前沿
在文章NLP(十七)利用tensorflow-serving部署kashgari模型 中,笔者介绍了如何利用tensorflow-serving部署来部署深度模型模型,在那篇文章中,笔者利用kashgari模块实现了经典的BERT+Bi-LSTM+CRF模型结构,在标注了时间的文本语料(大约2000多个训练句子)中也达到了很好的识别效果,但是也存在着不足之处,那就是模型的预测时间过长,平均预测一个句子中的时间耗时约400毫秒,这种预测速度在生产环境或实际应用中是不能忍受的。
查看该模型的耗时原因,很大一部分原因在于BERT的调用。BERT是当下最火,知名度最高的预训练模型,虽然会使得模型的训练、预测耗时增加,但也是小样本语料下的最佳模型工具之一,因此,BERT在模型的架构上是不可缺少的。那么,该如何避免使用预训练模型带来的模型预测耗时过长的问题呢?
本文决定尝试使用ALBERT,来验证ALBERT在提升模型预测速度方面的应用,同时,也算是本人对于使用ALBERT的一次实战吧~
ALBERT简介
我们不妨花一些时间来简单地了解一下ALBERT。ALBERT是最近一周才开源的预训练模型,其Github的网址为:https://github.com/brightmart/albert_zh
,其论文可以参考网址:https://arxiv.org/pdf/1909.11942.pdf 。
根据ALBERT的Github介绍,ALBERT在海量中文语料上进行了预训练,模型的参数更少,效果更好。以albert_tiny_zh为例,其文件大小16M、参数为1.8M,模型大小仅为BERT的1/25,效果仅比BERT略差或者在某些NLP任务上更好。在本文的预训练模型中,将采用albert_tiny_zh。
利用ALBERT训练时间识别模型
我们以Github中的bertNER为本次项目的代码模板,在该项目中,实现的模型为BERT+Bi-LSTM+CRF,我们将BERT替换为ALBERT,也就是说笔者的项目中模型为ALBERT+Bi-LSTM+CRF,同时替换bert文件夹的代码为alert_zh,替换预训练模型文件夹chinese_L-12_H-768_A-12(BERT中文预训练模型文件)为albert_tiny。当然,也需要修改一部分的项目源代码,来适应ALBERT的模型训练。
数据集采用笔者自己标注的时间语料,即标注了时间的句子,大概2000+句子,其中75%作为训练集(time.train文件),10%作为验证集(time.dev文件),15%作为测试集(time.test文件)。在这里笔者不打算给出具体的Python代码,因为工程比较复杂,有兴趣的额读者可以去查看该项目的Github地址:https://github.com/percent4/ALBERT_4_Time_Recognition
。
一些模型的参数可以如下:
time.dev
81.41%
84.95%
83.14%
time.test
83.03%
86.38%
84.67%
接着笔者利用训练好的模型,用tornado封装了一个模型预测的HTTP服务,具体的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import osimport jsonimport timeimport pickleimport tracebackimport tornado.httpserverimport tornado.ioloopimport tornado.optionsimport tornado.webfrom tornado.options import define, optionsimport tensorflow as tffrom utils import create_model, get_loggerfrom model import Modelfrom loader import input_from_linefrom train import FLAGS, load_config, train"port" , default=12306 , help ="run on the given port" , type =int )False with open (FLAGS.map_file, "rb" ) as f:class ResultHandler (tornado.web.RequestHandler):def post (self ):'event' )False ))def main ():r'/subj_extract' , ResultHandler)
模型预测提速了吗?
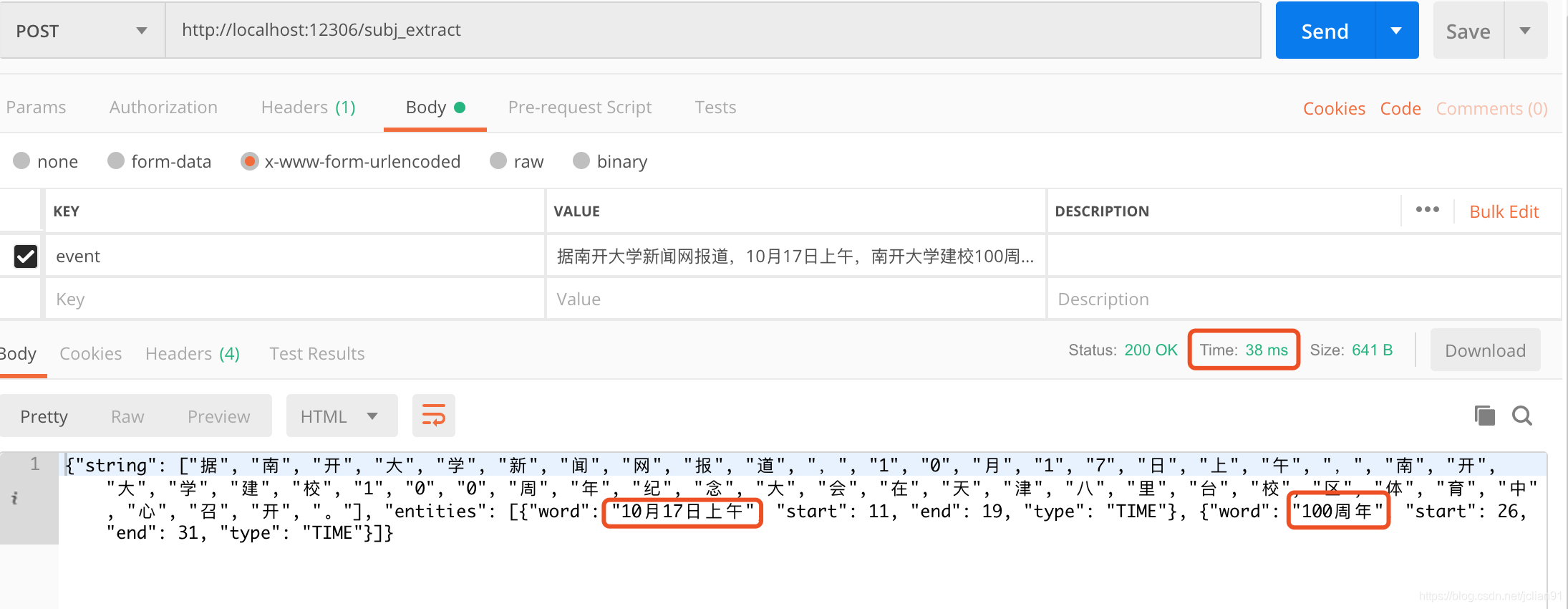
将模型预测封装成HTTP服务后,我们利用Postman来测试模型预测的效果和时间,如下图所示:
可以看到,模型预测的结果正确,且耗时仅为38ms。
接着我们尝试多测试几个句子的测试,测试代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import requestsimport jsonimport time'http://localhost:12306/subj_extract' '记者从国家发展改革委、商务部相关方面获悉,日前美方已决定对拟于10月1日实施的中国输美商品加征关税措施做出调整,中方支持相关企业从即日起按照市场化原则和WTO规则,自美采购一定数量大豆、猪肉等农产品,国务院关税税则委员会将对上述采购予以加征关税排除。' ,'据印度Zee新闻网站12日报道,亚洲新闻国际通讯社援引印度军方消息人士的话说,9月11日的对峙事件发生在靠近班公错北岸的实际控制线一带。' ,'儋州市决定,从9月开始,对城市低保、农村低保、特困供养人员、优抚对象、领取失业保险金人员、建档立卡未脱贫人口等低收入群体共3万多人,发放猪肉价格补贴,每人每月发放不低于100元补贴,以后发放标准,将根据猪肉价波动情况进行动态调整。' ,'9月11日,华为心声社区发布美国经济学家托马斯.弗里德曼在《纽约时报》上的专栏内容,弗里德曼透露,在与华为创始人任正非最近一次采访中,任正非表示华为愿意与美国司法部展开话题不设限的讨论。' ,'造血干细胞移植治疗白血病技术已日益成熟,然而,通过该方法同时治愈艾滋病目前还是一道全球尚在攻克的难题。' ,'英国航空事故调查局(AAIB)近日披露,今年2月6日一趟由德国法兰克福飞往墨西哥坎昆的航班上,因飞行员打翻咖啡使操作面板冒烟,导致飞机折返迫降爱尔兰。' ,'当地时间周四(9月12日),印度尼西亚财政部长英卓华(Sri Mulyani Indrawati)明确表示:特朗普的推特是风险之一。' ,'华中科技大学9月12日通过其官方网站发布通报称,9月2日,我校一硕士研究生不幸坠楼身亡。' ,'微博用户@ooooviki 9月12日下午公布发生在自己身上的惊悚遭遇:一个自称网警、名叫郑洋的人利用职务之便,查到她的完备的个人信息,包括但不限于身份证号、家庭地址、电话号码、户籍变动情况等,要求她做他女朋友。' ,'今天,贵阳取消了汽车限购,成为目前全国实行限购政策的9个省市中,首个取消限购的城市。' ,'据悉,与全球同步,中国区此次将于9月13日于iPhone官方渠道和京东正式开启预售,京东成Apple中国区唯一官方授权预售渠道。' ,'根据央行公布的数据,截至2019年6月末,存款类金融机构住户部门短期消费贷款规模为9.11万亿元,2019年上半年该项净增3293.19亿元,上半年增量看起来并不乐观。' ,'9月11日,一段拍摄浙江万里学院学生食堂的视频走红网络,视频显示该学校食堂不仅在用餐区域设置了可以看电影、比赛的大屏幕,还推出了“一人食”餐位。' ,'当日,在北京举行的2019年国际篮联篮球世界杯半决赛中,西班牙队对阵澳大利亚队。' ,for text in texts:'event' : text.replace(' ' , '' )}if req.status_code == 200 :print ('原文:%s' % text)'entities' ]print ('抽取结果:%s' % str ([_['word' ] for _ in res]))print ('一共耗时:%ss.' % str (round (t2-t1, 4 )))
输出结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 原文:记者从国家发展改革委、商务部相关方面获悉,日前美方已决定对拟于10 月1 日实施的中国输美商品加征关税措施做出调整,中方支持相关企业从即日起按照市场化原则和WTO 规则,自美采购一定数量大豆、猪肉等农产品,国务院关税税则委员会将对上述采购予以加征关税排除。'日前' , '10月1日' ]Zee 新闻网站12 日报道,亚洲新闻国际通讯社援引印度军方消息人士的话说,9 月11 日的对峙事件发生在靠近班公错北岸的实际控制线一带。'12日' , '9月11日' ]9 月开始,对城市低保、农村低保、特困供养人员、优抚对象、领取失业保险金人员、建档立卡未脱贫人口等低收入群体共3 万多人,发放猪肉价格补贴,每人每月发放不低于100 元补贴,以后发放标准,将根据猪肉价波动情况进行动态调整。'9月' ]9 月11 日,华为心声社区发布美国经济学家托马斯.弗里德曼在《纽约时报》上的专栏内容,弗里德曼透露,在与华为创始人任正非最近一次采访中,任正非表示华为愿意与美国司法部展开话题不设限的讨论。'9月11日' ]AAIB )近日披露,今年2 月6 日一趟由德国法兰克福飞往墨西哥坎昆的航班上,因飞行员打翻咖啡使操作面板冒烟,导致飞机折返迫降爱尔兰。'近日' , '今年2月6日' ]9 月12 日),印度尼西亚财政部长英卓华(Sri Mulyani Indrawati )明确表示:特朗普的推特是风险之一。'当地时间周四(9月12日)' ]9 月12 日通过其官方网站发布通报称,9 月2 日,我校一硕士研究生不幸坠楼身亡。'9月12日' , '9月2日' ]9 月12 日下午公布发生在自己身上的惊悚遭遇:一个自称网警、名叫郑洋的人利用职务之便,查到她的完备的个人信息,包括但不限于身份证号、家庭地址、电话号码、户籍变动情况等,要求她做他女朋友。'9月12日下午' ]9 个省市中,首个取消限购的城市。'今天' , '目前' ]9 月13 日于iPhone官方渠道和京东正式开启预售,京东成Apple 中国区唯一官方授权预售渠道。'9月13日' ]2019 年6 月末,存款类金融机构住户部门短期消费贷款规模为9.11 万亿元,2019 年上半年该项净增3293.19 亿元,上半年增量看起来并不乐观。'2019年6月末' , '2019年上半年' , '上半年' ]9 月11 日,一段拍摄浙江万里学院学生食堂的视频走红网络,视频显示该学校食堂不仅在用餐区域设置了可以看电影、比赛的大屏幕,还推出了“一人食”餐位。'9月11日' ]2019 年国际篮联篮球世界杯半决赛中,西班牙队对阵澳大利亚队。'当日' , '2019年' ]0.5314 s.
可以看到,对于测试的14个句子,识别的准确率很高,且预测耗时为531ms,平均每个话的预测时间不超过40ms。相比较而言,文章NLP(十七)利用tensorflow-serving部署kashgari模型 中的模型,该模型的预测时间为每句话1秒多,模型预测的速度为带ALBERT模型的25倍多。
因此,ALBERT模型确实提升了模型预测的时间,而且效果非常显著。
总结
由于ALBERT开源不到一周,而且笔者的学识、才能有限,因此,在代码方面可能会存在不足。但是,作为一次使用ALBERT的历经,希望能够与大家分享。
本文绝不是上述项目代码的抄袭和堆砌,该项目融入了笔者自己的思考,希望不要被误解为是抄袭。笔者使用上述的bertNER和ALBERT,只是为了验证ALBERT在模型预测耗时方面的提速效果,而事实是,ALBERT确实给我带来了很大惊喜,感受源代码作者们~
最后,附上本文中笔者项目的Github地址:https://github.com/percent4/ALBERT_4_Time_Recognition
。
众里寻他千百度。蓦然回首,那人却在,灯火阑珊处。
参考文献
超小型BERT中文版横空出世!模型只有16M,训练速度提升10倍:https://mp.weixin.qq.com/s/eVlNpejrxdE4ctDTBM-fiA
ALBERT的Github地址:https://github.com/brightmart/albert_zh
bertNER项目的Github地址:https://github.com/yumath/bertNER
NLP(十七)利用tensorflow-serving部署kashgari模型:
https://www.cnblogs.com/jclian91/p/11526547.html
欢迎关注我的公众号
NLP奇幻之旅 ,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅 ”,笔者正在努力构建自己的技术社区。