NLP(十二)依存句法分析的可视化及图分析
依存句法分析的效果虽然没有像分词、NER的效果来的好,但也有其使用价值,在日常的工作中,我们免不了要和其打交道。笔者这几天一直在想如何分析依存句法分析的结果,一个重要的方面便是其可视化和它的图分析。
我们使用的NLP工具为jieba和LTP,其中jieba用于分词,LTP用于词性标注和句法分析,需要事件下载pos.model和parser.model文件。
本文使用的示例句子为:
2018年7月26日,华为创始人任正非向5G极化码(Polar码)之父埃尔达尔教授举行颁奖仪式,表彰其对于通信领域做出的贡献。
首先,让我们来看一下没有可视化效果之前的句法分析结果。Python代码如下:
1 | |
输出结果如下:
1 | |
我们得到了该句子的依存句法分析的结果,但是其可视化效果却不好。
我们使用Graphviz工具来得到上述依存句法分析的可视化结果,代码(接上述代码)如下:
1 | |
得到的依存句法分析的可视化图片如下:
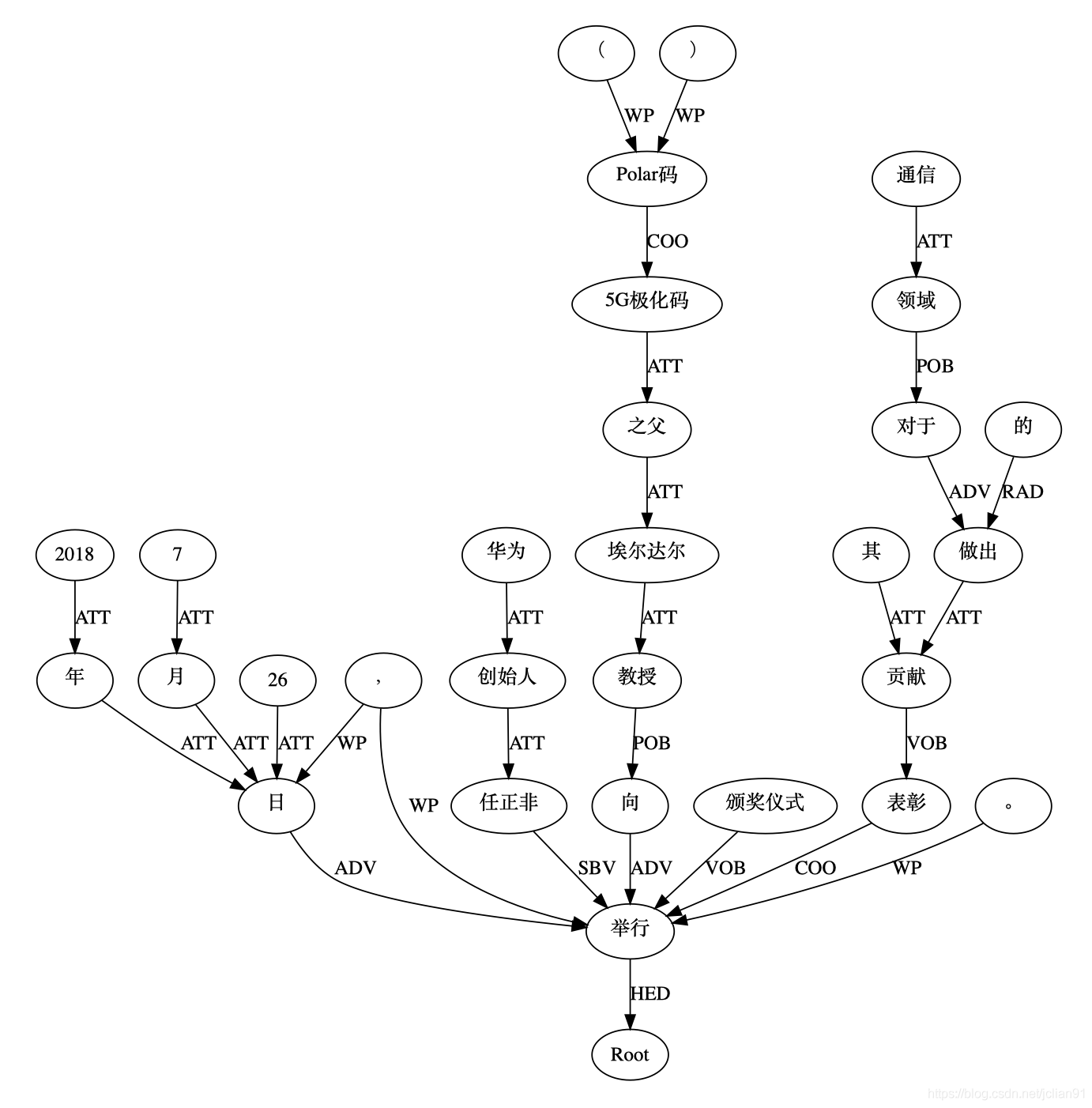
在这张图片中,我们有了对依存句法分析结果的直观感觉,效果也非常好,但是遗憾的是,我们并不能对上述可视化结果形成的图(Graph)进行图分析,因为Graphviz仅仅只是一个可视化工具。那么,我们该用什么样的工具来进行图分析呢?
答案就是NetworkX。以下是笔者对于NetworkX应用于依存句法分析的可视化和图分析的展示,其中图分析展示了两个节点之间的最短路径。示例的Python代码如下:
1 | |
得到的可视化图片如下:
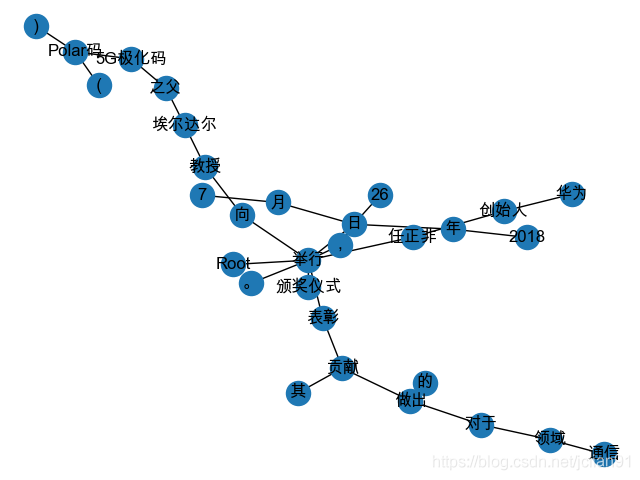
输出的结果如下:
1 | |
本次到此结束,希望这篇简短的文章能够给读者带来一些启发~
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。

NLP(十二)依存句法分析的可视化及图分析
https://percent4.github.io/NLP(十二)依存句法分析的可视化及图分析/