Datasets库是HuggingFace生态系统中一个重要的数据集库,可用于轻松地访问和共享数据集,这些数据集是关于音频、计算机视觉、以及自然语言处理等领域。Datasets
库可以通过一行来加载一个数据集,并且可以使用 Hugging Face
强大的数据处理方法来快速准备好你的数据集。在 Apache Arrow
格式的支持下,通过 zero-copy read
来处理大型数据集,而没有任何内存限制,从而实现最佳速度和效率。
当需要微调模型的时候,需要对数据集进行以下操作:
数据集加载:下载、加载数据集
数据集预处理:使用Dataset.map() 预处理数据
数据集评估指标:加载和计算指标
可以在HuggingFace官网来搜共享索数据集:https://huggingface.co/datasets
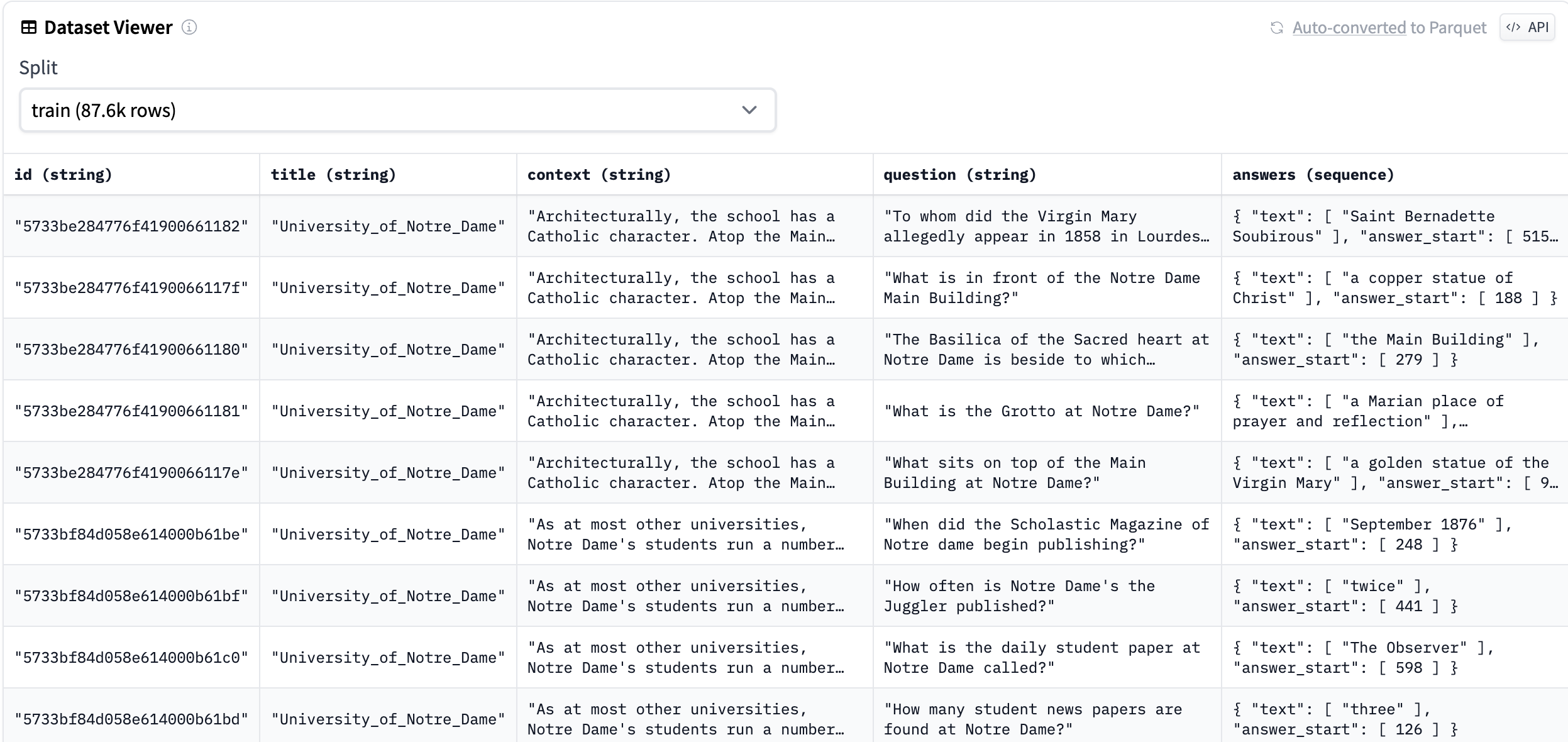
。本文中使用的主要数据集为squad数据集,其在HuggingFace网站上的数据前几行如下:
squad数据集前几行
加载数据
Dataset数据集可以是HuggingFace
Datasets网站上的数据集或者是本地路径对应的数据集,也可以同时加载多个数据集。
以下是加载英语阅读理解数据集squad, 该数据集的网址为:https://huggingface.co/datasets/squad
,也是本文中使用的主要数据集。
1 2 3 4 5 6 import datasets'squad' )'glue' , 'mrpc' )
支持csv, tsv, txt, json, jsonl等格式的文件
1 2 3 4 from datasets import load_dataset"train" : "./data/sougou_mini/train.csv" , "test" : "./data/sougou_mini/test.csv" }"csv" , data_files=data_files, delimiter="," )
1 2 3 4 5 6 7 8 import pandas as pdfrom datasets import Dataset "a" : [1 , 2 , 3 ], "b" : ['A' , 'B' , 'C' ]}
查看数据
数据结构包括:
数据集的划分:train,valid,test数据集
数据集的数量
数据集的feature
squad数据的数据结构如下:
1 2 3 4 5 6 7 8 9 10 DatasetDict({ : Dataset({ : [ 'id', 'title', 'context', 'question', 'answers'] , : 87599 } ): Dataset({ : [ 'id', 'title', 'context', 'question', 'answers'] , : 10570 } )} )
1 2 3 4 5 6 7 8 9 10 11 12 import datasets'squad' )'train' ]range (10 ))42 ).select(range (10 ))10 :20 ]
更多特性
shuffle的功能是打乱datasets中的数据,其中seed是设置打乱的参数,如果设置打乱的seed是相同的,那我们就可以得到一个完全相同的打乱结果,这样用相同的打乱结果才能重复的进行模型试验。
1 2 3 4 5 import datasets'squad' )42 )
stream的功能是将数据集进行流式化,可以不用在下载整个数据集的情况下使用该数据集。这在以下场景中特别有用:
你不想等待整个庞大的数据集下载完毕
数据集大小超过了你计算机的可用硬盘空间
你想快速探索数据集的少数样本
1 2 3 4 from datasets import load_dataset'oscar-corpus/OSCAR-2201' , 'en' , split='train' , streaming=True )print (next (iter (dataset)))
数据集支持对列重命名。下面的代码将squad数据集中的context列重命名为text:
1 2 3 4 from datasets import load_dataset'squad' )'context' , 'text' )
数据集支持对列进行丢弃,在删除一个或多个列时,向remove_columns()函数提供要删除的列名。单个列删除传入列名,多个列删除传入列名的列表。下面的代码将squad数据集中的id列丢弃:
1 2 3 4 5 6 7 from datasets import load_dataset'squad' )'id' )'title' , 'text' ])
数据集支持新增列。下面的代码在squad数据集上新增一列test,内容全为字符串111:
1 2 3 4 5 from datasets import load_dataset'squad' )'train' ].add_column("test" , ['111' ] * squad['train' ].num_rows)
cast()函数对一个或多个列的特征类型进行转换。这个函数接受你的新特征作为其参数。
1 2 3 4 5 6 7 8 9 10 11 12 from datasets import load_dataset'squad' )'train' ].add_column("test" , ['111' ] * squad['train' ].num_rows)print (new_train_squad.features)"test" ] = Value("int64" )print (new_train_squad.features)
针对嵌套结构的数据类型,可使用flatten()函数将子字段提取到它们自己的独立列中。
1 2 3 4 5 from datasets import load_dataset'squad' )'train' ].flatten()print (flatten_dataset)
输出结果为:
1 2 3 4 Dataset({'id' , 'title' , 'context' , 'question' , 'answers.text' , 'answers.answer_start' ],
数据合并(Concatenate Multiple Datasets)
如果独立的数据集有相同的列类型,那么它们可以被串联起来。用concatenate_datasets()来连接不同的数据集。
1 2 3 4 5 6 from datasets import concatenate_datasets, load_dataset'squad' )'squad_v2' )'train' ], squad_v2['train' ]])
filter()函数支持对数据集进行过滤,一般采用lambda函数实现。下面的代码对squad数据集中的训练集的question字段,过滤掉split后长度小于等于10的数据:
1 2 3 4 from datasets import load_dataset'squad' )'train' ].filter (lambda x: len (x["question" ].split()) > 10 )
输出结果如下:
1 2 3 4 Dataset({'id' , 'title' , 'context' , 'question' , 'answers' ],
使用sort()对列值根据其数值进行排序。下面的代码是对squad数据集中的训练集按照标题长度进行排序:
1 2 3 4 5 6 7 from datasets import load_dataset'squad' )'train' ].add_column("title_length" , [len (_) for _ in squad['train' ]['title' ]])"title_length" )
set_format()函数改变了一个列的格式,使之与一些常见的数据格式兼容。在类型参数中指定你想要的输出和你想要格式化的列。格式化是即时应用的。支持的数据格式有:None,
numpy, torch, tensorflow, pandas, arrow,
如果选择None,就会返回python对象。
下面的代码将新增标题长度列,并将其转化为numpy格式:
1 2 3 4 5 6 7 from datasets import load_dataset'squad' )'train' ].add_column("title_length" , [len (_) for _ in squad['train' ]['title' ]])type ="numpy" , columns=["title_length" ])
HuggingFace
Hub 上提供了一系列的评估指标(metrics),前20个指标如下:
1 2 3 from datasets import list_metricsprint (', ' .join(metric for metric in metrics_list[:20 ]))
输出结果如下:
1 accuracy, bertscore, bleu, bleurt, brier_score, cer, character, charcut_mt, chrf, code_eval, comet, competition_math, coval, cuad, exact_match, f1, frugalscore, glue, google_bleu, indic_glue
从Hub中加载一个指标,使用 datasets.load_metric()squad数据集的指标:
1 2 from datasets import load_metric'squad' )
输出结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Metric(name: "squad" , features: {'predictions' : {'id' : Value(dtype='string' , id =None), 'prediction_text' : Value(dtype='string' , id =None)}, 'references' : {'id' : Value(dtype='string' , id =None), 'answers' : Sequence(feature={'text' : Value(dtype='string' , id =None), 'answer_start' : Value(dtype='int32' , id =None)}, length=-1, id =None)}}, usage: "" " Computes SQuAD scores (F1 and EM). Args: predictions: List of question-answers dictionaries with the following key-values: - 'id': id of the question-answer pair as given in the references (see below) - 'prediction_text': the text of the answer references: List of question-answers dictionaries with the following key-values: - 'id': id of the question-answer pair (see above), - 'answers': a Dict in the SQuAD dataset format { 'text': list of possible texts for the answer, as a list of strings 'answer_start': list of start positions for the answer, as a list of ints } Note that answer_start values are not taken into account to compute the metric. Returns: 'exact_match': Exact match (the normalized answer exactly match the gold answer) 'f1': The F-score of predicted tokens versus the gold answer Examples: >>> predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22'}] >>> references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}] >>> squad_metric = datasets.load_metric(" squad") >>> results = squad_metric.compute(predictions=predictions, references=references) >>> print(results) {'exact_match': 100.0, 'f1': 100.0} " "" , stored examples: 0)
load_metric还支持分布式计算,本文不再详细讲述。
load_metric现在已经是老版本了,新版本将用evaluate模块代替,访问网址为:https://github.com/huggingface/evaluate 。
map就是映射,它接收一个函数,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset。常见的map函数的应用是对文本进行tokenize:
1 2 3 4 5 6 7 8 9 10 11 12 from datasets import load_datasetfrom transformers import AutoTokenizer'squad' )'bert-base-cased' def tokenize_function (sample ):return tokenizer(sample['context' ], truncation=True , max_length=256 )map (tokenize_function, batched=True )
输出结果如下:
1 2 3 4 5 6 7 8 9 10 DatasetDict({'id' , 'title' , 'context' , 'question' , 'answers' , 'input_ids' , 'token_type_ids' , 'attention_mask' ],'id' , 'title' , 'context' , 'question' , 'answers' , 'input_ids' , 'token_type_ids' , 'attention_mask' ],
数据保存/加载(save to disk/ load from disk)
使用save_to_disk()来保存数据集,方便在以后重新使用它,使用
load_from_disk()函数重新加载数据集。我们将上面map后的tokenized_dataset数据集进行保存:
1 tokenized_dataset.save_to_disk("squad_tokenized" )
保存后的文件结构如下:
1 2 3 4 5 6 7 8 9 10 squad_tokenized/
加载数据的代码如下:
1 2 from datasets import load_from_disk"squad_tokenized" )
总结
本文可作为dataset库的入门,详细介绍了数据集的各种操作,这样方便后续进行模型训练。
参考文献
Datasets: https://www.huaxiaozhuan.com/%E5%B7%A5%E5%85%B7/huggingface_transformer/chapters/2_datasets.html
Huggingface详细入门介绍之dataset库:https://zhuanlan.zhihu.com/p/554678463
Stream: https://huggingface.co/docs/datasets/stream
HuggingFace教程 Datasets基本操作: Process: https://zhuanlan.zhihu.com/p/557032513
欢迎关注我的公众号
NLP奇幻之旅 ,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅 ”,笔者正在努力构建自己的技术社区。