NLP(四十二)人物关系分类的再次尝试
两周前的周末,笔者决定对人物关系分类进行再次尝试。
为什么说是再次尝试呢?因为笔者之前已经写过一篇文章NLP(二十一)人物关系抽取的一次实战,当时的标注数据大约2900条,使用的模型也比较简单,为BERT+Bi-GRU+Attention+FC结构,其中BERT用作特征提取,该模型在原有数据集上的F1为79%。
经过笔者一年断断续续的努力,现在的标注样本已经达到3900多条。鉴于笔者已做过BERT微调相关工作,当然希望在此数据集上进行再次尝试。
现有的人物关系数据集大约3900多条,分布如下图:
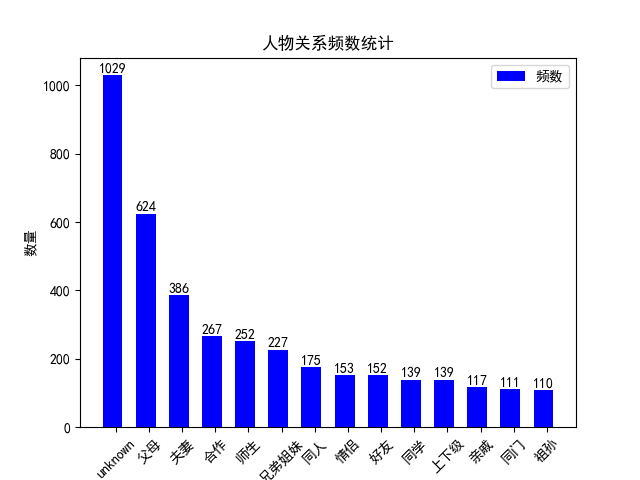
首先,我们只使用BERT分类模型,对输入数据进行格式改造,进行简单地尝试。
我们以样本亲戚 1837年6月20日,威廉四世辞世,他的侄女维多利亚即位。为例,其中亲戚为人物关系,威廉四世为实体1,维多利亚为实体2,来演示输入的文本格式。下面的部分我们统一使用chinese-RoBERTa-wwm-ext作为预训练模型,数据集分为训练集和测试集,比例为8:2。
第一种方法,我们与文章NLP(二十一)人物关系抽取的一次实战一样,在文本中将实体1替换为同样数量的#,实体2替换为同样数量的#,再将实体1、实体2、文本用$连接,输入格式为:威廉四世$维多利亚$1837年6月20日,####辞世,他的侄女####即位。。使用BERT+Bi-GRU+Attention+FC模型,在测试集上的评估结果如下:
| 模型名称 | 训练1 | 训练2 | 训练3 | 训练4 | 训练5 | Avg |
|---|---|---|---|---|---|---|
| BiGRU+Attention | 0.7726 | 0.7974 | 0.7935 | 0.7908 | 0.7941 | 0.7897 |
第二种方法,输入格式与第一种方法一致。使用文章NLP(三十五)使用keras-bert实现文本多分类任务中的多分类模型进行训练,在测试集上的评估结果如下:
| 模型名称 | 训练1 | 训练2 | 训练3 | 训练4 | 训练5 | Avg |
|---|---|---|---|---|---|---|
| Bert_cls | 0.8246 | 0.8110 | 0.8282 | 0.8448 | 0.8218 | 0.8260 |
可以看到,有了预训练模型的帮助,模型效果有了显著提升,F1值平均高了3.6%。
第三种方法,在文本中将实体用#包围,输入格式为:1837年6月20日,#威廉四世#辞世,他的侄女#维多利亚#即位。使用BERT_cls模型,在测试集上的评估结果如下:
| 模型名称 | 训练1 | 训练2 | 训练3 | 训练4 | 训练5 | Avg |
|---|---|---|---|---|---|---|
| Bert_cls2(实体用#围绕) | 0.8175 | 0.8259 | 0.8275 | 0.8335 | 0.8299 | 0.8269 |
可以看到,该输入格式与第二种方法相比,在模型效果上并没有太大的提升。
也许,是时候尝试新的模型了。
上周一晚上,笔者无意中看到一篇论文,名称为Enriching Pre-trained Language Model with Entity Information for Relation Classification,顾名思义为使用实体信息将预训练模型用于关系分类(RC)。其模型结构如下图:
该模型被称为R-BERT,模型结构在此不多介绍,后面有机会再介绍。在Github上有R-BERT模型的Torch框架实现方式,在Semeval 2010 Task 8 Dataset取得了不错的效果。
笔者将R-BERT用于人物关系分类数据集中,在测试集上的评估结果如下:
1 | |
该项目笔者已上传至Github,网址为:https://github.com/percent4/R-BERT_for_people_relation_extraction。
本周,笔者下定决心使用Keras实现R-BERT。第一天,无果。第二天,实现关键Keras层的突破,进行简单模型训练,发现离Torch版本的结果尚有一定差距。第三天,对照Torch版本,不断调整模型,加入Warmup机制,发现终于取得了与Torch版本一样的效果。在测试集上的评估结果如下:
1 | |
该项目已上传至Github,网址为:https://github.com/percent4/Keras_R_BERT。后面有机会笔者再详细介绍。
至此,笔者不仅用Keras实现了R-BERT,并且比最初的BERT+Bi-GRU+Attention+FC模型,在测试集上的F1值提升了6.3%。
实现模型的过程是痛苦的,笔者一度想放弃,但当模型成功复现后,那种快乐,是简单枯燥的工作中的一抹绚丽的阳光!这也是笔者第一次复现模型,虽然只是深度学习框架不同,但对我来说是极其重要的一步!
最近又发现一个很不错的关系分类的模型:Mul-BERT,但由于该模型的论文并未公布,Github也没有公开源码,笔者只好按自己的理解,简单地实现了近似Mul-BERT模型,已上传至Github,网址为:https://github.com/percent4/Keras_quasi_Mul_BERT。等论文出来后,再用Keras去复现Mul-BERT模型。
本文到此结束,感谢阅读~
2021年3月25日于上海浦东,此日阳光明媚~
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
