中文数据集CMMMU上取得了领先成绩,其中在MMMU上的指标仅次于GPT-4V,而在CMMMU上的指标仅次于GPT-4V和Qwen-VL-Plus展示了在复杂跨学科任务上的强大实力。
目前,Yi-VL模型已经开源,网址如下:
- 国外平台HuggingFace: https://huggingface.co/01-ai/Yi-VL-34B
- 国内平台ModelScope(魔搭社区): https://www.modelscope.cn/organization/01ai
本文将分以下三部分展开:
Yi-VL模型部署- CLI模式模型推理
- 可视化模型问答
本文中的模型以Yi-VL-34B模型为准。
模型部署
HuggingFace网站中介绍了Yi-VL-34B模型的部署方式,主要参考LLaVA框架,但笔者尝试几天,发现需要修改的代码较多,遇到了不少坑,仍无法部署。
而在Yi的Github项目中给出了方便的模型部署方式,可参考项目:https://github.com/01-ai/Yi/tree/0124/VL。
模块安装:第三方模块: torch == 2.1.2,其余模块参考Github项目中的requirements.txt文件。
其余修改:将
Yi-VL-34B模型中config.json中的mm_vision_tower改为本地的clip模型路径。
经过以上步骤即可完成部署。Yi-VL-34B模型在对话中的system
prompt调整如下:
This is a chat between an inquisitive human and an AI assistant. Assume the role of the AI assistant. Read all the images carefully, and respond to the human's questions with informative, helpful, detailed and polite answers. 这是一个好奇的人类和一个人工智能助手之间的对话。假设你扮演这个AI助手的角色。仔细阅读所有的图像,并对人类的问题做出信息丰富、有帮助、详细的和礼貌的回答。
### Human: <image_placeholder>
Describe the cats and what they are doing in detail.
### Assistant:模型推理
以命令行(CLI)的模型进行模型推理,需要将图片下载至images文件夹,同时将single_inference.py略作调整,以支持多次提问。
运行命令如下:
1 | |
模型推理时使用一张A100(显存80G)就可满足推理要求。
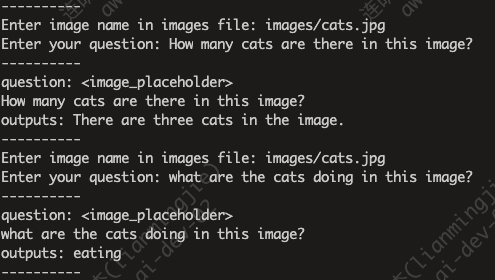
示例图片如下:

回复结果如下:
可视化模型问答
基于此,我们将会用gradio模块,对Yi-VL-34B模型和GPT-4V模型的结果进行对比。
Python代码如下:
1 | |
以下是对不同模型和问题的回复:
- 图片:taishan.jpg,问题:这张图片是中国的哪座山?

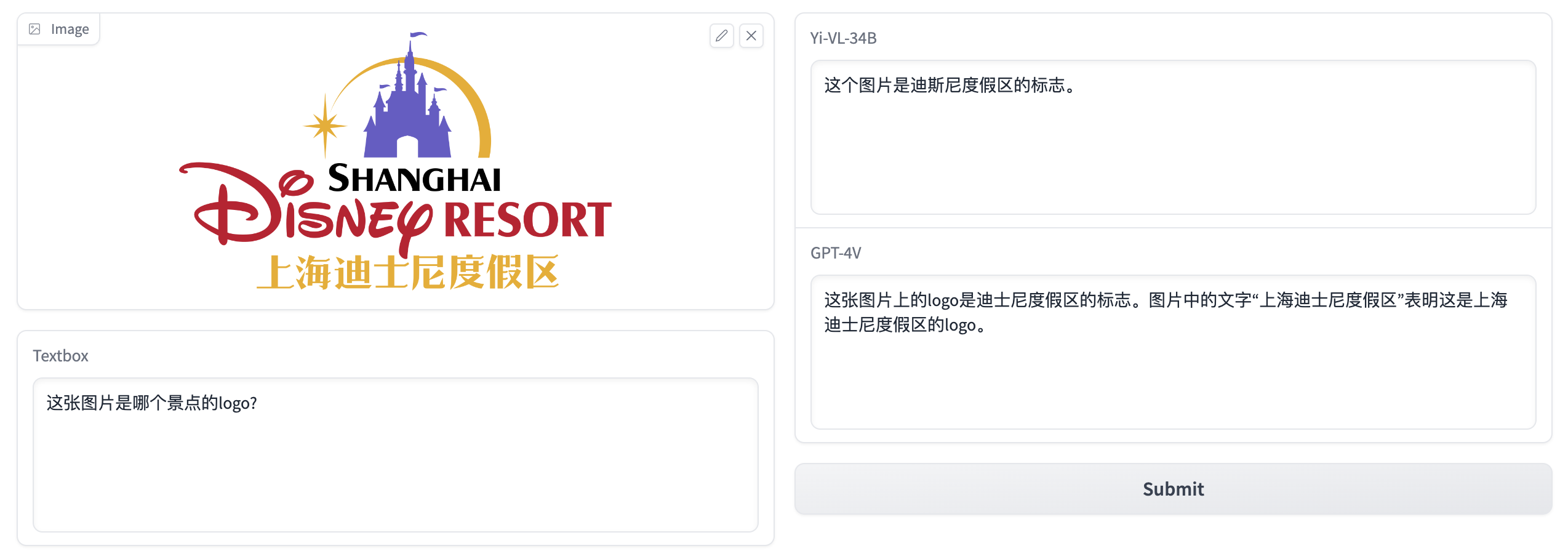
- 图片:dishini.jpg,问题:这张图片是哪个景点的logo?
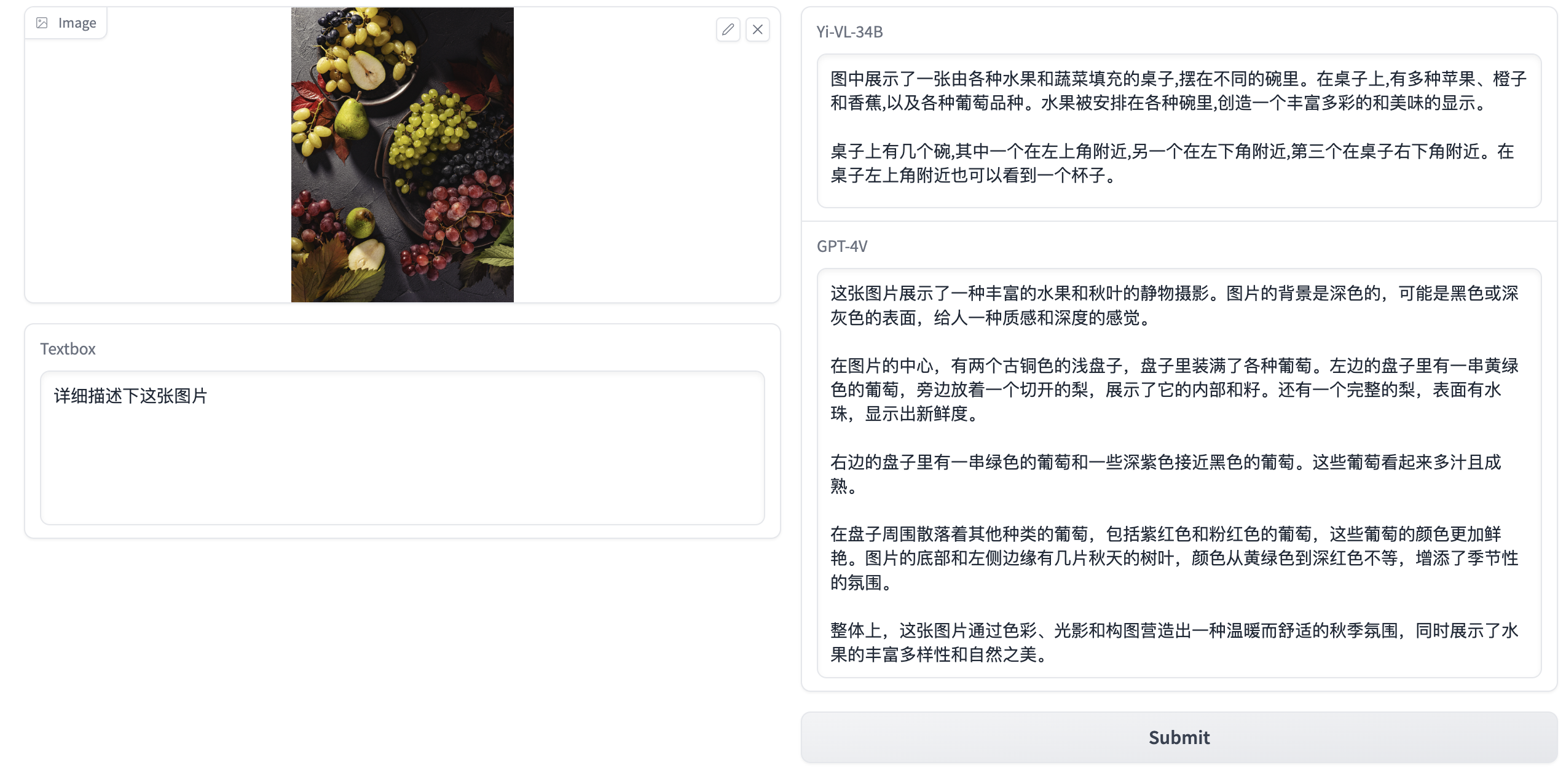
- 图片:fruit.jpg,问题:详细描述下这张图片
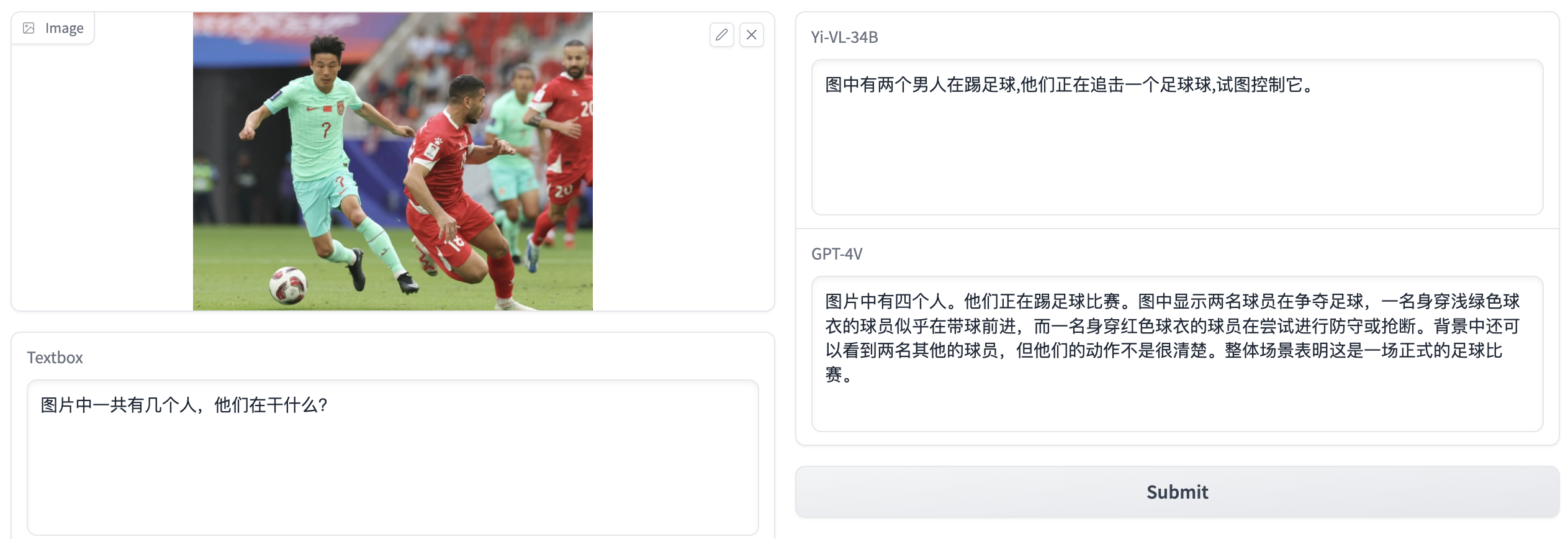
- 图片:football.jpg,问题:图片中一个有几个人,他们在干什么?
- 图片:cartoon.jpg,问题:这张图片是哪部日本的动漫?
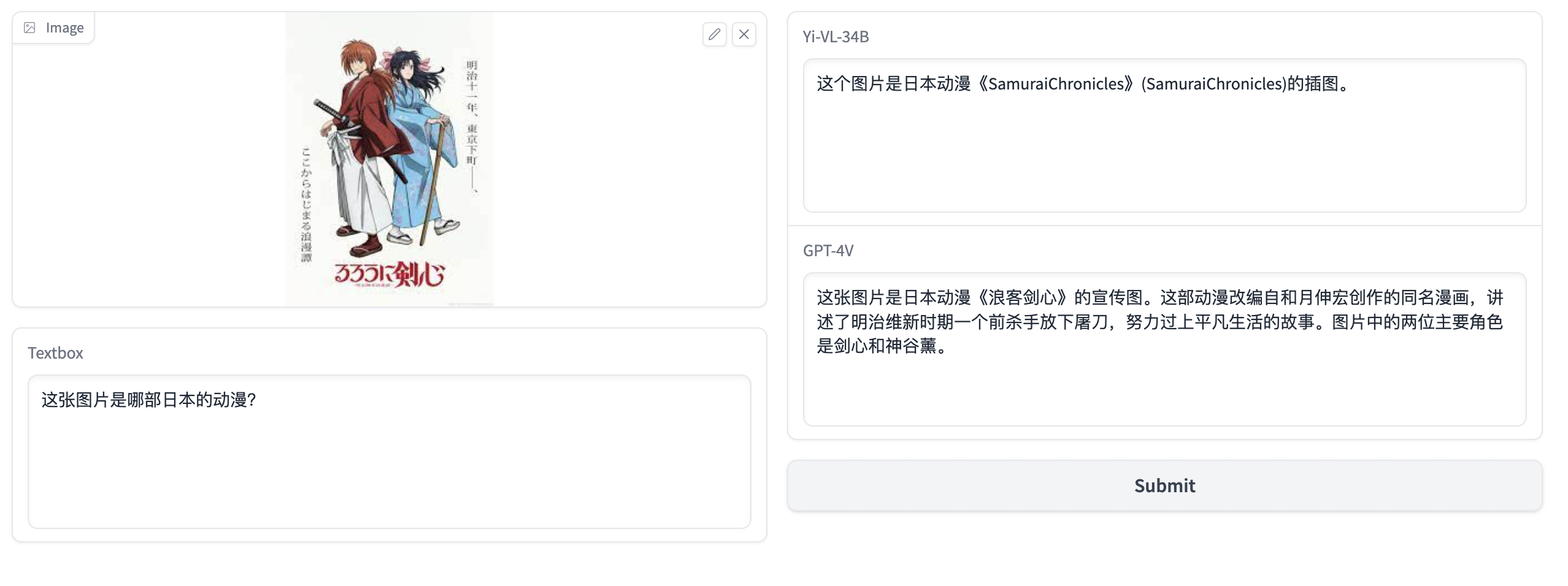
从以上的几个测试用例来看,Yi-VL-34B模型的效果很不错,但对比GPT-4V模型,不管在图片理解,还是模型的回答上,仍有一定的差距。
最后,我们来看一个验证码的例子(因为GPT-4V是不能用来破解验证码的!)

可以看到,Yi-VL-34B模型在尝试回答,但给出了错误答案,而GPT-4V模型则会报错,报错信息如下:
1 | |
无疑,GPT-4V模型这样的设计是合情合理的。
总结
Yi-VL-34B模型的开源,无疑是多模态大模型领域中的惊艳之作,让我们在为数不多的国产多模态大模型中多了一个选择,而且由于是开源,因此我们能做的事情会更多。与此同时,它与GPT-4V模型还存在着不小差距,可见GPT-4V模型的强大。
有了多模态大模型的加入,我们在RAG框架中,可以加入图片,结合图文理解,丰富召回的素材的多样性。这是多模态大模型的其中应用方向之一,笔者将会在后续关注。
本文介绍的代码已经开源,Github网址为:https://github.com/percent4/yi_vl_experiment.
感谢阅读~
参考文献
- https://github.com/01-ai/Yi/discussions/335
- 零一万物Yi-VL多模态大模型开源,MMMU、CMMMU两大权威榜单领先: https://www.jiqizhixin.com/articles/2024-01-22-10

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
