NLP(八十四)RAG框架中的召回算法可视化分析及提升方法
本文将会对笔者之前在RAG框架中的Retrieve算法的不同召回手段进行可视化分析,并介绍RAG框架中的优化方法。
在文章NLP(八十二)RAG框架中的Retrieve算法评估中笔者介绍了RAG框架中不同的Retrieve算法(包括BM25, Embedding, Ensemble, Ensemble+Rerank)的评估实验,并给出了详细的数据集与评测过程、评估结果。
在文章NLP(八十三)RAG框架中的Rerank算法评估中笔者进一步介绍了Rerank算法在RAG框架中的作用,并对不同的Rerank算法进行了评估。
以上两篇文章是笔者对RAG框架的深入探索,文章获得了读者的一致好评。
本文将会继续深入RAG框架的探索,内容如下:
- Retrieve算法的可视化分析:使用Gradio模块搭建可视化页面用于展示不同召回算法的结果。
- BM25, Embedding, Ensemble, Ensemble + Rerank召回分析:结合具体事例,给出不同召回手段的结果,比较它们的优劣。
- RAG框架中的提升方法:主要介绍Query Rewirte, HyDE.
Retrieve算法的可视化分析
为了对Retrieve算法的召回结果进行分析,笔者使用Gradio模块来开发前端页面以支持召回结果的可视化分析。
Python代码如下:
1 | |
该页面可以选择召回算法,top_k参数,以及query,返回召回算法的指标及top_k召回文本,如下图:
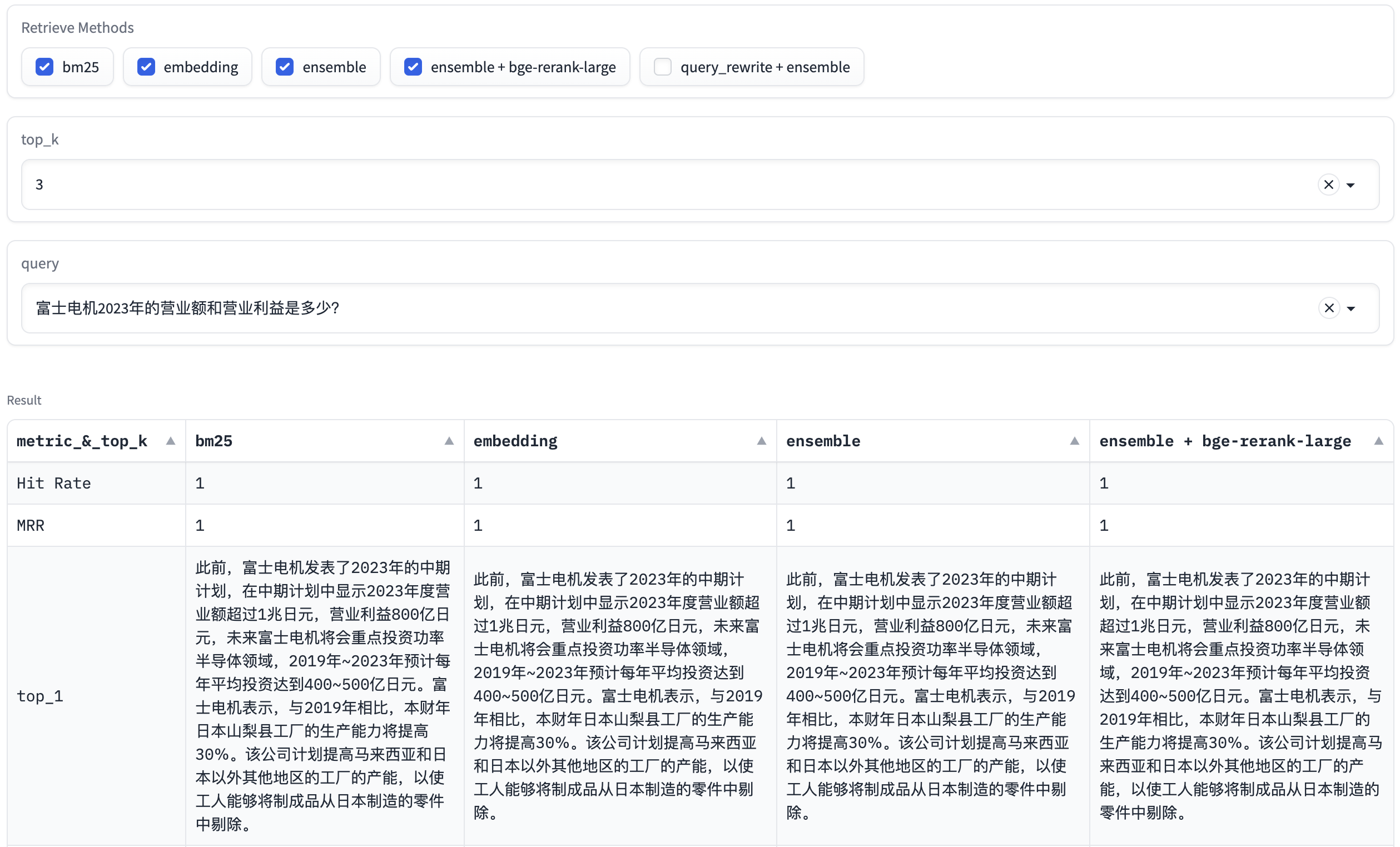
有了这个页面,我们可以很方便地对召回结果进行分析。为了有更全面的分析,我们再使用Python脚本,对测试query不同召回算法(BM25, Embedding, Ensemble)的top_3召回结果及指标进行记录。
当然,我们还筛选出badcase,用来帮助我们更好地对召回算法进行分析。所谓badcase,指的是query的top_3召回指标在BM25, Embedding, Ensemble算法上都为0。badcase如下:
| query |
|---|
| 日美半导体协议对日本半导体产业有何影响? |
| 请列举三个美国的科技公司。 |
| 日本半导体发展史的三个时期是什么? |
| 日美半导体协议要求美国芯片在日本市场份额是多少? |
| 日本在全球半导体市场的份额是多少? |
| 日本半导体设备在国内市场的占比是多少? |
| 日本企业在全球半导体产业的地位如何? |
| 美日半导体协议的主要内容是什么? |
| 尼康和佳能的光刻机在哪个市场占优势? |
| 美日半导体协议是由哪两部门签署的? |
| 日本在全球半导体材料行业的地位如何? |
| 日本半导体业的衰落原因是什么? |
| 日本半导体业的兴衰原因是什么? |
| 日本半导体企业如何保持竞争力? |
| 日本半导体产业在哪些方面仍有影响力? |
| 半导体制造设备市场美、日、荷各占多少份额? |
| 80年代日本半导体企业的问题是什么? |
| 尼康在哪种技术上失去了优势? |
不同召回算法实例分析
在文章NLP(八十二)RAG框架中的Retrieve算法评估中,在评估实验中,对于单个的Retrieve算法,BM25表现要优于Embedding。但事实上,两者各有优劣。
| 检索类型 | 优点 | 缺点 |
|---|---|---|
| 向量检索 (Embedding) | 1. 语义理解更强。 2. 能有效处理模糊或间接的查询。 3. 对自然语言的多样性适应性强。 4. 能识别不同词汇的相同意义。 |
1. 计算和存储成本高。 2. 索引时间较长。 3. 高度依赖训练数据的质量和数量。 4. 结果解释性较差。 |
| 关键词检索 (BM25) | 1. 检索速度快。 2. 实现简单,资源需求低。 3. 结果易于理解,可解释性强。 4. 对精确查询表现良好。 |
1. 对复杂语义理解有限。 2. 对查询变化敏感,灵活性差。 3. 难以处理同义词和多义词。 4. 需要用户准确使用关键词。 |
向量检索(Embedding)的优势:
- 复杂语义的文本查找(基于文本相似度)
- 相近语义理解(如老鼠/捕鼠器/奶酪,谷歌/必应/搜索引擎)
- 多语言理解(跨语言理解,如输入中文匹配英文)
- 多模态理解(支持文本、图像、音视频等的相似匹配)
- 容错性(处理拼写错误、模糊的描述)
虽然向量检索在以上情景中具有明显优势,但有某些情况效果不佳。比如:
- 搜索一个人或物体的名字(例如,伊隆·马斯克,iPhone 15)
- 搜索缩写词或短语(例如,RAG,RLHF)
- 搜索 ID(例如,gpt-3.5-turbo,titan-xlarge-v1.01)
而上面这些的缺点恰恰都是传统关键词搜索的优势所在,传统关键词搜索(BM25)擅长:
精确匹配(如产品名称、姓名、产品编号)
少量字符的匹配(通过少量字符进行向量检索时效果非常不好,但很多用户恰恰习惯只输入几个关键词)
倾向低频词汇的匹配(低频词汇往往承载了语言中的重要意义,比如“你想跟我去喝咖啡吗?”这句话中的分词,“喝”“咖啡”会比“你”“吗”在句子中承载更重要的含义)
基于向量检索和关键词搜索更有优劣,因此才需要混合搜索(Ensemble)。而在混合搜索的基础上,需要对多路召回结果进行精排(即Rerank),重新调整召回文本的顺序。
为了更好地理解上述召回算法的优缺点,下面结合具体的实例来进行阐述。
query: "NEDO"的全称是什么?

在这个例子中,Embedding召回结果优于BM25,BM25召回结果虽然在top_3结果中存在,但排名第三,排在首位的是不相关的文本,而Embedding由于文本相似度的优势,将正确结果放在了首位。
query: 日本半导体产品的主要应用领域是什么?
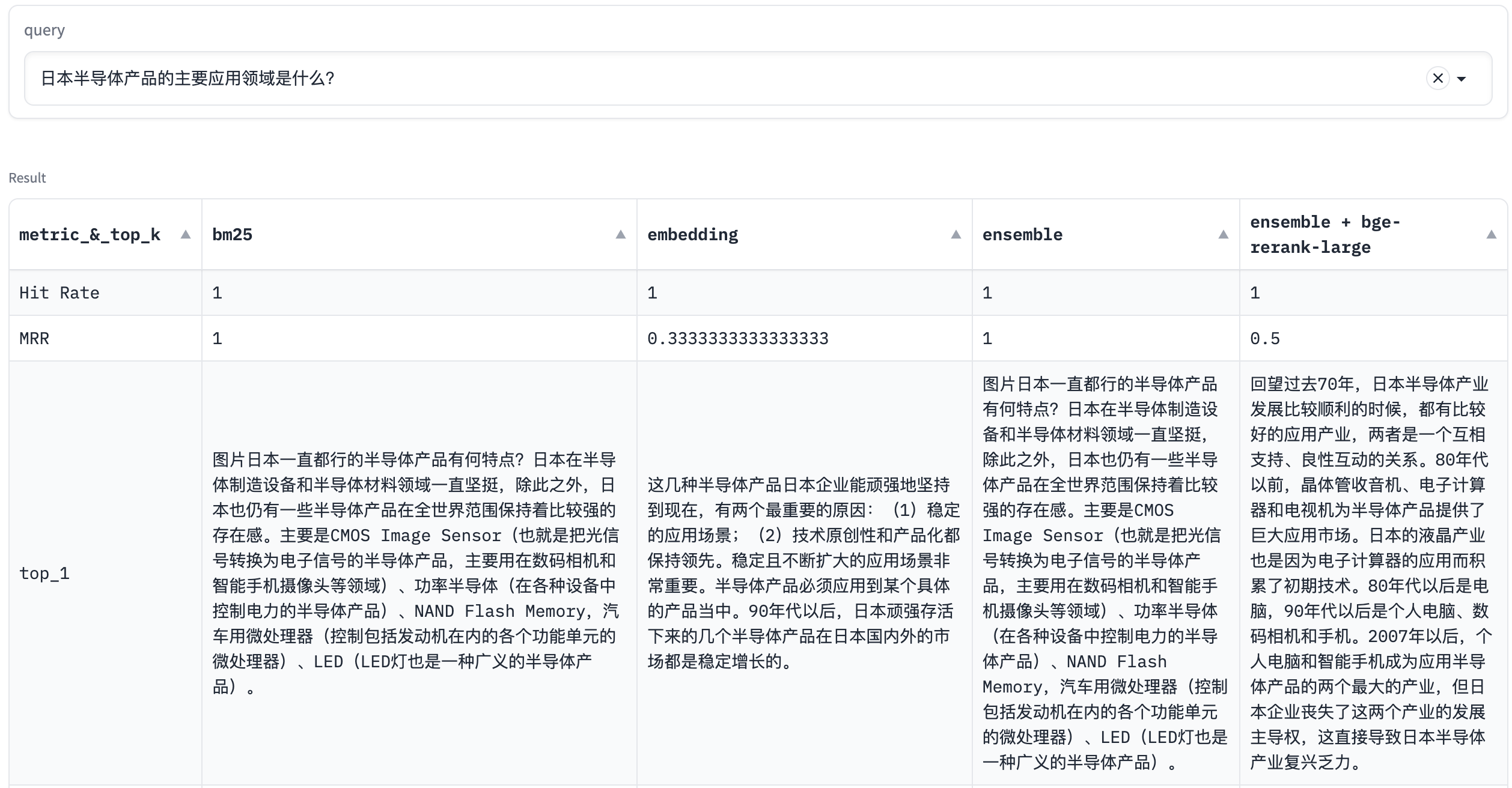
在这个例子中,BM25召回结果优于Embedding。
query: 《美日半导体协议》对日本半导体市场有何影响?
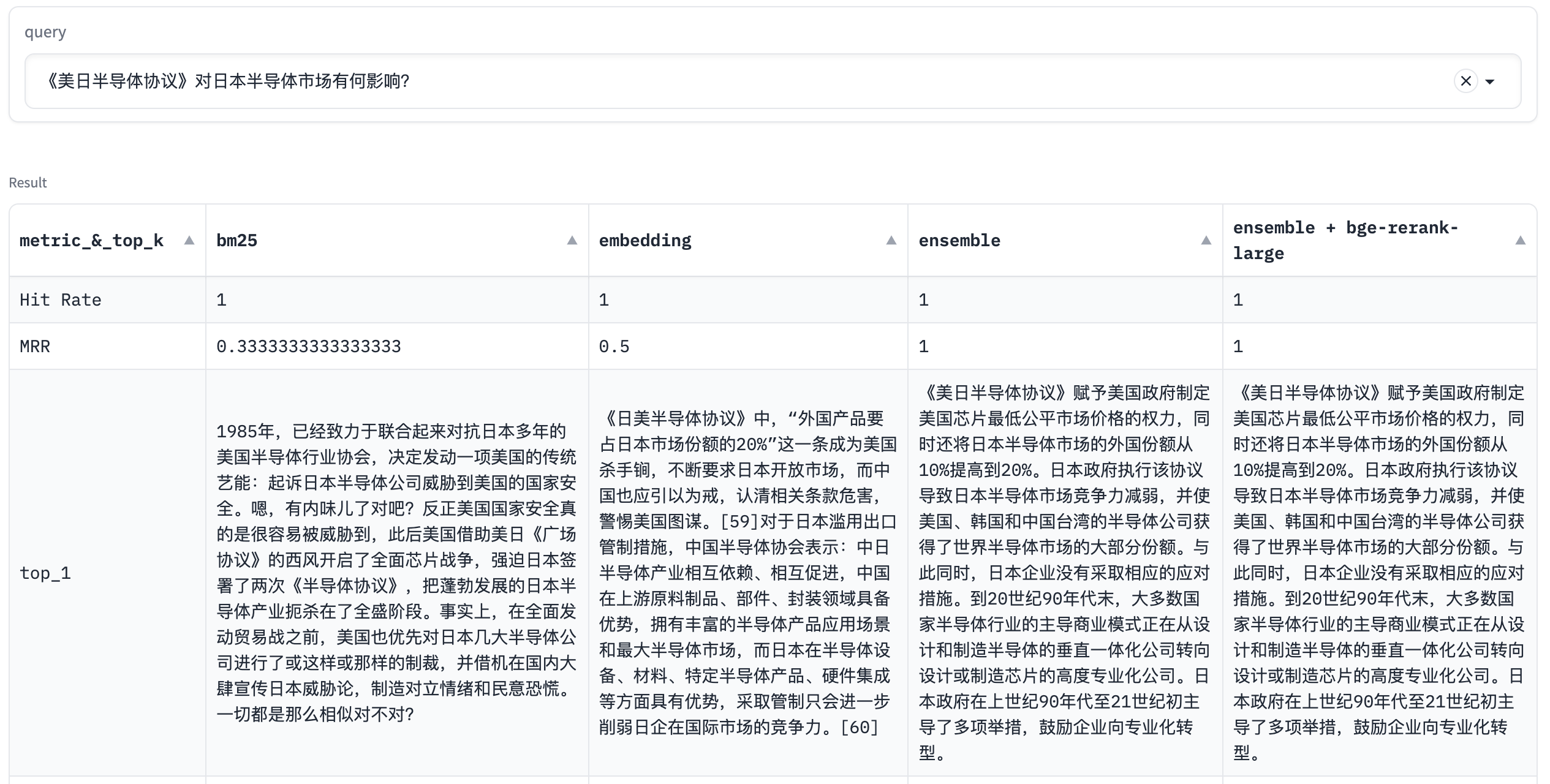
在这个例子中,正确文本在BM25算法召回结果中排名第二,在Embedding算法中排第三,混合搜索排名第一,这里体现了混合搜索的优越性。
query: 80年代日本电子产业的辉煌表现在哪些方面?
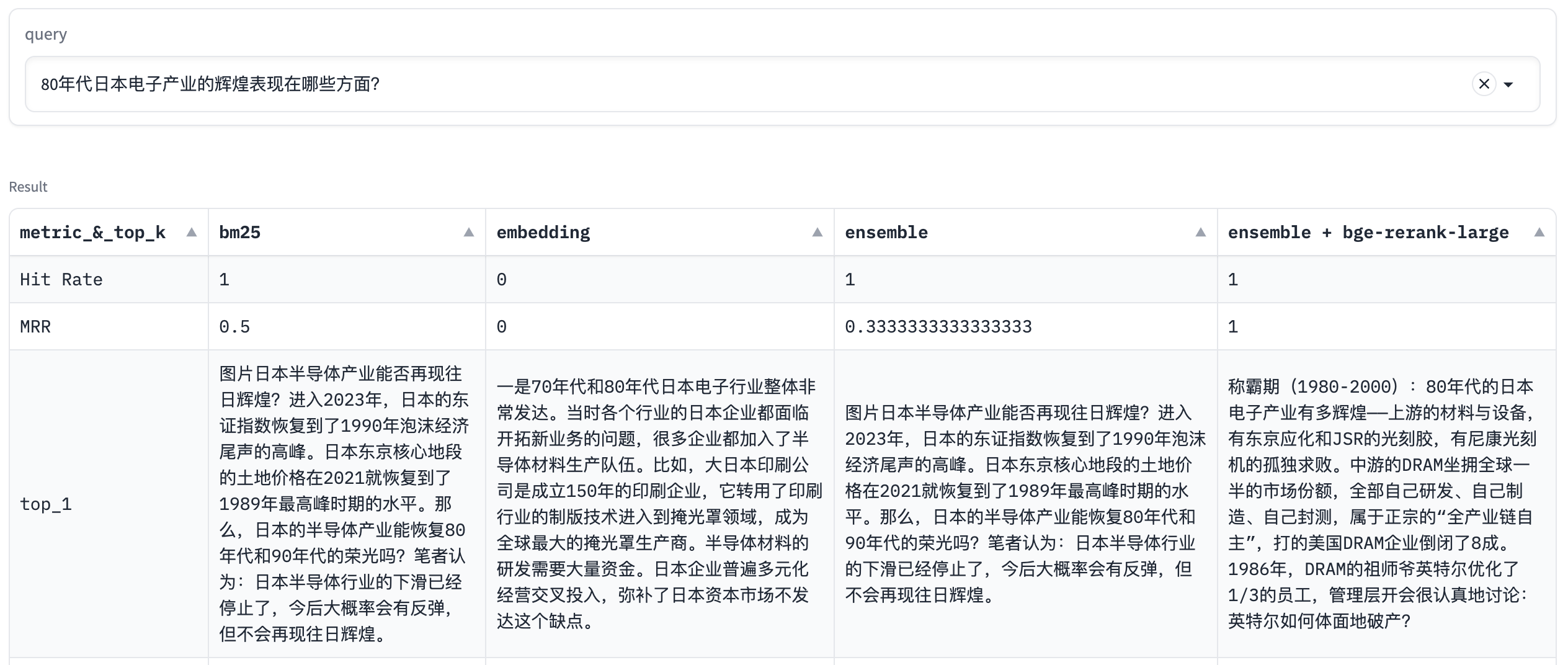
在这个例子中,不管是BM25, Embedding,还是Ensemble,都没能将正确文本排在第一位,而经过Rerank以后,正确文本排在第一位,这里体现了Rerank算法的优势。
RAG中的提升方法
经过上述Retrieve算法的对比,我们对不同的Retrieve算法有了深入的了解。然而,Retrieve算法并不能帮助我们解决所有问题,比如上述的badcase,就是用各种Retrieve算法都无法找回的。
那么,还有其它优化手段吗?在RAG框架中,还存在一系列的优化手段,这在Langchain和Llmma-Index中都给出了各种优化手段。本文将尝试两种优化手段:Query
Rewrite和HyDE.
Query Rewrite
业界对于Query Rewrite,有着相当完善且复杂的流程,因为它对于后续的召回结果有直接影响。本文借助大模型对query进行直接改写,看看是否有召回效果提升。
比如:
- 原始query: 半导体制造设备市场美、日、荷各占多少份额?
- 改写后query:美国、日本和荷兰在半导体制造设备市场的份额分别是多少?
改写后的query在BM25和Embedding的top 3召回结果中都能找到。该query对应的正确文本为:
全球半导体设备制造领域,美国、日本和荷兰控制着全球370亿美元半导体制造设备市场的90%以上。其中,美国的半导体制造设备(SME)产业占全球产量的近50%,日本约占30%,荷兰约占17%%。更具体地,以光刻机为例,EUV光刻工序其实有众多日本厂商的参与,如东京电子生产的EUV涂覆显影设备,占据100%的市场份额,Lasertec Corp.也是全球唯一的测试机制造商。另外还有EUV光刻胶,据南大光电在3月发布的相关报告中披露,全球仅有日本厂商研发出了EUV光刻胶。
从中我们可以看到,在改写后的query中,美国、日本、荷兰这三个词发挥了重要作用,因此,query改写对于含有缩写的query有一定的召回效果改善。
HyDE
HyDE(全称Hypothetical Document Embeddings)是RAG中的一种技术,它基于一个假设:相较于直接查询,通过大语言模型 (LLM) 生成的答案在嵌入空间中可能更为接近。HyDE 首先响应查询生成一个假设性文档(答案),然后将其嵌入,从而提高搜索的效果。
比如:
- 原始query: 美日半导体协议是由哪两部门签署的?
- 加上回答后的query: 美日半导体协议是由哪两部门签署的?美日半导体协议是由美国商务部和日本经济产业省签署的。
加上回答后的query使用BM25算法可以找回正确文本,且排名第一位,而Embedding算法仍无法召回。
正确文本为:
1985年6月,美国半导体产业贸易保护的调子开始升高。美国半导体工业协会向国会递交一份正式的“301条款”文本,要求美国政府制止日本公司的倾销行为。民意调查显示,68%的美国人认为日本是美国最大的威胁。在舆论的引导和半导体工业协会的推动下,美国政府将信息产业定为可以动用国家安全借口进行保护的新兴战略产业,半导体产业成为美日贸易战的焦点。1985年10月,美国商务部出面指控日本公司倾销256K和1M内存。一年后,日本通产省被迫与美国商务部签署第一次《美日半导体协议》。
从中可以看出,大模型的回答是正确的,美国商务部这个关键词发挥了重要作用,因此,HyDE对于特定的query有召回效果提升。
总结
本文结合具体的例子,对于不同的Retrieve算法的效果优劣有了比较清晰的认识,事实上,这也是笔者一直在NLP领域努力的一个方向:简单而深刻。
同时,还介绍了两种RAG框架中的优化方法,或许可以在工作中有应用价值。后续笔者将继续关注RAG框架,欢迎大家关注。
本文代码及数据已开源至Github: https://github.com/percent4/embedding_rerank_retrieval。
参考文献
- NLP(八十二)RAG框架中的Retrieve算法评估
- NLP(八十三)RAG框架中的Rerank算法评估
- 引入混合检索(Hybrid Search)和重排序(Rerank)改进 RAG 系统召回效果: https://mp.weixin.qq.com/s/_Rmafm7tI3JWMNqoqFX_FQ