本文将会介绍在RAG框架中的Retrieve阶段,不同Embedding模型的召回效果对比,以及如何对Embedding模型进行微调,提升召回效果。
在文章NLP(八十二)RAG框架中的Retrieve算法评估 ,笔者基于自己构建的数据集,在RAG框架的Retrieve阶段中,对不同的Retrieve算法进行了评估。对于单一的召回算法,笔者在向量召回时使用OpenAI
Embedding模型,得到的评估指标如下:
embedding_top_1_eval
0.6075
0.6075
embedding_top_2_eval
0.6978
0.6526
embedding_top_3_eval
0.7321
0.6641
embedding_top_4_eval
0.7788
0.6758
embedding_top_5_eval
0.7944
0.6789
在此基础上,我们加入BAAI开源的BGE Embedding模型:
BAAI/bge-base-zh-v1.5
BAAI/bge-large-zh-v1.5
首先,我们会分析这两个Embedding模型的召回指标。之后,再对这两个Embedding模型进行微调,看看微调后的召回指标是否有提升。
Embedding模型对比
BGE Embedding模型的部署方式是简单的,结合FastAPI,笔者部署的Web服务的Python代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import uvicornfrom fastapi import FastAPIfrom pydantic import BaseModelfrom sentence_transformers import SentenceTransformer'BAAI/bge-large-zh-v1.5' )class Sentence (BaseModel ):str @app.get('/' def home ():return 'hello world' @app.post('/embedding' def get_embedding (sentence: Sentence ):True ).tolist()return {"text" : sentence.text, "embedding" : embedding}if __name__ == '__main__' :'0.0.0.0' , port=50072 )
与OpenAI Embedding的做法一样,我们借助部署好的Web服务,对query和Documents得到离线向量文件,然后借助向量相似度进行召回。BGE
Embedding模型的召回指标如下:
embedding_top_1_eval
0.6044
0.6044
embedding_top_2_eval
0.7072
0.6558
embedding_top_3_eval
0.7539
0.6713
embedding_top_4_eval
0.7913
0.6807
embedding_top_5_eval
0.81
0.6844
embedding_top_1_eval
0.5919
0.5919
embedding_top_2_eval
0.7134
0.6526
embedding_top_3_eval
0.7726
0.6724
embedding_top_4_eval
0.7944
0.6778
embedding_top_5_eval
0.8224
0.6834
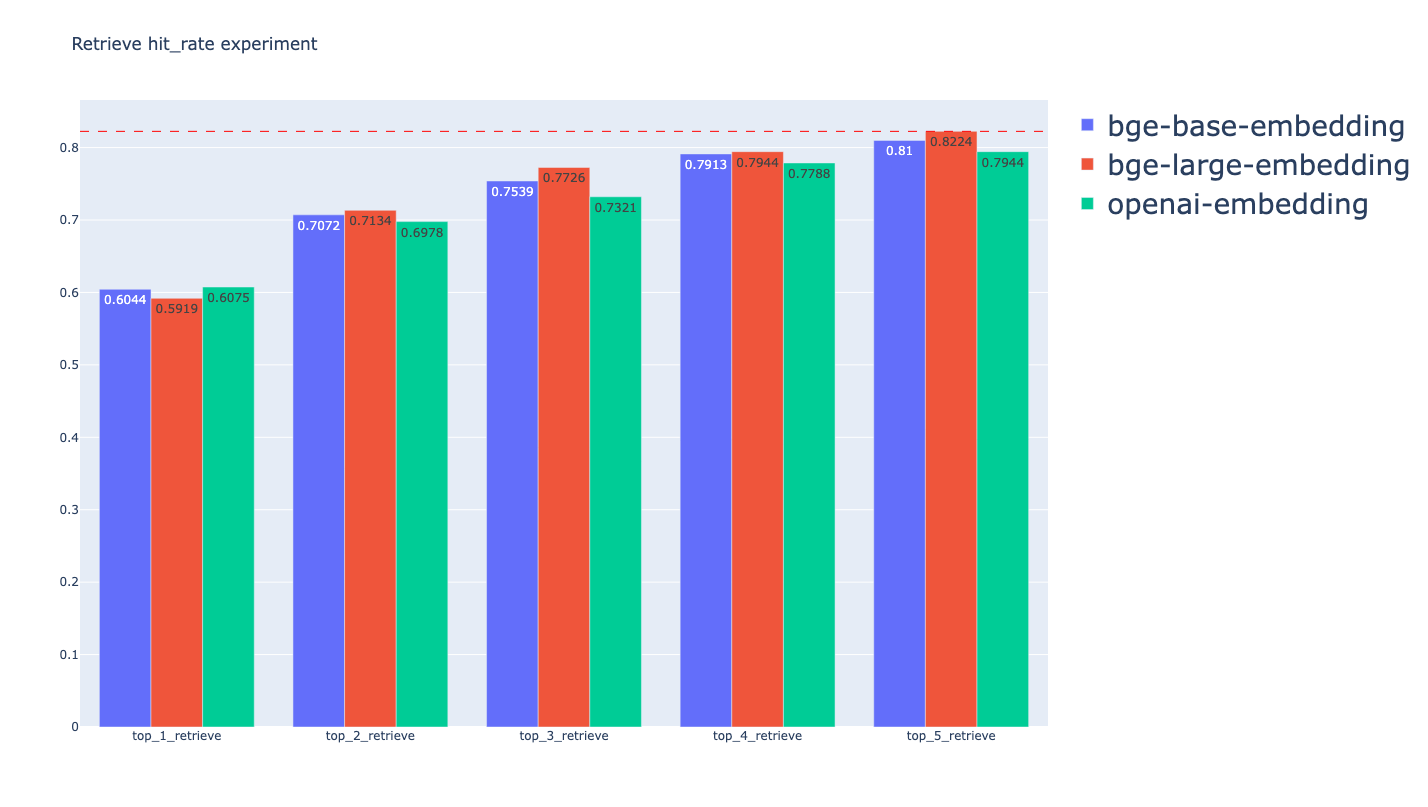
不同Embedding模型的召回效果对比
从中可以看到BGE Embedding模型的召回效果比OpenAI
Embedding模型会好一些,但提升不大。
Embedding模型微调
接下来,我们借助Embedding模型的微调,看看微调后的召回效果。
Embedding模型的微调效果,依赖于我们微调训练的数据集。由于笔者构建的评估数据集是日本半导体行业相关的数据,因此,微调训练数据集选择了半导体行业相关的数据,共129个训练样本。
使用Llama-Index模块对Embedding模型进行微调,Python脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import jsonfrom llama_index import SimpleDirectoryReaderfrom llama_index.node_parser import SentenceSplitterfrom llama_index.schema import MetadataMode"train.txt" ]"test.txt" ]"train_corpus.json" "val_corpus.json" def load_corpus (files, verbose=False ):if verbose:print (f"Loading files {files} " )if verbose:print (f"Loaded {len (docs)} docs" )250 , chunk_overlap=0 )if verbose:print (f"Parsed {len (nodes)} nodes" )return nodesTrue )True )from llama_index.finetuning import (from llama_index.llms import OpenAIimport os"OPENAI_API_KEY" ] = "sk-xxx" "gpt-3.5-turbo" )"""\ Context information is below. --------------------- {context_str} --------------------- Given the context information and not prior knowledge. generate only questions based on the below query. You are a Professor. Your task is to setup \ {num_questions_per_chunk} questions for an upcoming \ quiz/examination in Chinese. The questions should be diverse in nature \ across the document in Chinese. The questions should not contain options, not start with Q1/ Q2. \ Restrict the questions to the context information provided. """ 1 , qa_generate_prompt_tmpl=qa_generate_prompt_tmpl)1 , qa_generate_prompt_tmpl=qa_generate_prompt_tmpl)"train_dataset.json" )"val_dataset.json" )from llama_index.finetuning import SentenceTransformersFinetuneEngine"./models/bge-base-zh-v1.5" ,"./models/bge-base-ft-001" ,
对上述两个Embedding模型进行微调,并使用Embedding
Retrieve进行召回,指标如下:
BGE base Embedding Finetune
embedding_top_1_eval
0.729
0.729
embedding_top_2_eval
0.8598
0.7944
embedding_top_3_eval
0.9003
0.8079
embedding_top_4_eval
0.9065
0.8094
embedding_top_5_eval
0.9159
0.8113
BGE large Embedding Finetune
embedding_top_1_eval
0.757
0.757
embedding_top_2_eval
0.8816
0.8193
embedding_top_3_eval
0.919
0.8318
embedding_top_4_eval
0.9377
0.8364
embedding_top_5_eval
0.9377
0.8364
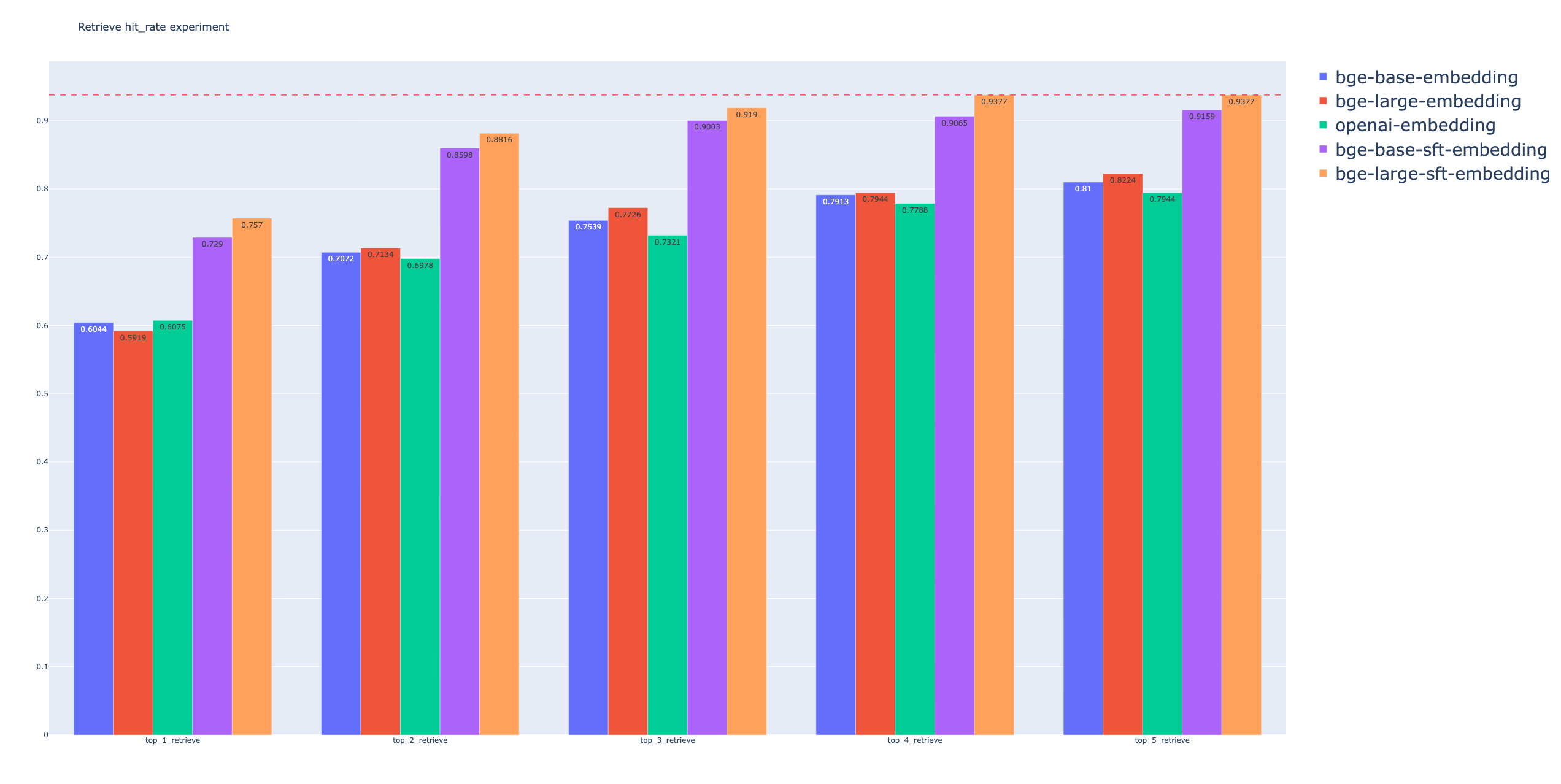
不同Embedding模型之间的Hit
Rate比较
可以看到,微调的Embedding模型的召回效果有了大幅度的提升,在本次实验中,提升点在10%左右。
总结
本文主要介绍了在RAG框架中的Retrieve阶段,不同Embedding模型的召回效果对比,以及如何对Embedding模型进行微调,提升召回效果。
本文的结论是,对Embedding模型进行微调后,可以有效提升模型的召回效果,这无疑是RAG框架中的一种有效优化手段。
本文代码及数据已开源至Github: https://github.com/percent4/embedding_rerank_retrieval 。
感谢阅读~
推荐阅读
NLP(八十二)RAG框架中的Retrieve算法评估 NLP(八十三)RAG框架中的Rerank算法评估 NLP(八十四)RAG框架中的召回算法可视化分析及提升方法 Llama-Index Finetune Embeddings: https://docs.llamaindex.ai/en/stable/examples/finetuning/embeddings/finetune_embedding.html
欢迎关注我的公众号NLP奇幻之旅 ,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅 ”,笔者正在努力构建自己的技术社区。