NLP(八十八)使用LLaVA模型实现以文搜图和以图搜图
本文将会介绍如何使用多模态模型–LLaVA模型来实现以文搜图和以图搜图的功能。
本文将会详细介绍如何使用多模态模型——LLaVA模型来实现以文搜图和以图搜图的功能。本文仅为示例Demo,并不能代表实际的以文搜图和以图搜图的技术实现方案。
在介绍笔者的实现方案前,我们先了解下这个方案中所需要用到的模型:
- 多模态模型:LLaVA-1.6-34 B,主要用于图片理解,本文的使用场景为获取图片标题和图片内容描述。
- OCR模型:PaddleOCR,主要用于图片中的文字识别。
- ReRank模型:BCE ReRank模型,主要用于文本匹配,本文的使用场景为匹配两张图片的内容描述。
下面将按功能进行阐述,主要分为以下三部分:
- 图片上传
- 以文搜图
- 以图搜图
图片上传
在图片上传功能中,笔者的Web实现采用Gradio模块,用户自行决定是否使用OCR模型,并结合OCR结果,使用多模态模型来获取用户上传图片(网址)的标题和详细内容描述,最后将这些图片相关的数据存入ElasticSearch数据库中用于图片检索。
其中,OCR模型和多模态模型部署在GPU端,这里不再详细介绍,用户可参考本文文末给出的Github地址。
图片上传的Python代码如下:
1 | |
我们上传一张手机图片(网址为:https://picx.zhimg.com/v2-b9966bc144bf536dbb8c9a35f763d90c_r.jpg?source=172ae18b ),结果如下:

这里可以看到,LLaVA的图片理解能力是非常出色的。
下面,我们来看看引入OCR模型后的图片理解效果。
未使用OCR模型,仅使用多模态模型的效果:
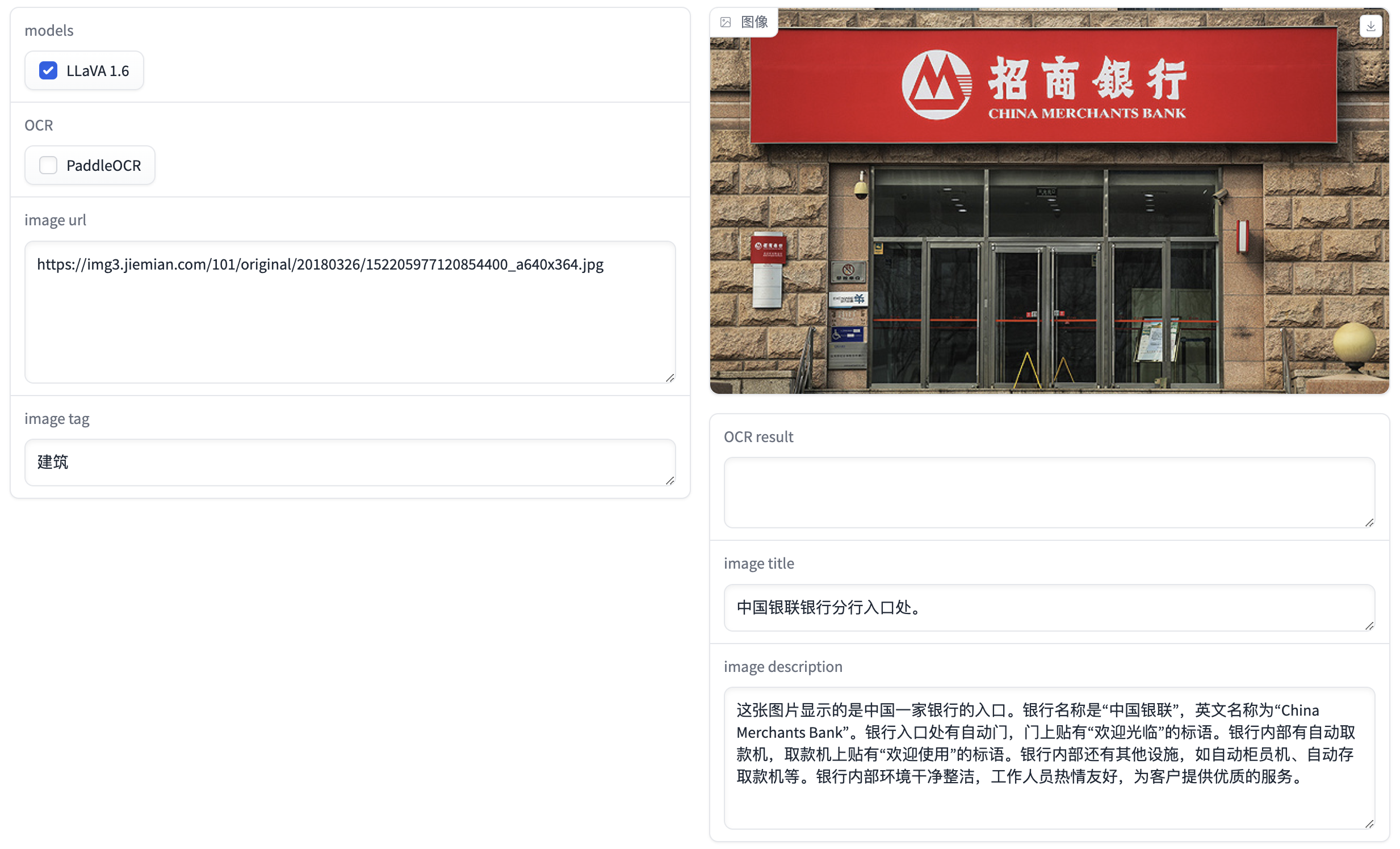
图片内容描述为:
这张图片显示的是中国一家银行的入口。银行名称是“中国银联”,英文名称为“China Merchants Bank”。银行入口处有自动门,门上贴有“欢迎光临”的标语。银行内部有自动取款机,取款机上贴有“欢迎使用”的标语。银行内部还有其他设施,如自动柜员机、自动存取款机等。银行内部环境干净整洁,工作人员热情友好,为客户提供优质的服务。
使用OCR模型来增强多模态模型的效果:
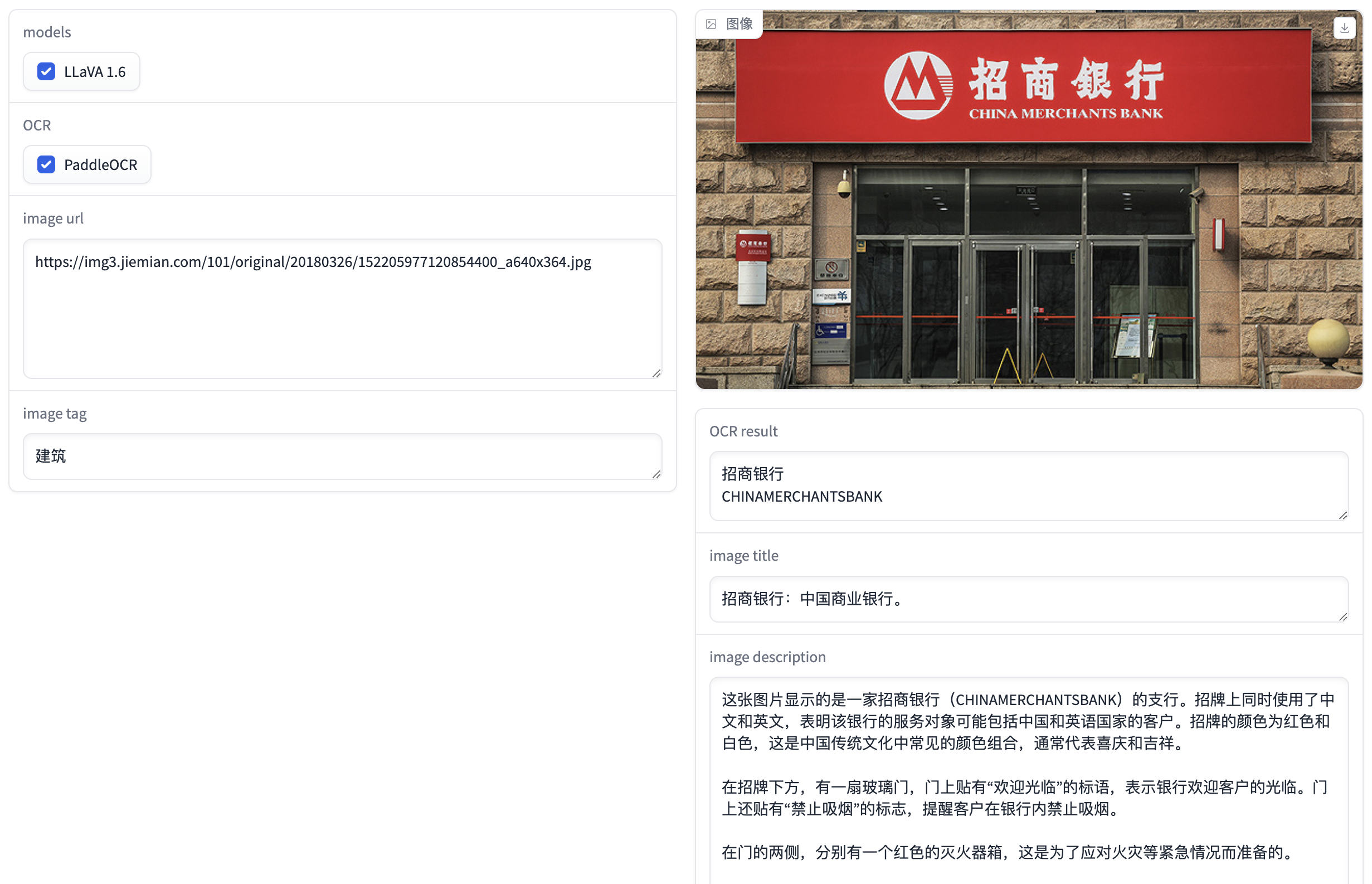
图片内容描述为:
这张图片显示的是一家招商银行(CHINAMERCHANTSBANK)的支行。招牌上同时使用了中文和英文,表明该银行的服务对象可能包括中国和英语国家的客户。招牌的颜色为红色和白色,这是中国传统文化中常见的颜色组合,通常代表喜庆和吉祥。\n\n在招牌下方,有一扇玻璃门,门上贴有“欢迎光临”的标语,表示银行欢迎客户的光临。门上还贴有“禁止吸烟”的标志,提醒客户在银行内禁止吸烟。\n\n在门的两侧,分别有一个红色的灭火器箱,这是为了应对火灾等紧急情况而准备的。\n\n在门前的台阶上,有一个黄色的小桌子和一把椅子,可能是供客户休息或等待使用。\n\n总的来说,这张图片展示了一个典型的银行支行外观,体现了银行的欢迎态度和为客户提供服务的理念。
分析: 使用OCR模型后,能很好地理解图片中的建筑为招商银行,而不使用OCR模型则无法理解这张图片是哪家银行。
未使用OCR模型,仅使用多模态模型的效果:
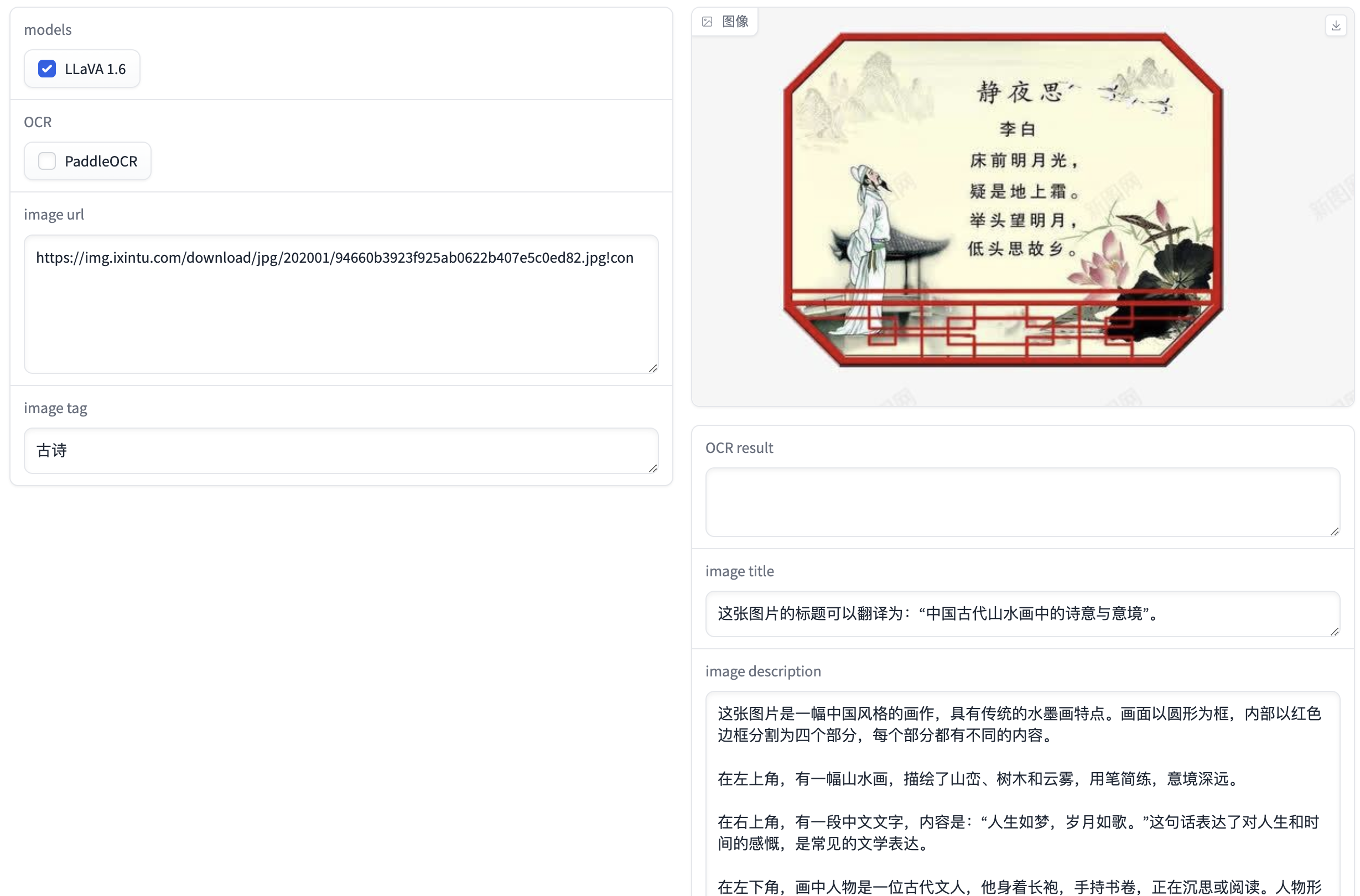
图片内容描述为:
这张图片是一幅中国风格的画作,具有传统的水墨画特点。画面以圆形为框,内部以红色边框分割为四个部分,每个部分都有不同的内容。\n\n在左上角,有一幅山水画,描绘了山峦、树木和云雾,用笔简练,意境深远。\n\n在右上角,有一段中文文字,内容是:“人生如梦,岁月如歌。”这句话表达了对人生和时间的感慨,是常见的文学表达。\n\n在左下角,画中人物是一位古代文人,他身着长袍,手持书卷,正在沉思或阅读。人物形象生动,姿态悠闲,体现了文人的风雅。\n\n在右下角,画中有一株盛开的花朵,花朵鲜艳,花瓣舒展,旁边还有一只蝴蝶在飞舞,寓意着生命的美好和短暂。\n\n整个画面以红色边框为界,将四个部分巧妙地组合在一起,形成了一个完整的圆形构图。这种构图方式在中国传统绘画中非常常见,寓意着“圆满”和“完美”。
使用OCR模型来增强多模态模型的效果:

图片内容描述为:
这张图片是一幅中国画,描绘了唐代诗人李白的著名诗作《静夜思》的意境。画面以圆形构图,四周有红色边框,给人一种古典、庄重的感觉。\n\n画面中央,一位身穿白色长袍的男子正站在一棵高大的树下,抬头仰望天空。他的表情凝重,似乎在沉思。男子周围是一些花草,其中有一朵盛开的花朵,颜色鲜艳,为画面增添了一丝生机。\n\n画面下方,有一行黑色的文字,正是李白的《静夜思》。这首诗以简洁的语言,表达了诗人对故乡的思念之情。\n\n整幅画作以淡雅的色彩为主,营造出一种宁静、幽雅的氛围,与诗中所表达的情感相得益彰。画面中的男子、树木、花朵等元素,以及诗中的文字,共同构成了一幅充满诗意的画卷。
分析:未加入OCR模型前,LLaVA模型基本无法理解图片中的内容,它产生了幻觉,给出了与图片不相符的内容描述。而加入OCR模型后,LLaVA模型能较好地理解图片内容,给出了静夜思古诗相关的描述,符合图片内容。
事实证明,在使用多模态模型进行图片内容理解时,在某些场景下加入OCR识别结果可有效提升模型的图片理解能力。
以文搜图
以文搜图的实现方案为:对于用于输入的query,使用ES的检索功能,对图片内容字段进行搜索,得到匹配的图片。
- 单个短语
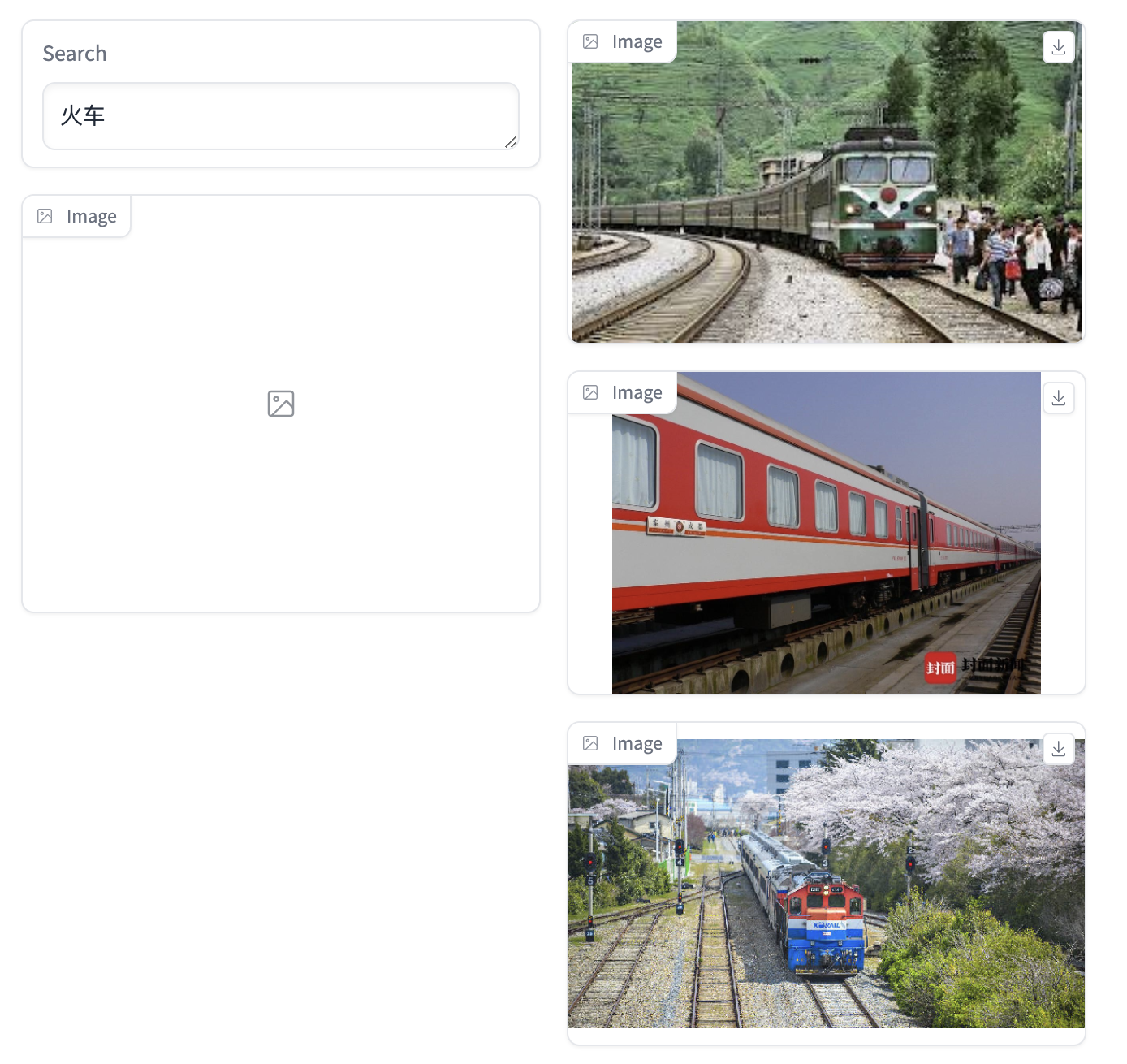
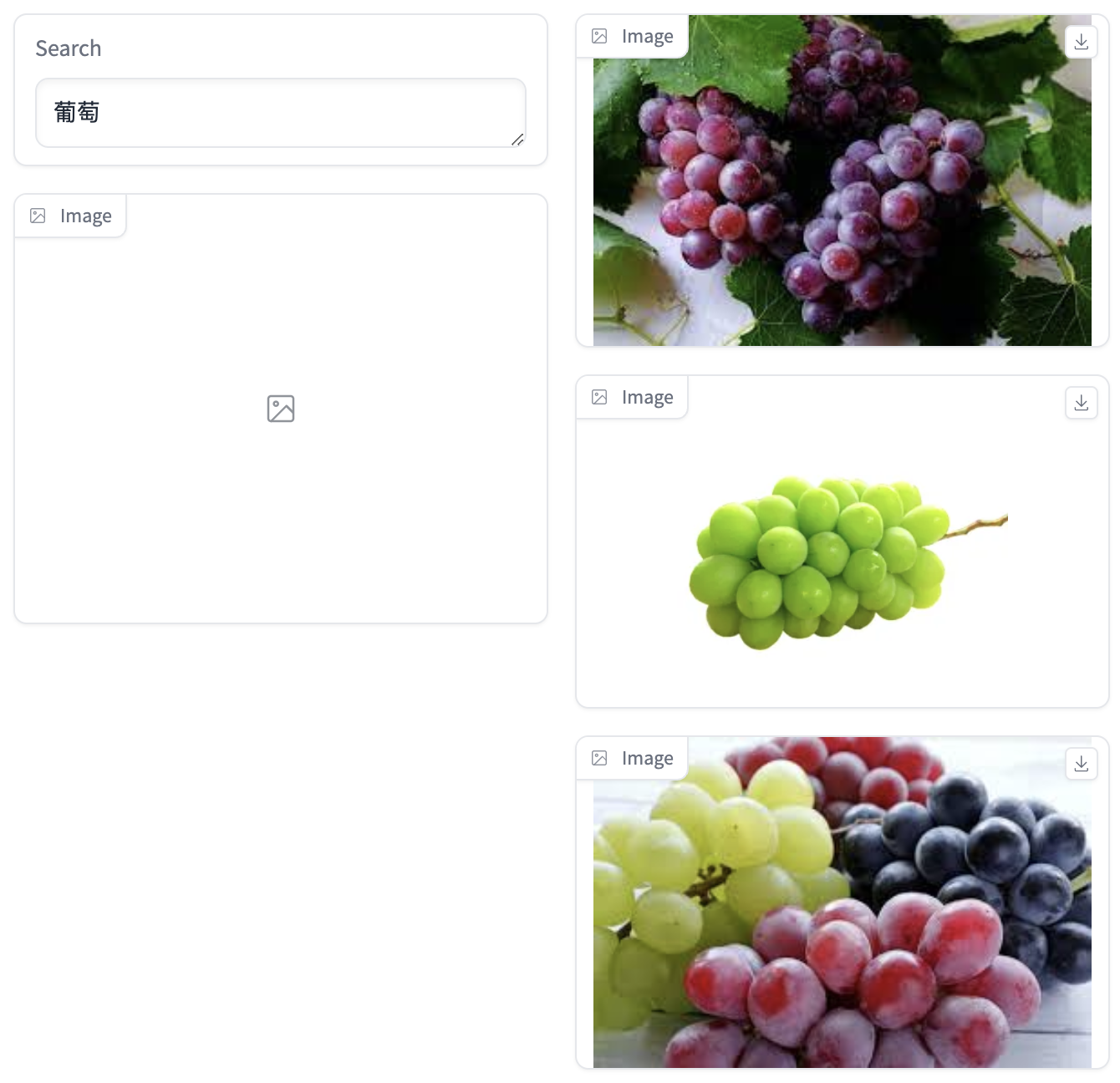
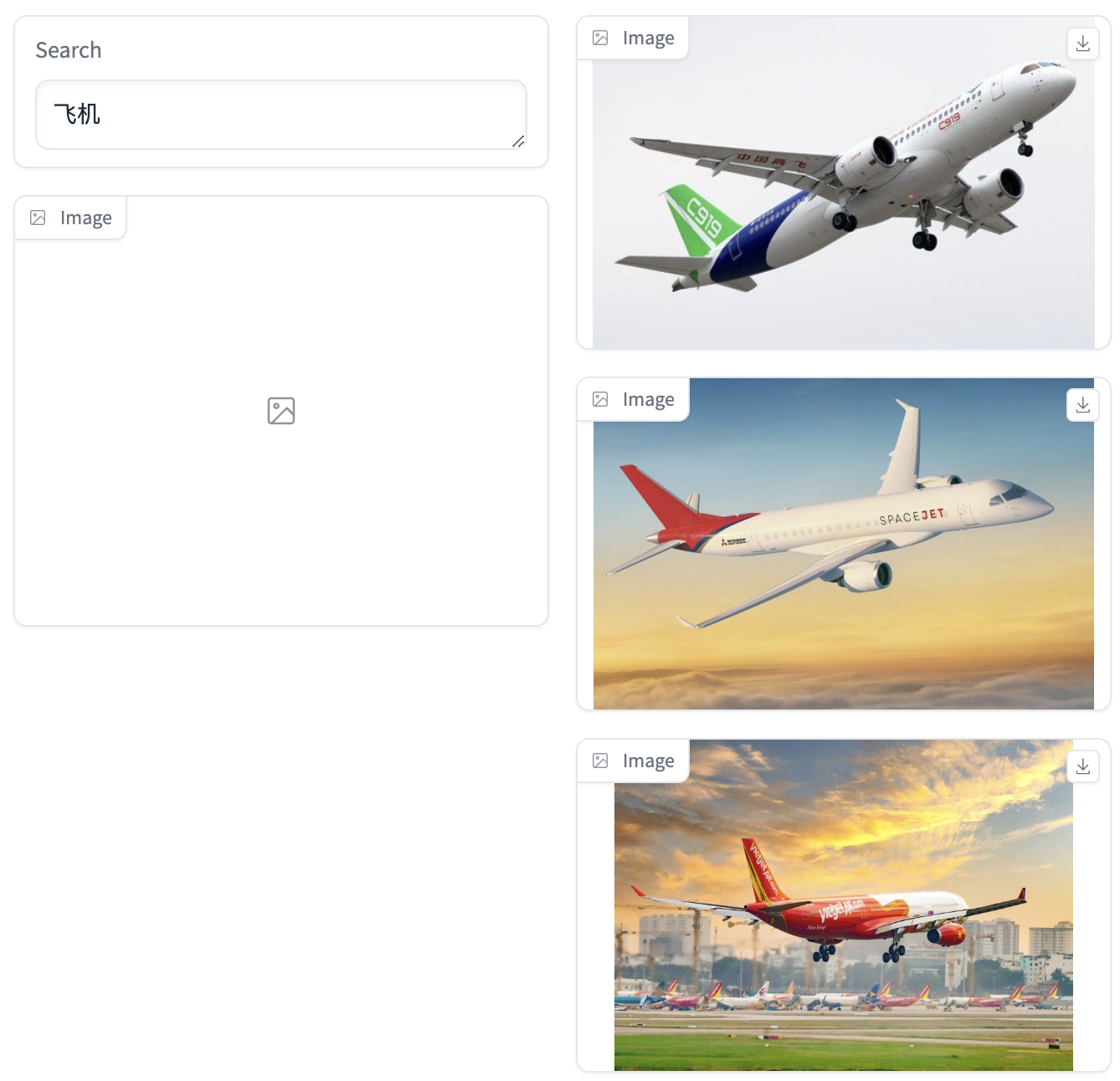
- 多个短语
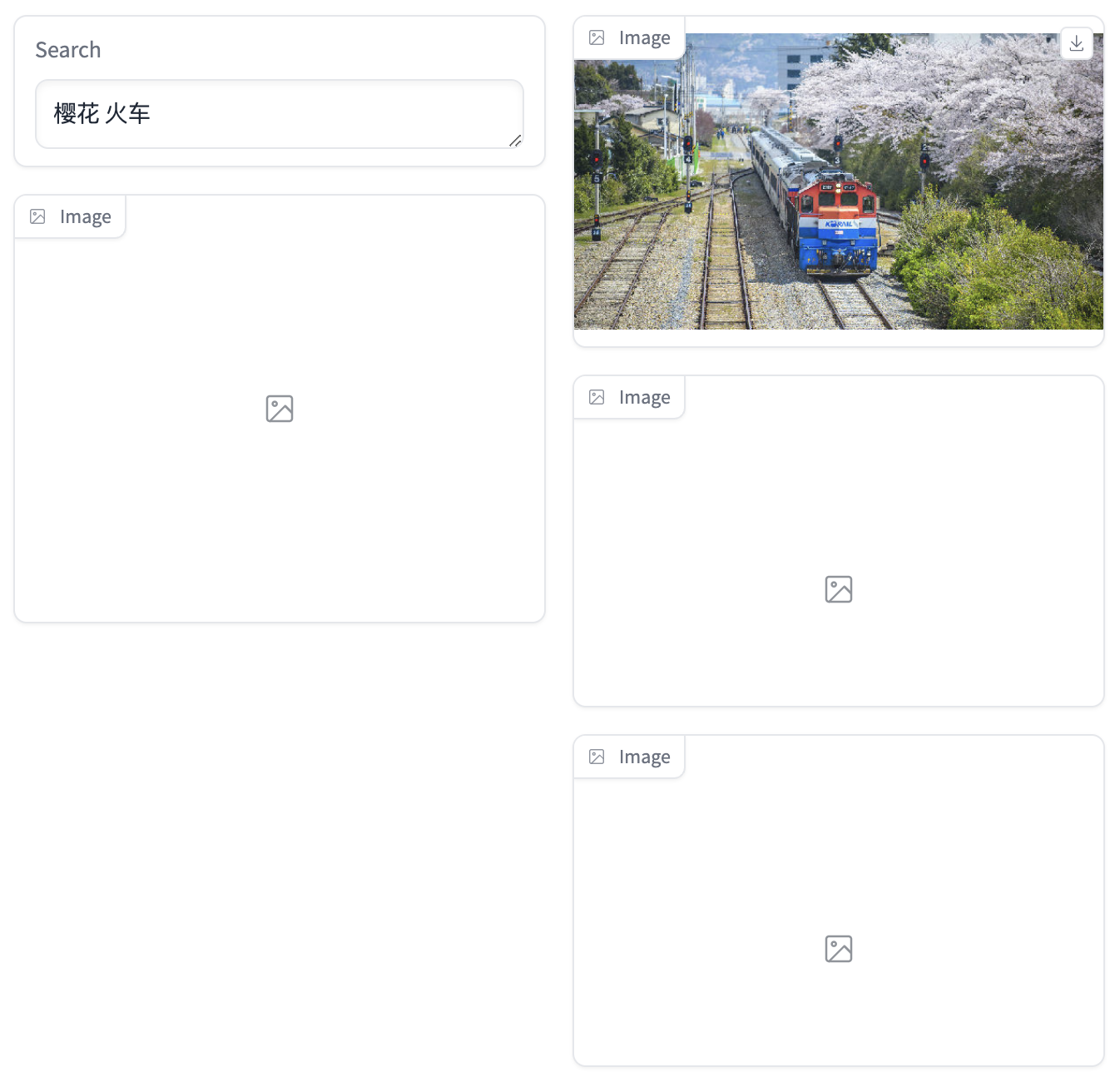
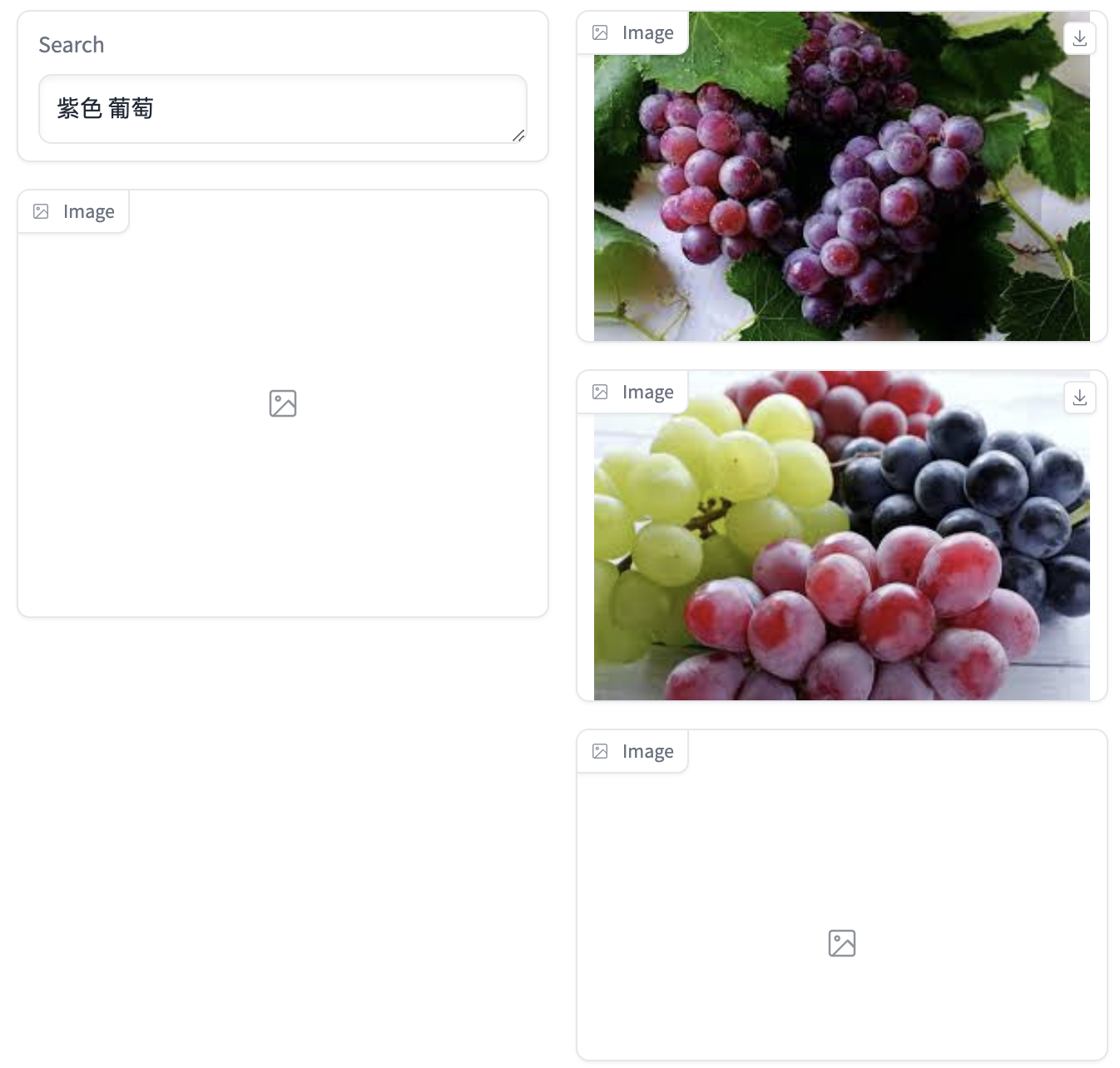
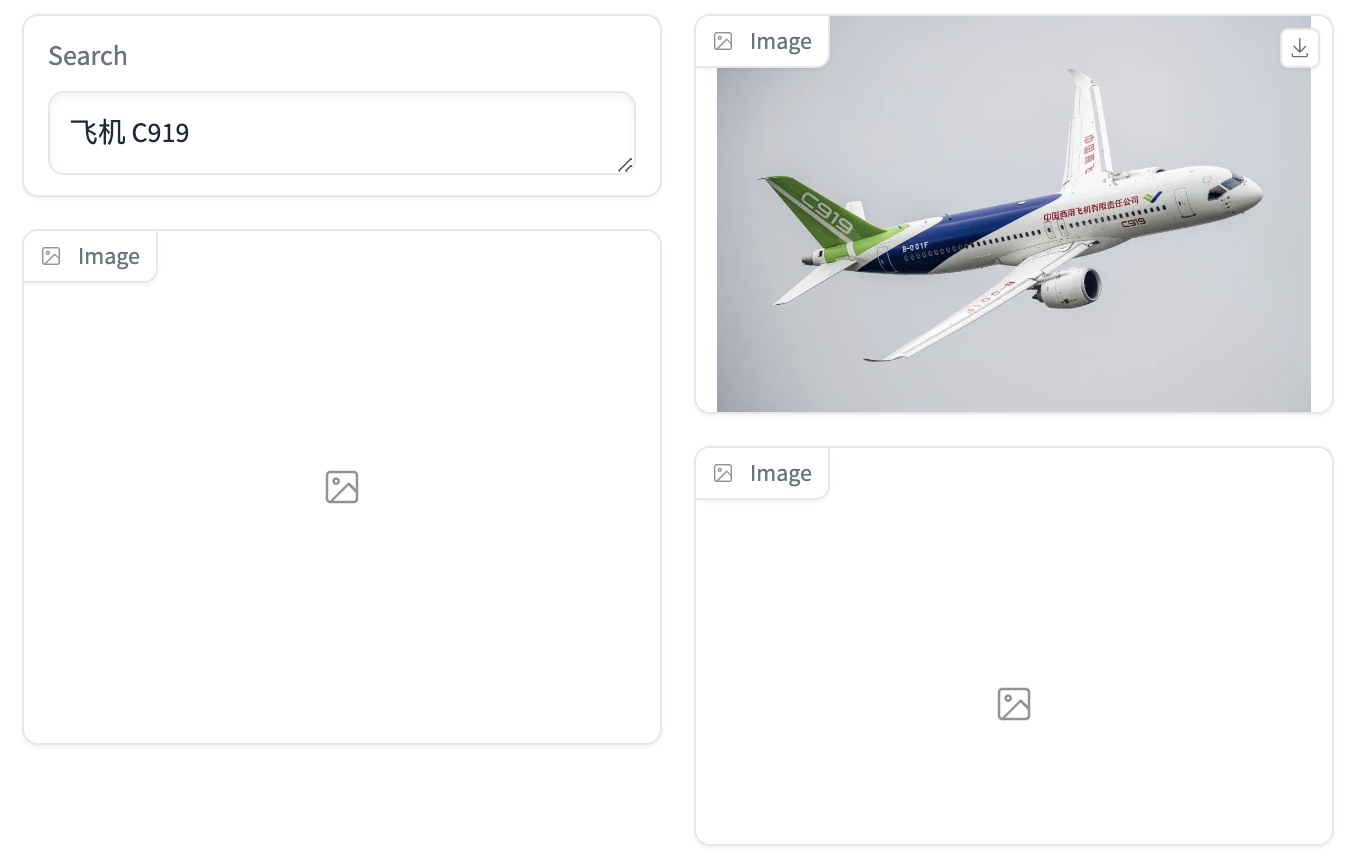
以图搜图
以图搜图的实现方案为:使用多模态模型(未加入OCR模型)获取用户输入图片网址的标题和内容描述,使用ES对图片内容进行初筛,再使用ReReank模型对粗筛结果进行重排,得到ES数据库中的相似图片。
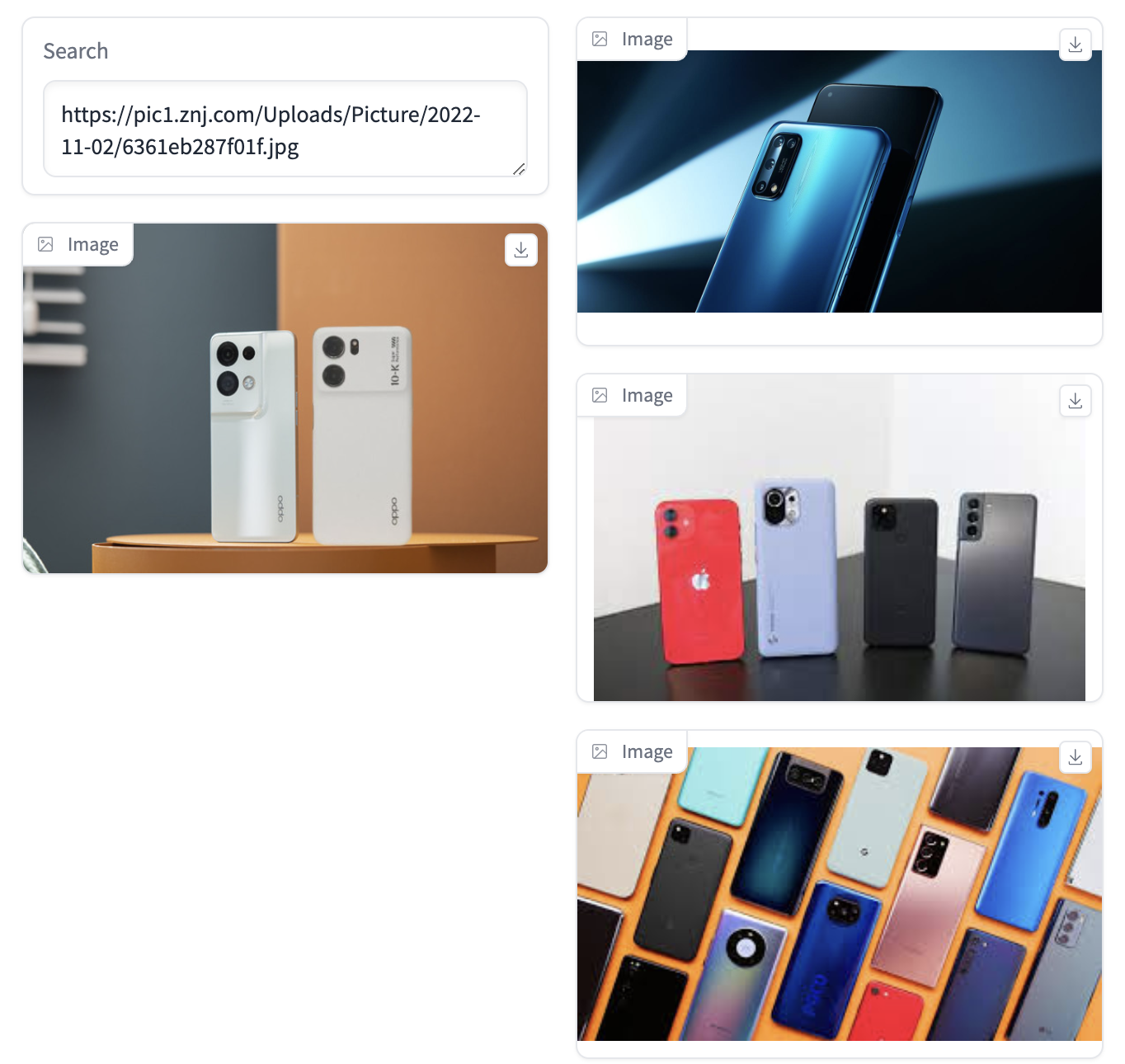
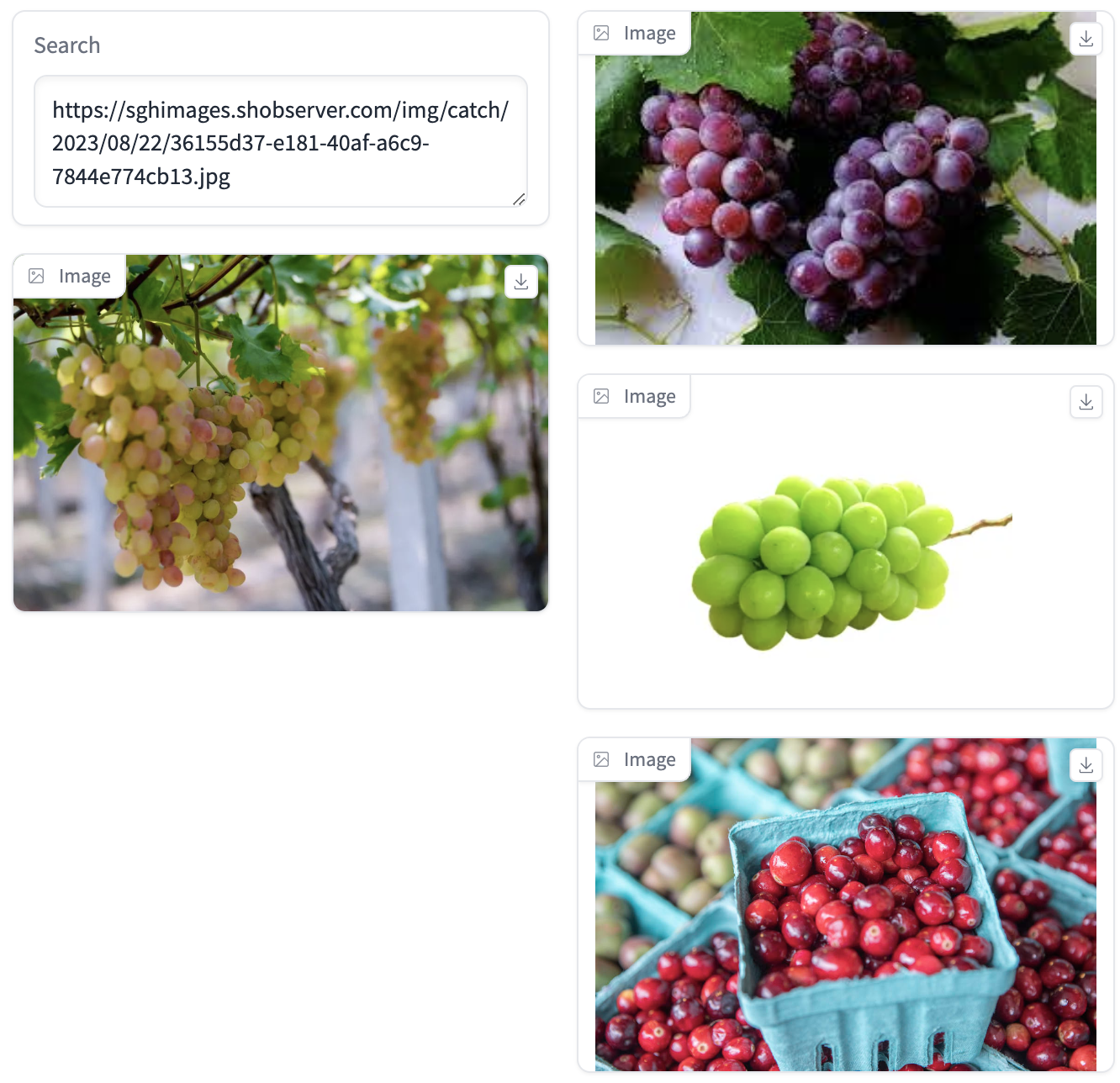
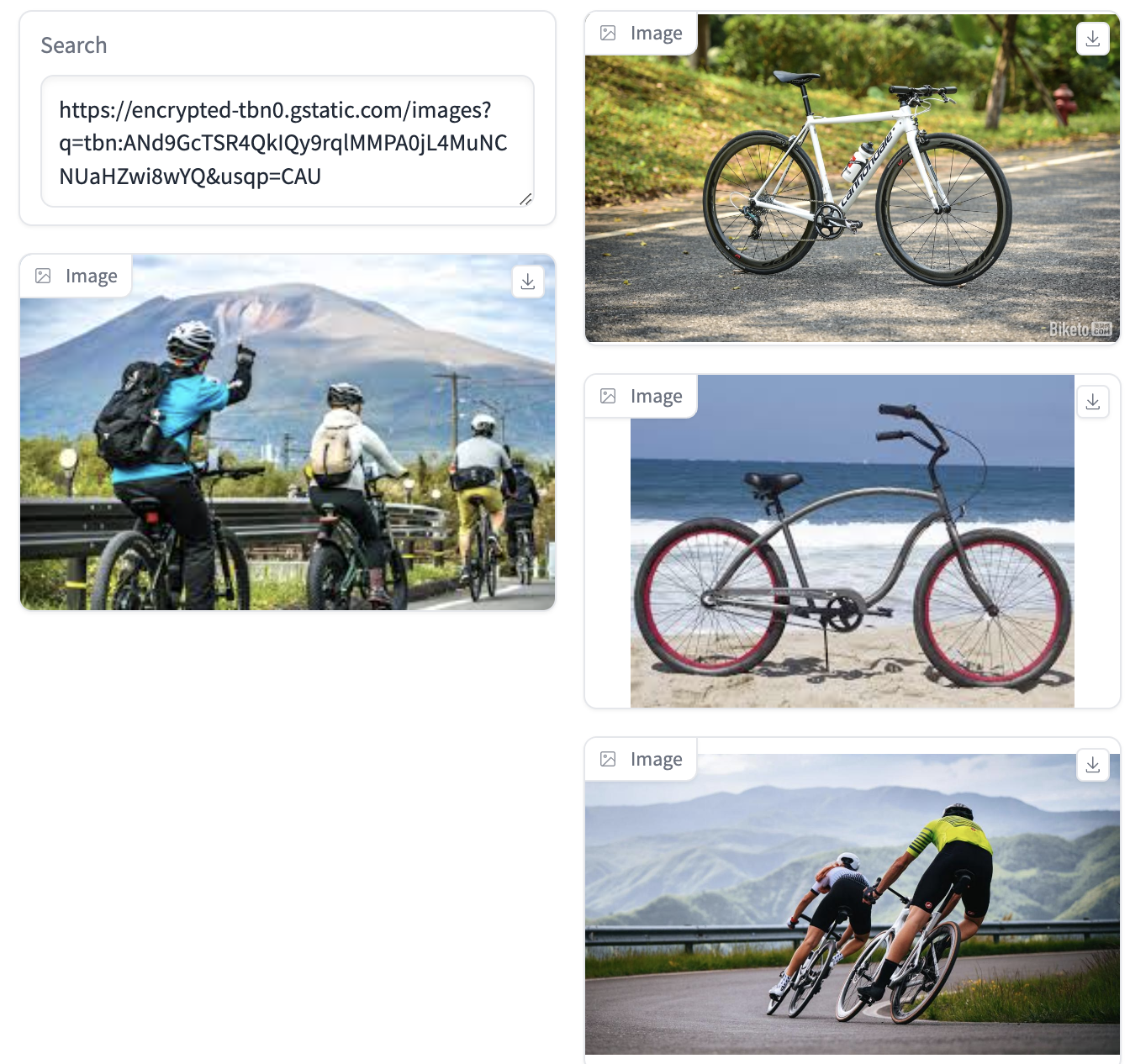
总结
本文主要介绍了如何使用多模态模型来实现以文搜图和以图搜图功能。本文是笔者使用LLaVA-1.6模型的一次尝试,事实上,以文搜图和以图搜图功能会有更好有优雅的实现技术方案。
本文的代码已公开至Github,网址为:https://github.com/percent4/multi-modal-image-search .
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
