NLP(四十三)模型调参技巧之Warmup and Decay
Warmup and Decay是深度学习中模型调参的常用trick。本文将简单介绍Warmup and Decay以及如何在keras_bert中使用它们。
什么是warmup and decay?
Warmup and Decay是模型训练过程中,一种学习率(learning rate)的调整策略。
Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。
同理,Decay是学习率衰减方法,它指定在训练到一定epoches或者steps后,按照线性或者余弦函数等方式,将学习率降低至指定值。一般,使用Warmup and Decay,学习率会遵循从小到大,再减小的规律。
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。而当模型训到一定阶段后(比如10个epoch),模型的分布就已经比较固定了,或者说能学到的新东西就比较少了。如果还沿用较大的学习率,就会破坏这种稳定性,用我们通常的话说,就是已经接近损失函数的局部最优值点了,为了靠近这个局部最优值点,我们就要慢慢来。
如何在keras_bert中使用Warmup and Decay?
在keras_bert中,提供了优化器AdamWarmup类,其参数定义如下:
1 | |
在这个类中,我们需要指定decay_steps,warmup_steps,learning_rate,min_lr,其含义为模型在训练warmup_steps后,将学习率逐渐增加至learning_rate,在训练decay_steps后,将学习率逐渐线性地降低至min_lr。
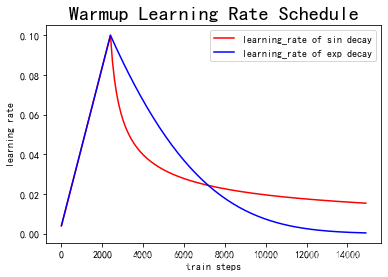
以下为Warmup预热学习率以及学习率预热完成后衰减(sin or exp decay)的曲线图:
在keras_bert的官方文档中,给出了使用Warmup and Decay的代码例子,如下:
1 | |
Warmup and Decay实战
笔者在文章NLP(三十四)使用keras-bert实现序列标注任务中,在使用keras-bert训练
序列标注模型时,学习率调整策略使用了ReduceLROnPlateau,代码如下:
1 | |
在三个数据集上的评估结果如下:
人民日报命名实体识别数据集:micro avg F1=0.9182
时间识别数据集:micro avg F1=0.8587
CLUENER细粒度实体识别数据集:micro avg F1=0.7603
我们将学习率调整策略修改为Warmup and Decay(模型其他参数不变,数据集不变),代码如下:
1 | |
使用该trick,在三个数据集上的评估结果如下:
- 人民日报命名实体识别数据集
| 学习率调整 | 预测1 | 预测2 | 预测3 | avg |
|---|---|---|---|---|
| Warmup | 0.9276 | 0.9217 | 0.9252 | 0.9248 |
- 时间识别数据集
| 学习率调整 | 预测1 | 预测2 | 预测3 | avg |
|---|---|---|---|---|
| Warmup | 0.8926 | 0.8934 | 0.8820 | 0.8893 |
- CLUENER细粒度实体识别数据集
| 学习率调整 | 预测1 | 预测2 | 预测3 | avg |
|---|---|---|---|---|
| Warmup | 0.7612 | 0.7629 | 0.7607 | 0.7616 |
可以看到,使用了Warmup and Decay,模型在不同的数据集上均有不同程度的效果提升。
本项目已经开源,代码地址为:https://github.com/percent4/keras_bert_sequence_labeling 。
本文到此结束,感谢大家的阅读~
2021年3月27日于上海浦东~
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
