NLP(十九)首次使用BERT的可视化指导
本文(部分内容)翻译自文章A Visual Guide to Using BERT for the First Time,其作者为Jay Alammar,访问网址为:http://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/ ,可以作为那些不熟悉BERT的读者首次阅读。文章中如有翻译不当之处,还请批评指正。

本文是关于如何使用BERT的变异版本来进行句子分类的简单教程。该例子足够简单,因此可以作为首次使用BERT的介绍,当然,它也包含了一些关键性的概念。
数据集:SST2
本文中使用的数据集为SST2,它包含了电影评论的句子,每一句带有一个标签,或者标注为正面情感(取值为1),或者标注为负面情感(取值为0)。

模型:句子情感分类
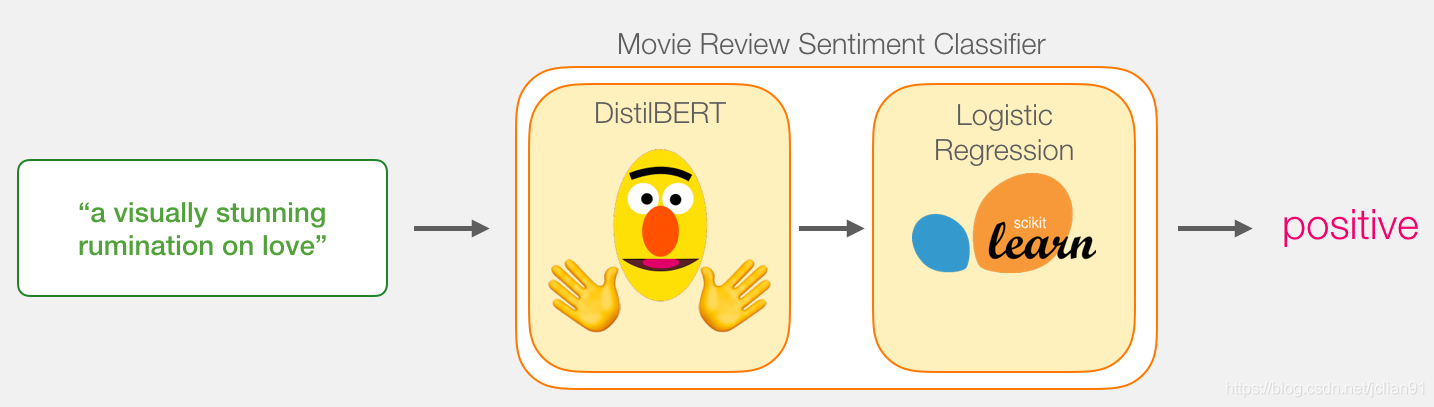
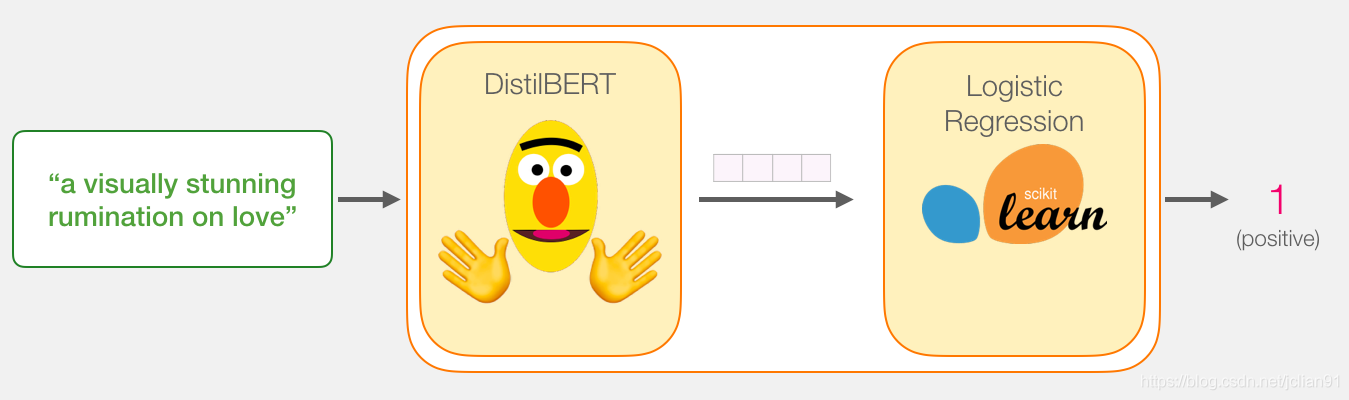
我们的目标是创建一个模型,它能够处理一个句子(就行我们数据集中的句子那样)并且输出1(表明该句子具有正面情感)或者0(表明该句子具有负面情感)。我们设想它长这样:

事实上,该模型包含两个模型:
DistillBERT会处理句子并把它提取后的信息传递给下一个模型。DistillBERT是BERT的变异版本,由HuggingFace小组开发和开源。它是BERT的更轻量、更快速的版本,同时它的表现基本与BERT相近。- 下一个模型,从scikit
learn中导入的一个基本的
逻辑回归模型(Logistic Regression model),它会利用DistillBERT的处理结果,然后将句子进行分类成正面情感或者负面情感(分别为1或者0)。
在两个模型之间传递的数据为1个768维的向量。我们可以把这个向量理解为这个句子的嵌入向量(Embedding Vector),用于分类。
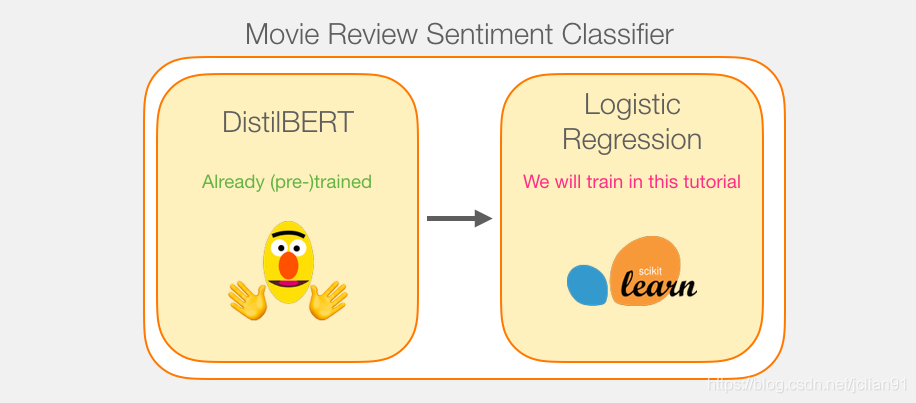
模型训练
尽管我们用了两个模型,但是我们只会训练逻辑回归模型。对于DistillBERT,我们会使用已经预训练好的英语模型。该模型,既不会被训练也不会做微调(fine-tuned),直接进行句子分类。这是因为,我们可以从BERT中获得句子分类的能力。这尤其适合BERT输出的第一个位置(跟[CLS]标志相关)。我相信这是由于BERT的第二个训练模型——下一句分类(Next sentence classification)。该模型的目标在于封装句子级别的语料进行训练,并输出第一个位置。transformers库已经提供了DistillBERT的操作,作为其预训练模型版本。
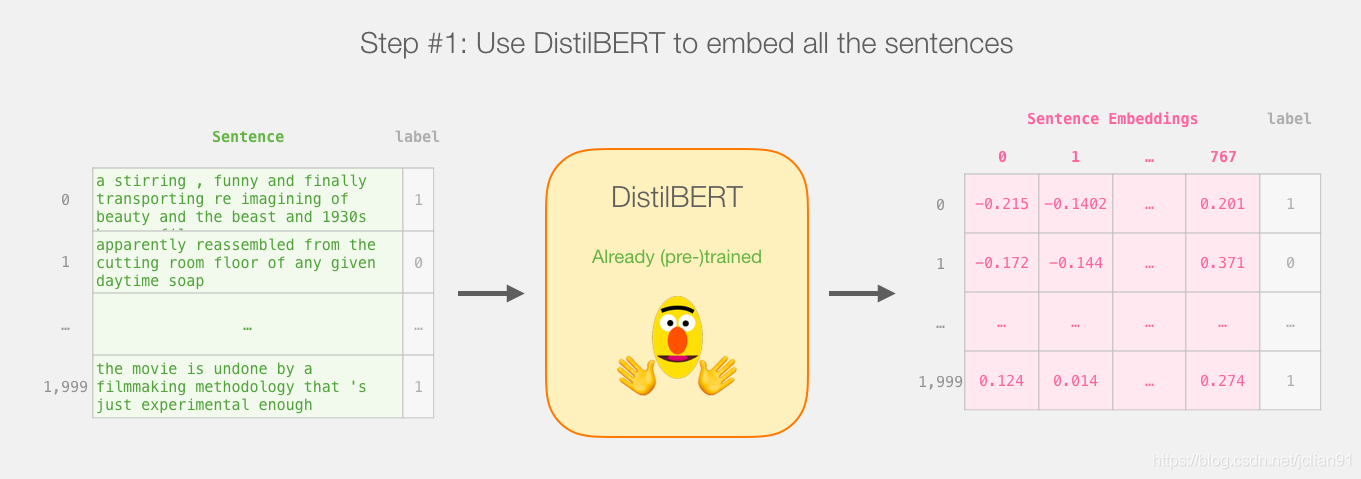
教程总览
以下是该教程的计划安排。首先我们会使用DistillBERT来产生2000个句子的句子向量。
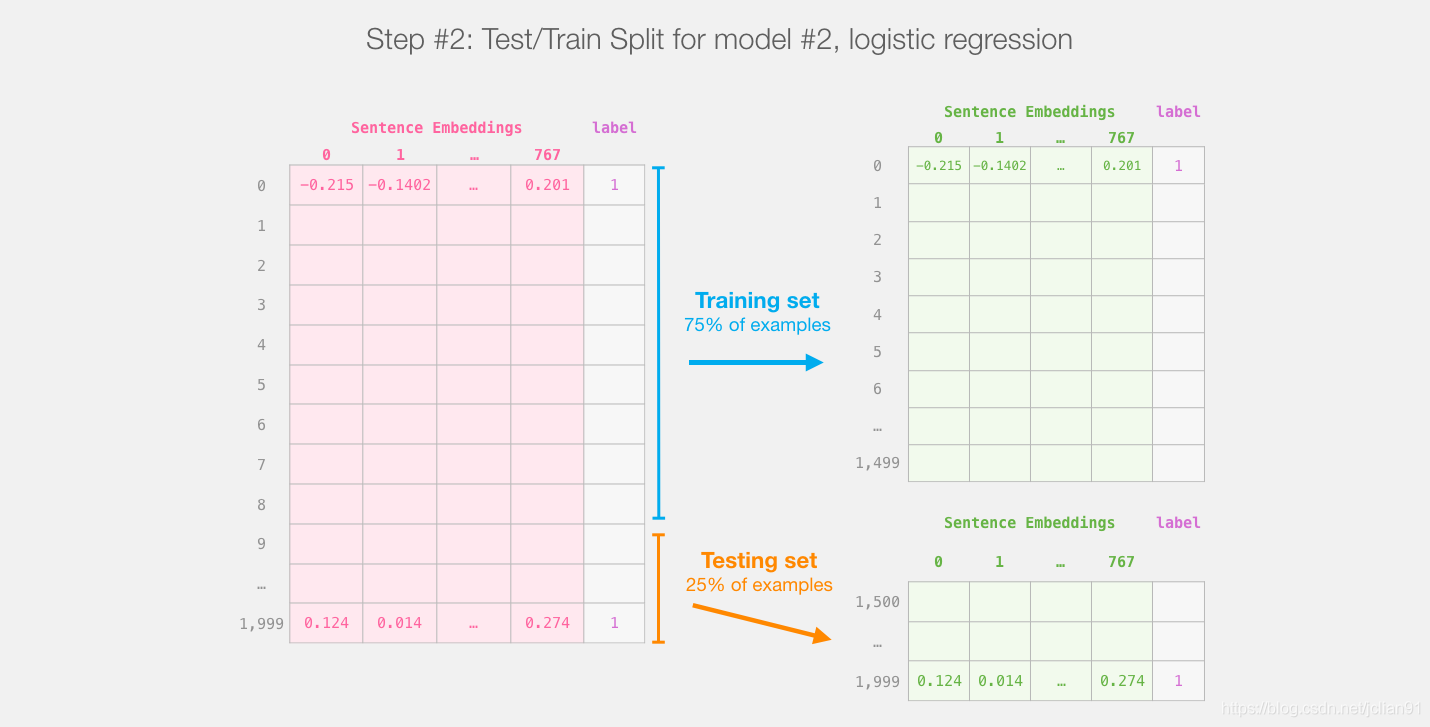
这一步之后我们不会接触DistillBERT。接下去只是Scikit
Learn的操作。我们将数据集分为训练集和测试集。
接下来我们在训练集上使用逻辑回归模型进行训练。
单次预测如何计算
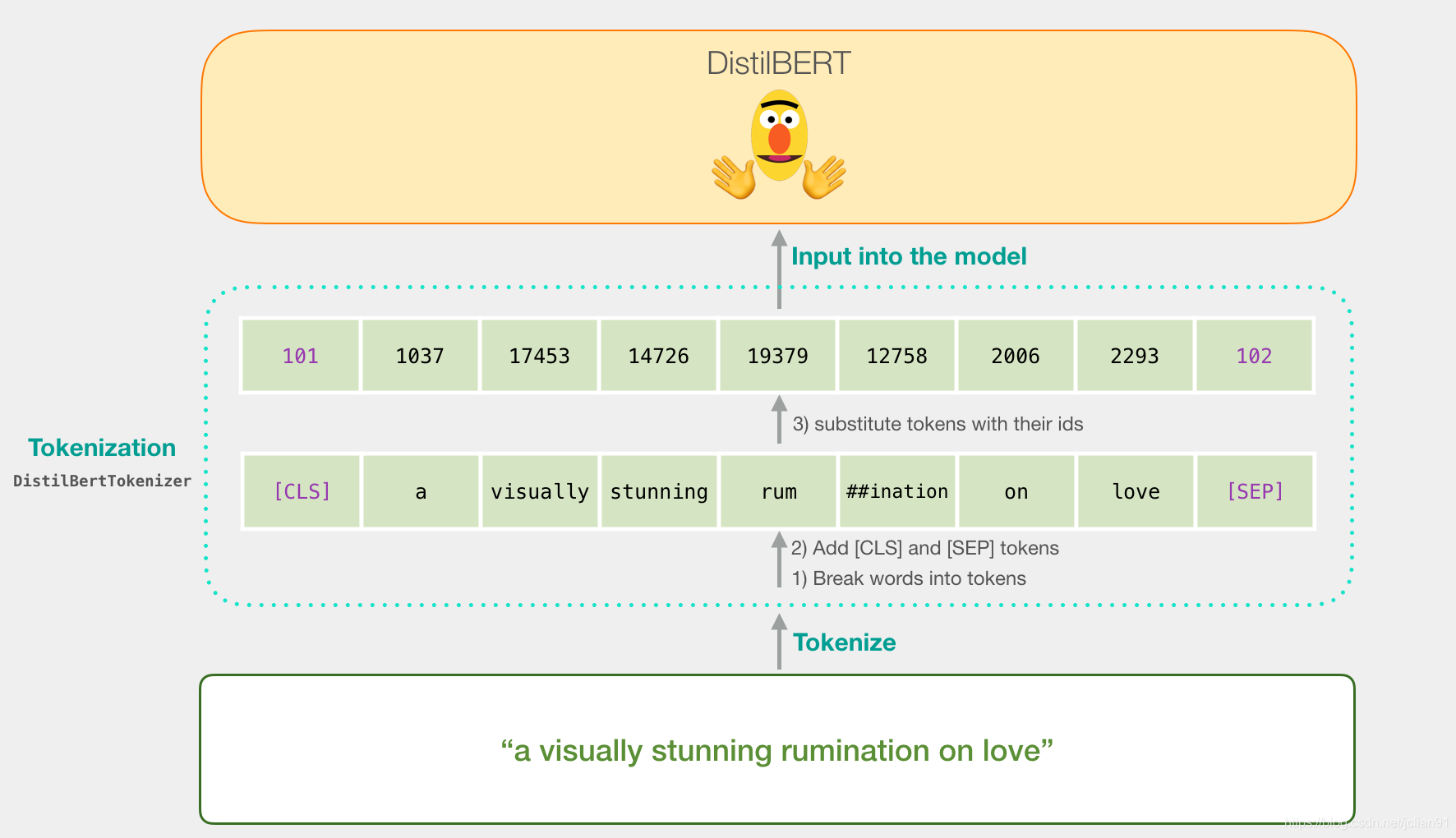
在我们讲解代码和解释如何训练模型之前,让我们看一下已预训练好的模型如何进行预测。 我们尝试着预测句子“a visually stunning rumination on love”。第一步是使用BERT tokenizer 将句子划分成tokens。然后加上句子分类的特殊tokens([CLS]在开始位置,[SEP]在句子结尾)。

第三步是通过已预训练好的模型的嵌入表(embedding
table)将每一个tokens映射成各自的id。这一步可以参考word embedding,参考阅读文章The Illustrated
Word2vec。

我们注意到,tokenizer仅需要一行代码就能完成以上步骤。 1
tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)DistilBERT可以处理的格式了。
如果你已经读过Illustrated
BERT,那么这一步的可视化如下:
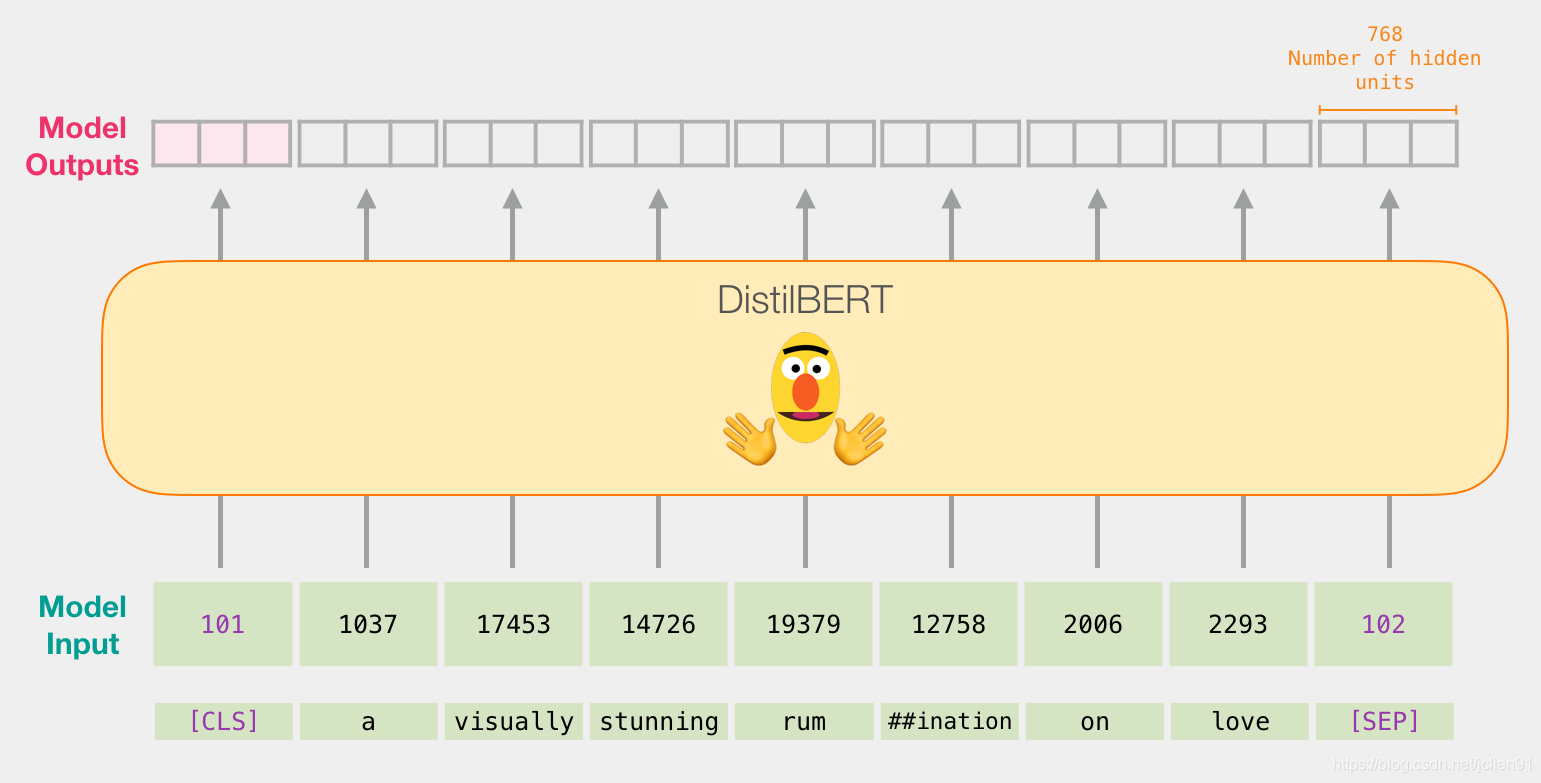
DistilBERT处理流程
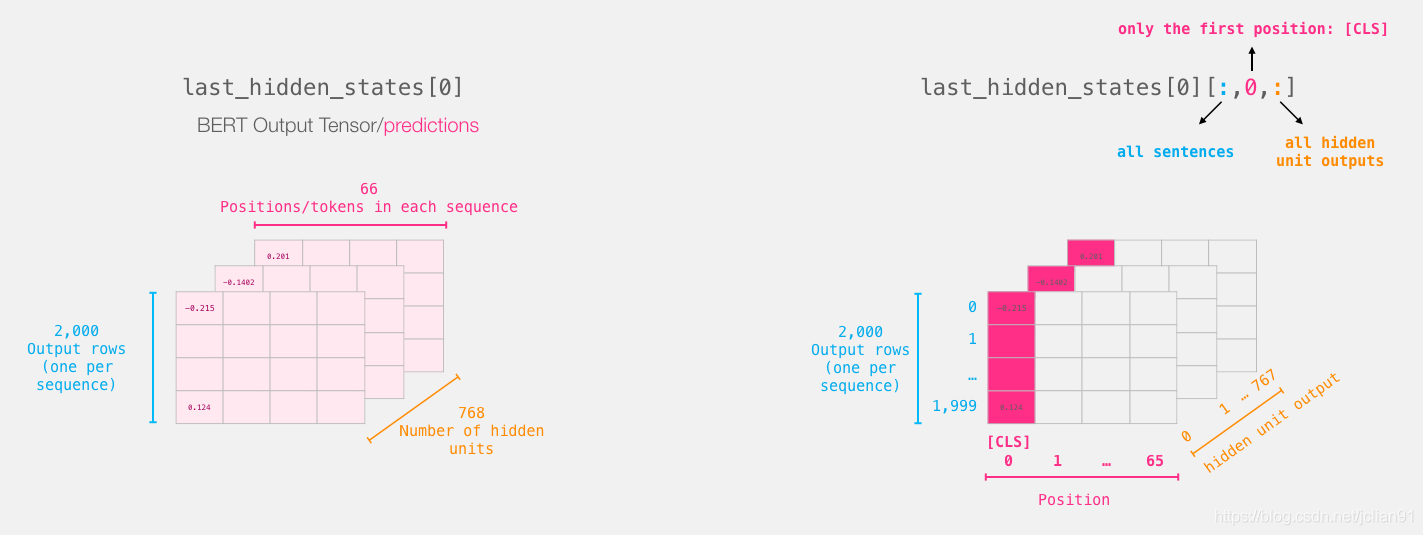
DistilBERT处理输入向量的流程类似于BERT。输出是每一个token对应一个向量。每个向量由768个浮点型数字组成。
因为这是一个句子分类任务,故我们忽略其他向量而只取第一个向量(跟[CLS]相关的那个)。这个向量我们会作为逻辑回归模型的输入。
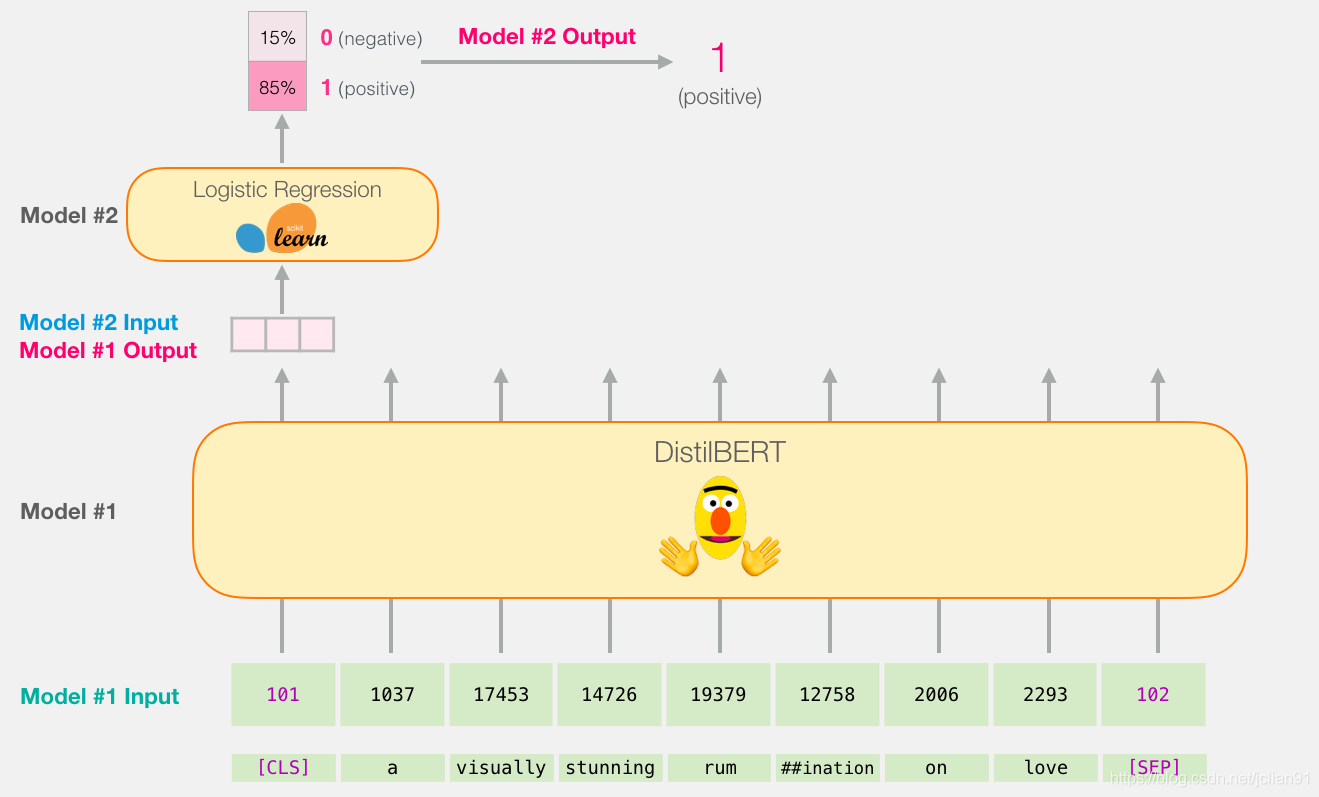
从这里开始,就是逻辑回归模型的事儿了,它负责将输入的向量进行分类。我们设想一个预测的流程长这样:
代码
文章中用到的数据集下载网址为:https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv。下载DistillBERT模型文件,网址为:https://www.kaggle.com/abhishek/distilbertbaseuncased
。
原文中这部分的代码讲解比较多,我这边忽略过去了,笔者想按自己的思路来处理,因此这部分内容会有调整。完整的思路如下:
下载数据集和模型文件,与代码放在同一目录下。建立jupyter脚本,先载入必要的模块:

接着我们利用pandas读取训练集数据,并统计标签值的频数:

读取DistillBERT模型文件并创建tokenizer:

通过tokenizer完成句子切分成tokens,并映射到id:

由于每个句子的长度可能会不同,因此需要对句子进行填充(Padding),保持每个句子的输入维度一致,句子填充的长度为该数据集中句子长度的最大值。

对句子进行填充后,然后再进行Masking。这是因为如果我们直接将padded传入BERT,这会造成一定的困扰。我们需要创建另一个变量,来告诉模型去mask之前的填充结果。这就是attention_mask的作用:

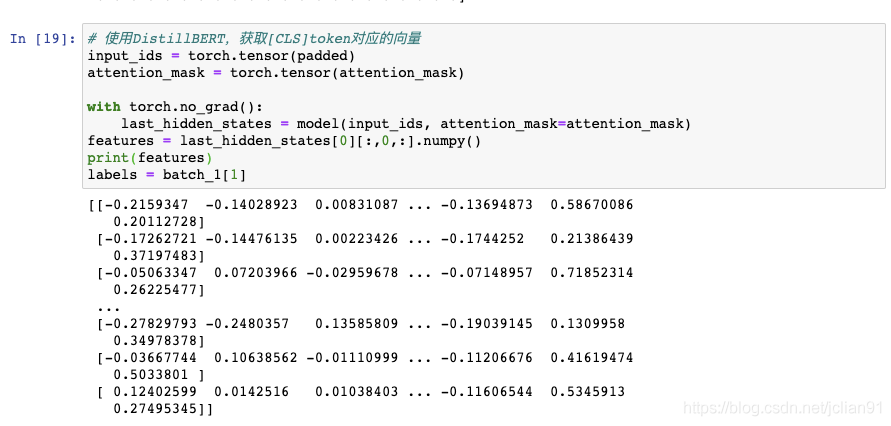
我们的输入已经准备完毕,接下来我们尝试着用DistillBERT来获取向量,也就是之前说的第一步。这一步的处理结果会返回last_hidden_states,而我们的分类模型只需要获取[CLS]这个token对应的输出向量。
可视化的操作说明如下图:
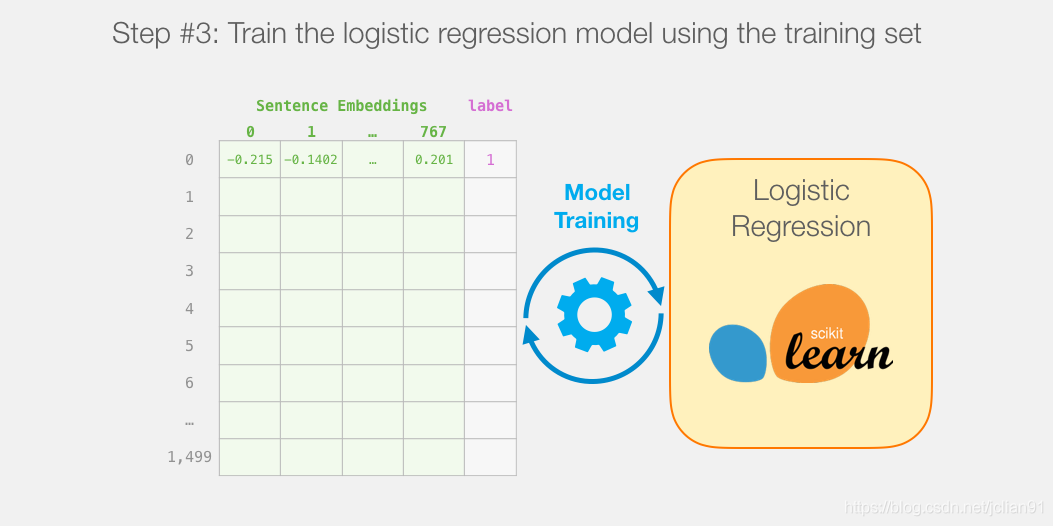
这样,我们就把之前的每一个句子映射成了1个768维的句子向量,然后就利用逻辑回归模型直接进行训练就可以了。

最后,我们来看一下这个模型在测试集上的效果:

总结
本文主要介绍了如何利用DistillBERT和已经封装好的transformers模块,结合逻辑回归模型对英文句子进行文本二分类。后续笔者还会研究在中文上的文本分类以及如何进行微调(Fine_tuning)。
本项目的Gitlab地址为:https://gitlab.com/jclian91/sentence_classify_using_distillBERT_LR,原文章作者的Github地址为https://github.com/jalammar/jalammar.github.io/blob/master/notebooks/bert/A_Visual_Notebook_to_Using_BERT_for_the_First_Time.ipynb 。
感谢大家阅读~
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
