NLP(六十)Baichuan-13B-Chat模型使用体验
2023年7月11日,百川智能正式发布参数量130亿的通用大语言模型Baichuan-13B-Base、对话模型Baichuan-13B-Chat及其INT4/INT8两个量化版本。
本文将介绍大模型BaiChuan-13B-Chat的使用体验,其HuggingFace网址为:https://huggingface.co/baichuan-inc/Baichuan-13B-Chat 。
BaiChuan-13B-Chat模型采用FastChat工具部署,部署方式与Baichuan-7B模型相同,关于部署的详细步骤,可参考文章:NLP(五十九)使用FastChat部署百川大模型
。
使用初体验
GPT3.5或者GPT4模型在中文问答上偶尔会出现“幻觉”问题,比如一些常识性的中文问题,在这方面,Baichuan-13B-Chat模型的表现较好。
我们考虑以下三个问题:
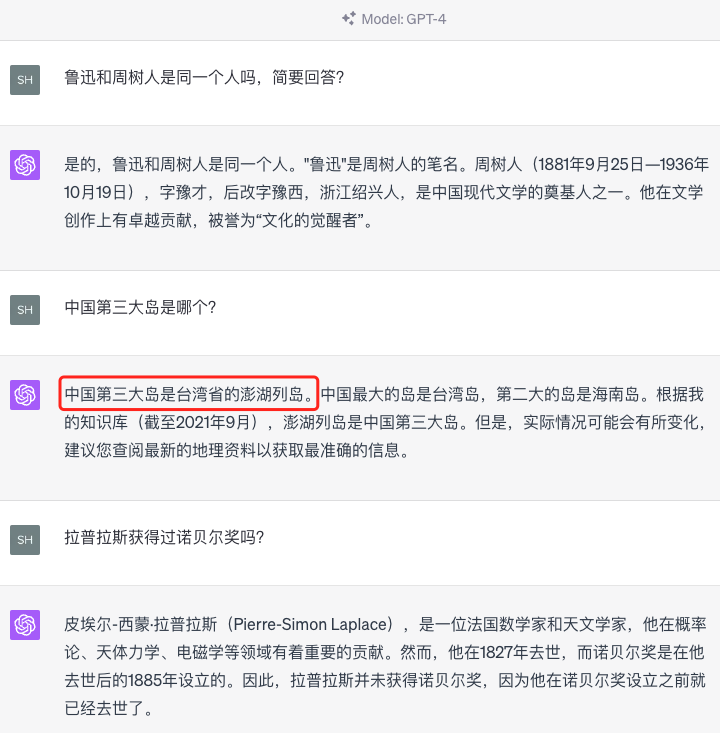
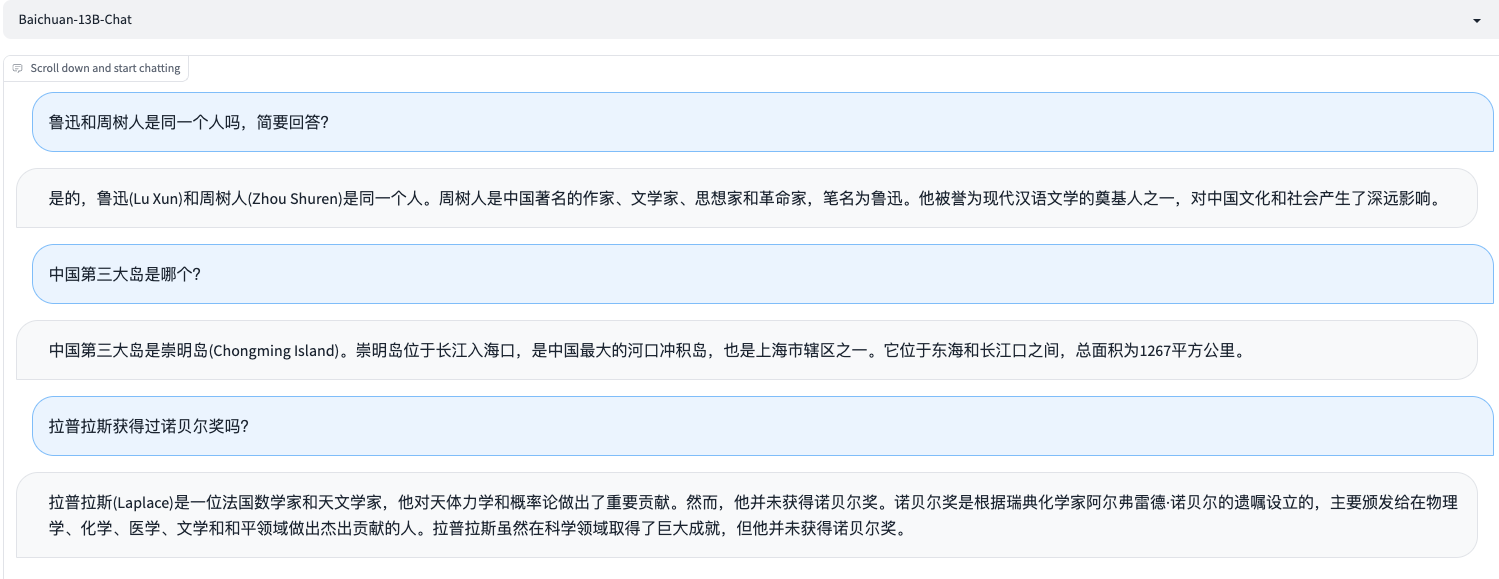
鲁迅和周树人是同一个人吗,简要回答?
中国第三大岛是哪个?
拉普拉斯获得过诺贝尔奖吗?
这是GPT3.5的回答:

这是GPT4的回复:
这是Baichuan-13B-Chat模型的回复:
向量嵌入(Embedding)
当我们完成Baichuan-13B-Chat模型的部署后,我们可以使用类似OpenAI的调用方式来调用该模型,以下是其在向量嵌入方面的表现。
我们选择五个初始文本:
- 唯心主义的对立面是什么
- 你好
- 上海的人口是多少?
- 北京的旅游景点有哪些?
- 中国的第一高楼
首先使用模型对以上文本进行向量嵌入(Embedding),向量维度为512维,范数为1(即已经进行规范化)。再使用新的文本进行向量嵌入,通过向量的余弦相似度获得五个文本中的最相似文本。实现Python如下:
1 | |
测试结果如下:
输入:苏州的旅游景点有哪些? 最相似文本:北京的旅游景点有哪些?
输入:柏拉图的哲学思想是什么? 最相似文本:唯心主义的对立面是什么
输入:北京的人口 最相似文本:上海的人口是多少?
文档阅读
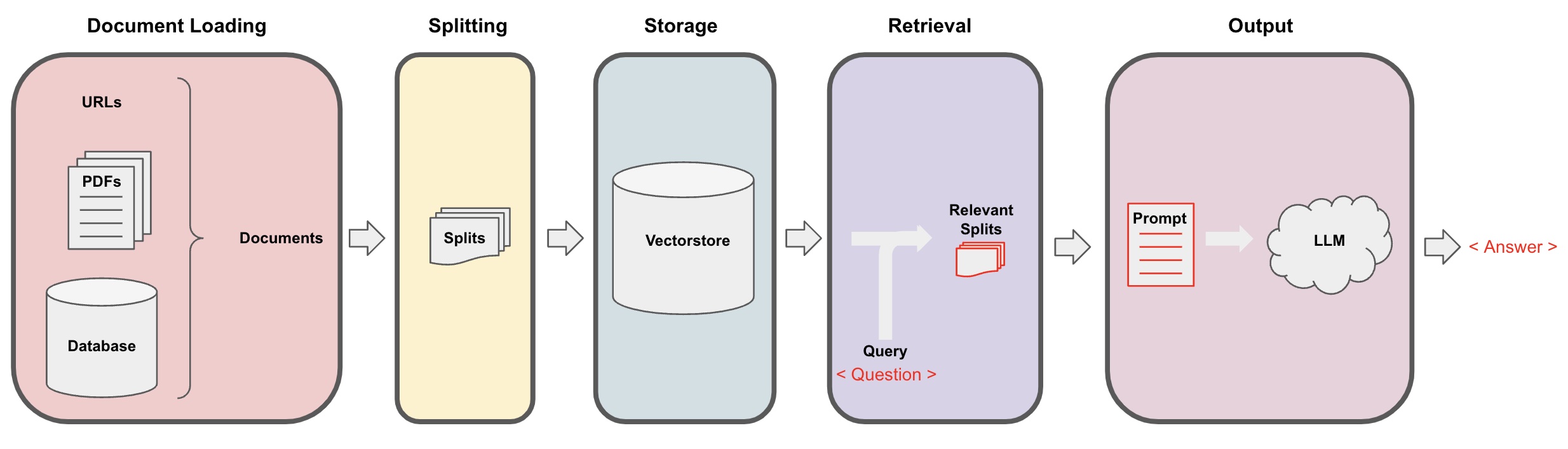
在向量嵌入的基础上,我们使用LangChain工具,将文档进行切分(split),之后转化为向量(Embedding),存入向量数据库(如Milvus),这样完成文档的储存。
对于用户的新问题,使用文本相似度进行向量数据库查询,找到最接近的K条文本,使用这K条文本和新问题,进行文档问答,类似于BERT时代的阅读理解(MRC)。
我们以中国载人登月工程百度百科中的文本为例,访问网址为:https://baike.baidu.com/item/%E4%B8%AD%E5%9B%BD%E8%BD%BD%E4%BA%BA%E7%99%BB%E6%9C%88%E5%B7%A5%E7%A8%8B/7147309
,将其储存为txt文件。
以此为例进行文档问答,流程图参考如下:
实现Python代码如下:
1 | |
测试结果如下:
问题:美国什么时候登上月球? 回答:美国在20世纪60年代和70年代通过“阿波罗”计划成功登上月球。
问题:中国预计在什么登上月球? 回答:中国预计在2025年实现航天员登月。目前,关于中国载人登月工程计划的时间,国内有三种说法:2020年、2025年和2030年。不过,这些时间表都是专家的观点和预测,国家尚未公布一个明确的时间表。
问题:嫦娥二号、嫦娥三号的总指挥是谁? 回答:嫦娥二号、嫦娥三号的总指挥是叶培建。
问题:神舟十六号载人飞行任务新闻发布会在哪里举行? 回答:神舟十六号载人飞行任务新闻发布会在酒泉卫星发射中心举行。
当然,上述的文档问答方案并不是很完善,仅仅使用向量嵌入有时无法召回相似文本,这样就会造成回答错误。
后续笔者将考虑ES + 向量加入的结合方式进行召回,同时支持更多类型的文本,不仅限于txt文件。
总结
本文主要介绍了Baichuan-13B-Chat模型使用体验,包括其与GPT系列模型在中文常识性问题上的测试,以及向量嵌入、文档问答等。
笔者使用下来的初步感受是,Baichuan-13B-Chat模型的问答效果还是不错的!
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
